







【区域脑图论文笔记】BrainNetCNN:第一个专门为脑网络连接体数据设计的深度学习框架
信息概览与提炼

- 原名: BrainNetCNN: Convolutional neural networks for brain networks; towards predicting neurodevelopment
- 论文链接: https://www.sciencedirect.com/science/article/abs/pii/S1053811916305237
- 代码链接:
- 来源: NeuroImage
- 任务: cognitive scores认知得分, motor scores运动得分, 图回归, 年龄预测
- year: 2017
- 数据格式: DTI(结构数据)
- 数据集: 早产儿-DTI-温哥华BC115(年龄:为24至32周PMA,数量168, 115名主体)
- 构图模式: 区域脑图,单模,同构图, 静态,全连接,有向,加权
- 方法关键词: edge-based, 图结构学习,CNN,区域脑图,单模态
- 主要贡献点总结: BrainNetCNN,这是第一个用于连接组数据的CNN回归器。设计了三种专门的卷积层类型,旨在利用加权大脑网络中固有的结构。
- 其他辅助信息:BrainNetCNN的官方网站:https://brainnetcnn.cs.sfu.ca/About.html,包括模型的简介和软件等
采用的数据与结果
数据集
-
文章源话
- 27 and 46 weeks gestational age
- The data for this study is from a cohort of infants born very preterm, between 24 and 32 weeks PMA (postmenstrual age), and imaged at BC Children’s Hospital in Vancouver, Canada.
- scans of 115 infants were used. Roughly half of the infants were scanned twice…for a total of 168 scans.
- Using a neonatal atlas of anatomical regions from the University of North Carolina (UNC) School of Medicine at Chapel Hill
- a weighted, undirected network was constructed from each scan
- 90 x 90 symmetric adjacency matrix with zeros along the diagonal and is scaled to [0,1]
-
早产儿/婴幼儿年龄概念【医学概念知识拓展】
- Gestational age (completed weeks): time elapsed between the first day of the last menstrual period and the day of delivery. If pregnancy was achieved using assisted reproductive technology, gestational age is calculated by adding 2 weeks to the conceptional age.
孕龄(完整周数):末次月经第一天与分娩日之间的时间。如果妊娠是通过辅助生殖技术实现的,孕龄的计算方法是在受孕年龄上加2周。 - Chronological age (days, weeks, months, or years): time elapsed from birth.
实足年龄(日、周、月或年):从出生开始经过的时间。 - Postmenstrual age (weeks): gestational age plus chronological age.
经后年龄(周):胎龄加实际年龄。 - Corrected age (weeks or months): chronological age reduced by the number of weeks born before 40 weeks of gestation; the term should be used only for children up to 3 years of age who were born preterm.
校正年龄(周或月):实际年龄减去妊娠40周前出生的周数;该术语仅适用于3岁以下早产的儿童。 - During the perinatal period neonatal hospital stay, “postmenstrual age” is preferred to describe the age of preterm infants. After the perinatal period, “corrected age” is the preferred term.
在围产期新生儿住院期间,首选“经后年龄”来描述早产儿的年龄。在围产期之后,“校正年龄”是首选术语。
- Gestational age (completed weeks): time elapsed between the first day of the last menstrual period and the day of delivery. If pregnancy was achieved using assisted reproductive technology, gestational age is calculated by adding 2 weeks to the conceptional age.
-
总结
- 主体数目:115
- 总图像数:168(约有一半的婴儿接受了两次扫描)
- 主体年龄信息:24-32周(早产儿)
- 模态类型:DTI
- 图谱:UNC
- 节点数:90
- 连接矩阵信息:对称,对角线为0,归一化
- 脑图:90节点,加权图,同构图,初始特征在边上,有向图(从代码和公式上来看)
结果概览一眼
这里先了解一下论文的总体结果(其他结果在下面的笔记)
- 实验设置:3折交叉验证
- 年龄任务:MAE为2.17周(或总年龄范围的11.1%),SDAE为1.59周。预测年龄和真实年龄之间的相关性为0.864。
- 文章源话:💡 Using E2Enet-sml , we were able to accurately predict PMA, with an MAE of 2.17 weeks (or 11.1% of the total age range) and an SDAE of 1.59 weeks. The correlation between predicted and ground-truth age was 0.864. FC90net model performed slightly worse than E2Enet-sml, achieving an MAE of 2.29 weeks, SDAE of 1.65 weeks and a correlation of 0.858. Similarly, the E2Nnet-sml model slightly underperformed E2Enet-sml, achieving an MAE of 2.377, SDAE of 1.72 and a correlation of 0.843.】
- 认知和运动评分任务:认知和运动评分的预测值和真实值之间的平均差异在统计学上与零无显著差异(p值分别为0.6817和0.9731),两者的MAR均小于11.6%
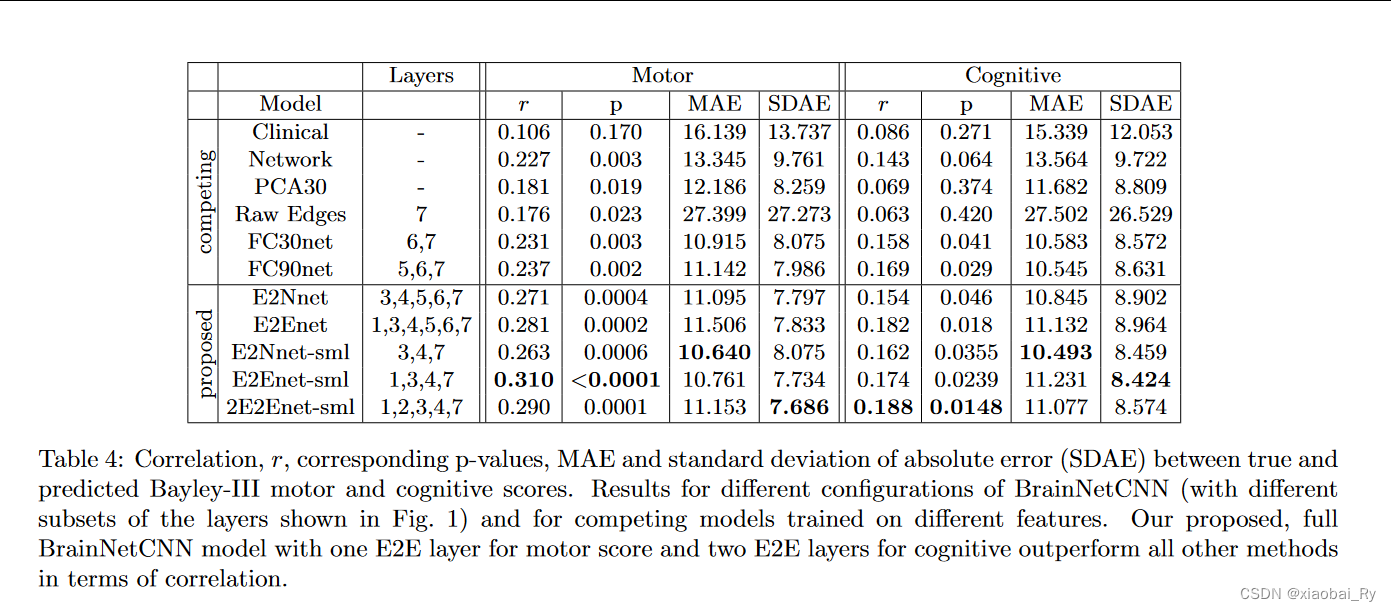
重点图与方法概览
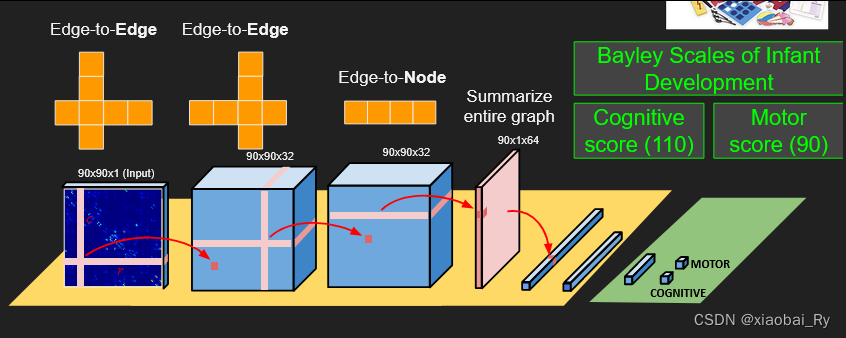
 上面是BrainNetCNN论文的主题框架图
上面是BrainNetCNN论文的主题框架图
从图1可以看出BrainNetCNN主要包括三个卷积层,也就是E2E,E2N和N2G:
- E2E层:Edge-to-edge Layer,也就是边到边层,也就是下图的a子图。
- E2N层:Edge-to-Node Layer,也就是边到节点层,也就是下图的b子图。
- N2G层:Node-to-Graph Layer,也就是节点到图层,也就是下图的c子图。

由这三个卷积层最终依次更新边的特征(也就是连接矩阵中的元素特征),节点的特征,和整个脑图的特征,最后得到脑图的嵌入。
核心与优劣总结
核心与其理解
- 核心:BrainNetCNN的核心在于它是第一个专门为脑网络连接体数据设计的深度学习框架(16/17年)。与传统的深度学习框架相比(BrainNetCNN是跟基于图像的CNN框架对比),BrainNetCNN的E2E,E2N,N2G层的设计更有利于脑拓扑局部结构的学习,更具可解释性。
- 核心思想的理解:本质上就是把连接矩阵的每个元素当成节点间边的连接,也就是加权的全连接图。因此,BrainNetCNN其实考虑了连接矩阵的含义。也就是矩阵的每个元素相当于边。对于脑科学的任务来说,最终就是为了获取脑图的嵌入(对于区域脑图类型来说)。所以,BrainNetCNN在边特征的基础上思考应该怎么去获取整个脑图的嵌入。在BrainNetCNN中,其采用先将边特征聚合到节点层(E2N),在将节点层的特征聚合到图层(N2G),以此得到整个脑图的嵌入。在上面的理解中就包括了E2N和N2G层。E2E层可以理解为获取更高维/有效的边特征。
优势总结
- 第一个专门为脑网络连接体数据设计的深度学习框架,考虑了连接矩阵的含义,而不是把脑影像单纯的当成图像或者把连接矩阵当成图像来看。
- 采用了模拟损伤实验
- 采用了SMOTE过采样的方法来缓解样本量少带来的问题
- 可视化(注意对于脑科学论文来说,可视化是比较重要且必要的)的结果:可视化的机构发现对于预测年龄重要的连接在整个脑网络中的分布良好;对于运动和认知分数相关的重要连接与相关脑区相关。
- 开源
不足总结
- 单一数据集,单一模态,数据样本量少(但其实这也是很多脑科学的挑战之处)。
- 没有和比较当时经典的图像模型相比(文中只对比了FC30/90这些,感觉至少应该对比一下CNN😂),其实还是性能上有待考究的。与图像模型相比的话,脑网络模型的优势在于可解释性。
- 一些数据处理的细节其实在文本并没有给出,需要从源码看一下
- 虽然考虑了脑的拓扑结构,但模型的可解释性有待进一步优化。
模型与实验
这里笔记部分就不记载论文相关的背景及相关工作等的介绍了,主要介绍的是模型与实验部分以及相关笔者觉得比较重要的可视化结果。下面将帮助友友们理解一下E2E,E2N和N2G层。
论文方法
根据上述的总结与概述,BrainNetCNN的核心在于E2E,E2N和N2G三个层。所以理解这三个层的思想及公式,其实就可以理解BrainNetCNN。通过理解思路加上代码,应该没有问题了。
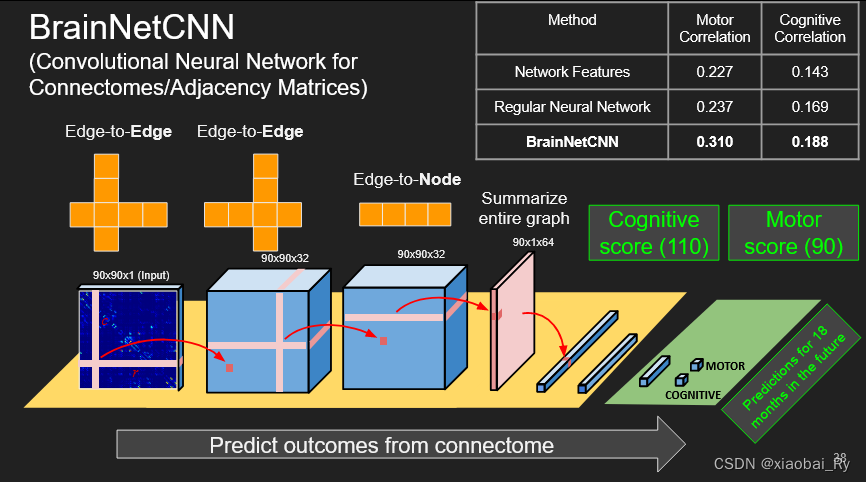
图来源于:Convolutional Neural Networks for Adjacency Matrices
PS:下面的图如果没有另外说明就是来源于Convolutional Neural Networks for Adjacency Matrices
E2E的理解
对应的论文公式:
 其中,
A
i
,
j
A_{i,j}
Ai,j为连接矩阵的第i行第j列的元素,也就是脑网路中节点i与节点j连接的边。比如像下图1这条边对应右边连接矩阵的A、B节点的矩阵元素。
其中,
A
i
,
j
A_{i,j}
Ai,j为连接矩阵的第i行第j列的元素,也就是脑网路中节点i与节点j连接的边。比如像下图1这条边对应右边连接矩阵的A、B节点的矩阵元素。
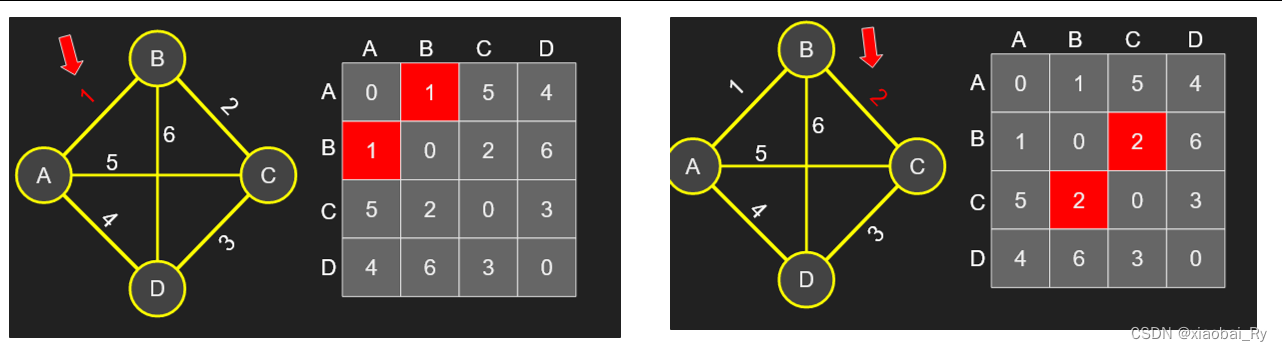
A i , k ∣ k ∈ ∣ Ω ∣ A_{i,k}|k \in|\Omega| Ai,k∣k∈∣Ω∣就相当于下面动图中黄十字横着的那一行, A k , j ∣ k ∈ ∣ Ω ∣ A_{k,j}|k \in|\Omega| Ak,j∣k∈∣Ω∣就相当于下面动图中黄十字横着的那一列。
下图为边到边(E2E)卷积层更新边的计算过程,也就是计算给定边的相邻边的加权响应。

(左)输入连接矩阵,其中黄色十字部分为卷积,(右)输出连接矩阵,黄色代表左黄色十字的响应。
比如对于A节点和C节点这条边,通过卷积与AC这条边直接连接的边(粉色部分)就可以得到红色部分对应的AC矩阵元素,也就是新的AC边的特征表示。而橙色就代表对应的学习权重,也就是卷积层。
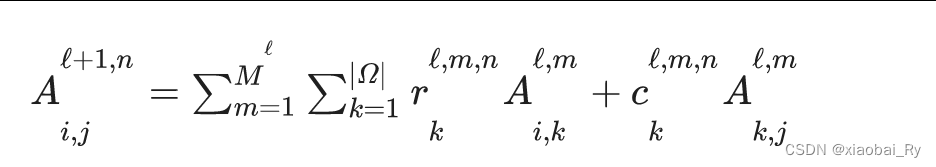 除此之外,可以看到公式里面对
A
i
,
k
∣
k
∈
∣
Ω
∣
A_{i,k}|k \in|\Omega|
Ai,k∣k∈∣Ω∣和
A
k
,
j
∣
k
∈
∣
Ω
∣
A_{k,j}|k \in|\Omega|
Ak,j∣k∈∣Ω∣使用的是不同的权重系数,因此,在BrainNetCNN中其把脑图看成一种有向图,也就是A节点到B节点和B节点到A节点的计算是不一致的。
除此之外,可以看到公式里面对
A
i
,
k
∣
k
∈
∣
Ω
∣
A_{i,k}|k \in|\Omega|
Ai,k∣k∈∣Ω∣和
A
k
,
j
∣
k
∈
∣
Ω
∣
A_{k,j}|k \in|\Omega|
Ak,j∣k∈∣Ω∣使用的是不同的权重系数,因此,在BrainNetCNN中其把脑图看成一种有向图,也就是A节点到B节点和B节点到A节点的计算是不一致的。
对应的Pytorch代码:
class E2EBlock(torch.nn.Module):
'''E2Eblock.'''
def __init__(self, in_planes, planes,example,bias=False):
super(E2EBlock, self).__init__()
self.d = example.size(3)
self.cnn1 = torch.nn.Conv2d(in_planes,planes,(1,self.d),bias=bias)
self.cnn2 = torch.nn.Conv2d(in_planes,planes,(self.d,1),bias=bias)
def forward(self, x):
a = self.cnn1(x)
b = self.cnn2(x)
return torch.cat([a]*self.d,3)+torch.cat([b]*self.d,2)
E2N的理解
对应的论文公式:
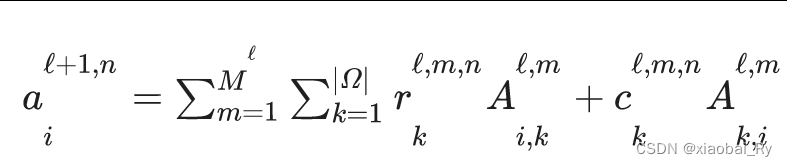 其中,
a
i
a_{i}
ai代表的其实就是节点 i。这里同样可以看到公式里面对
A
i
,
k
∣
k
∈
∣
Ω
∣
A_{i,k}|k \in|\Omega|
Ai,k∣k∈∣Ω∣和
A
k
,
j
∣
k
∈
∣
Ω
∣
A_{k,j}|k \in|\Omega|
Ak,j∣k∈∣Ω∣使用的是不同的权重系数,因此,在BrainNetCNN中其把脑图看成一种有向图。
其中,
a
i
a_{i}
ai代表的其实就是节点 i。这里同样可以看到公式里面对
A
i
,
k
∣
k
∈
∣
Ω
∣
A_{i,k}|k \in|\Omega|
Ai,k∣k∈∣Ω∣和
A
k
,
j
∣
k
∈
∣
Ω
∣
A_{k,j}|k \in|\Omega|
Ak,j∣k∈∣Ω∣使用的是不同的权重系数,因此,在BrainNetCNN中其把脑图看成一种有向图。
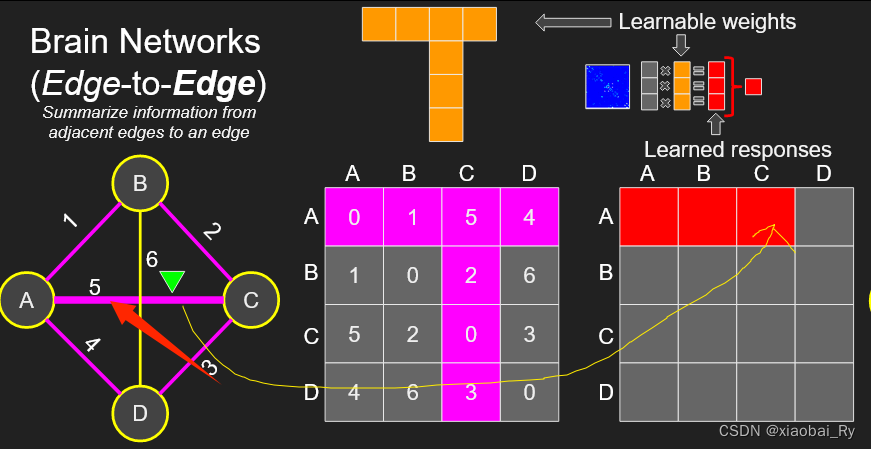
下面给出上面公式的动图计算过程:
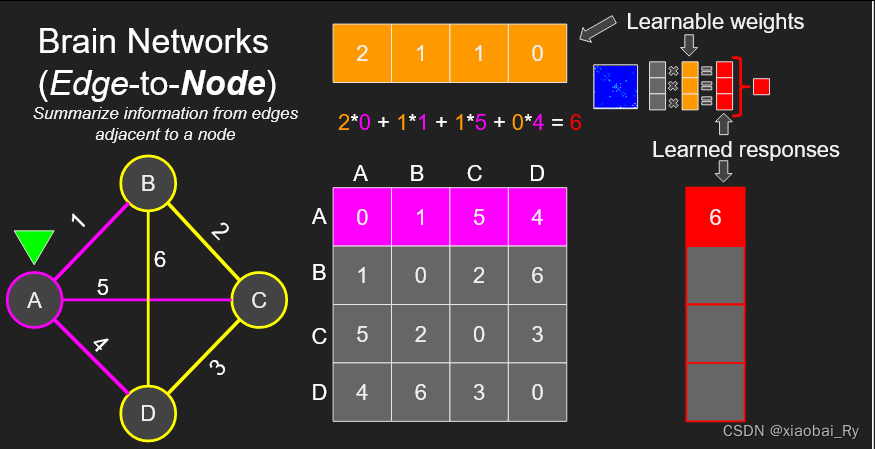
下图为边到点(E2N)卷积层更新边的计算过程,也就是计算给定节点的相邻边上的加权响应。

(左)输入连接矩阵,其中黄色十字部分为卷积,(右)输出节点特征(一个元素代表一个节点),黄色代表节点,也就是左黄色十字的响应。
如果动图还不能理解,可以看这里的例子:
比如对于A节点,通过卷积与A节点直接连接的边(粉色部分)就可以得到红色部分对应的新的A节点的特征表示。橙色就代表对应的学习权重,也就是卷积层。
对应的Pytorch代码:
self.E2N = torch.nn.Conv2d(64,1,(1,self.d))
N2G的理解
对应的论文公式:
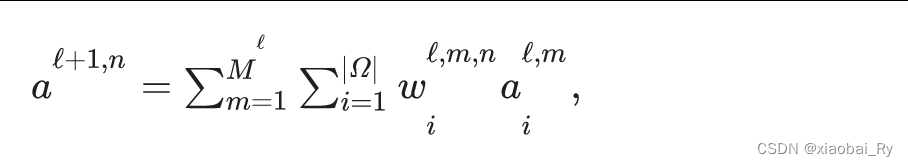 其中,
a
a
a代表的其实就是整个脑图的嵌入。
其中,
a
a
a代表的其实就是整个脑图的嵌入。
N2G层就像相当于GNN中的读出层,这里作者应用的是1D空间卷积。将所有节点特征加权卷积成整个图嵌入表示。
 简单粗略地理解:从上图来看就是把每个节点的特征维度映射为1维度,这样子就可以把所有的节点特征转化为1XN的脑嵌入了。
简单粗略地理解:从上图来看就是把每个节点的特征维度映射为1维度,这样子就可以把所有的节点特征转化为1XN的脑嵌入了。
对应的Pytorch代码:
self.N2G = torch.nn.Conv2d(1,256,(self.d,1))
三个卷积层设计的理解
整体上看来的话,E2E,E2N,N2G这三层卷积的计算操作其实为了减少计算量,通过上面的操作就可以减少整个卷积层的计算机维度。要知道这里减少计算量的操作还是有效的。尤其是对于像脑科学这种数据量相对少的情况。BrainNetCNN的图像数也就168。过复杂的卷积计算不利于模型的学习。
论文实验与讨论
这里笔者我不会过多的去讨论这里的实验结果,一个是文中对比的模型是FC,另外一个是对于研究者来说更多的可能是这篇论文的研究思路。
在结果概览那里已经可以看到模型的最后结果了,所以对于结果细节感兴趣的可以去看一下论文。下面只罗列一些笔者比较感兴趣的论文讨论结论。
这里面向的是早产儿数据。
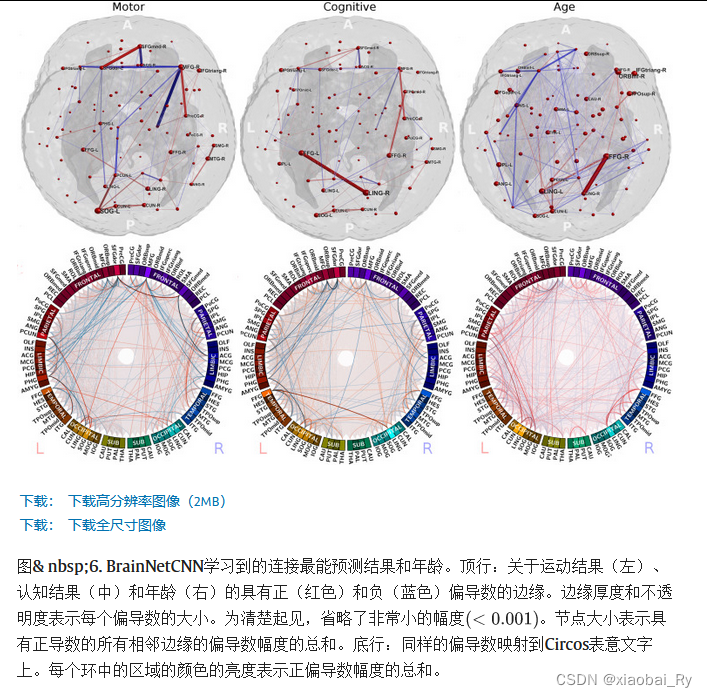 论文指出,许多来自右额中回(MFG)的大脑连接(边缘)被选为运动和认知评分的积极结果的预测。左侧楔前叶(PCUN)、梭状回(FFG)、上级额回(SFGdor)和右侧舌回(LING)也是两个评分的重要连接的突出枢纽。对于运动评分,两个上级额回之间的连接显得特别重要。相比之下,左FFG和右LING之间的连接被强调为对于认知分数比对于运动分数相对更重要。
论文指出,许多来自右额中回(MFG)的大脑连接(边缘)被选为运动和认知评分的积极结果的预测。左侧楔前叶(PCUN)、梭状回(FFG)、上级额回(SFGdor)和右侧舌回(LING)也是两个评分的重要连接的突出枢纽。对于运动评分,两个上级额回之间的连接显得特别重要。相比之下,左FFG和右LING之间的连接被强调为对于认知分数比对于运动分数相对更重要。
与发现对预测神经发育结果很重要的边缘集相比,发现对预测年龄很重要的边缘集在大脑网络中的分布要广泛得多(图6)。只有右LING和右FFG之间的联系似乎是一个特别强的预测因素。我们在下面讨论这些观察结果的可能解剖学原因。
与预测神经发育结果的边缘相比,发现对预测PMA重要的边缘在整个大脑网络中更为广泛。这是预期的,因为整个大脑在发育的早期阶段发育(即,许多连接随年龄变化)而运动或认知功能主要取决于特定的子网络。一个特别突出的对年龄有积极预测作用的联系是右LING和FFG之间的联系。这一结果与我们对健康早产儿发育的分析一致
总结与思考
BrainNetCNN的核心在于它是第一个专门为脑网络连接体数据设计的深度学习框架(16/17年)。与传统的深度学习框架相比(BrainNetCNN是跟基于图像的CNN框架对比),BrainNetCNN的E2E,E2N,N2G层的设计更有利于脑拓扑局部结构的学习,更具可解释性。
从BrainNetCNN的论文中可以看出它卷积层的设计其实还蛮有趣的,通过这样子的计算的确会大大减少计算量。
另外值得关注的一点就是它在E2E,E2N层的设计也可以看出它是把图当成有向图而不是无向图
另外这是脑科学考虑拓扑性的一个深度学习框架,有些思路是值得我们学习的:
- 根据脑网络的拓扑属性来设计框架
- 对于少数据量的情况下,应该如何控制模型的复杂度,使模型更能学习到数据本身的特征
- 对于脑科学领域来说,可解释性是必要的,进行相关的可视化分析也是必要的。
- 另外BrainNetCNN与后面BrainGNN系列的模型不同,它关注在于边上,也就是连接上,这对于功能数据来说是比较重要的。因为22年几篇Nature的文章之处信息交流才是重点,信息交流其实就可以看成边。但从GNN角度出发,就是丰富的特征组成有利于模型的学习。既然如此,也就是说节点特征+边特征>单一的特征。也就是最近两年来部分研究工作的做法了。
实现的一些细节
-
官方的一些实现细节:
模块 权重初始化 层数 bias FC-caffe weight——"xavier”(lr_mult=1, decay_mult=1);bias——“constant”(value=0,lr_mult=2, decay_mult=0) F.dropout(F.leaky_relu(self.dense1(out),negative_slope=0.33),p=0.5) torch.nn.Linear——>(256,128,30,2) 3 True E2E-CONV weight——"xavier”(lr_mult=1, decay_mult=1);bias——“constant”(value=0,lr_mult=2, decay_mult=0) F.leaky_relu(self.e2econv1(x),negative_slope=0.33) E2EBlock(1,32,example,bias=True)-E2EBlock(32,64,example,bias=True) 2 True E2N-CONV weight——"xavier”(lr_mult=1, decay_mult=1);bias——“constant”(value=0,lr_mult=2, decay_mult=0) F.leaky_relu(self.E2N(out),negative_slope=0.33) torch.nn.Conv2d(64,1,(1,self.d)) 1 True N2G-CONV weight——"xavier”(lr_mult=1, decay_mult=1);bias——“constant”(value=0,lr_mult=2, decay_mult=0) F.dropout(F.leaky_relu(self.N2G(out),negative_slope=0.33),p=0.5) torch.nn.Conv2d(1,256,(self.d,1)) 1 True Pytorch xavier_uniform_(self.u_conv.weight, gain=1.0), torch.nn.init.constant_(self.g_conv.bias, 0) F.dropout(F.leaky_relu(self.N2G(out),negative_slope=0.33),p=0.5)
out = F.leaky_relu(self.e2econv1(x),negative_slope=0.33)
out = F.leaky_relu(self.e2econv2(out),negative_slope=0.33)
out = F.leaky_relu(self.E2N(out),negative_slope=0.33)
out = F.dropout(F.leaky_relu(self.N2G(out),negative_slope=0.33),p=0.5)
out = out.view(out.size(0), -1)
out = F.dropout(F.leaky_relu(self.dense1(out),negative_slope=0.33),p=0.5)
out = F.dropout(F.leaky_relu(self.dense2(out),negative_slope=0.33),p=0.5)
out = F.leaky_relu(self.dense3(out),negative_slope=0.33)
权重初始化
- Caffe 代码
from caffe import layers as L
from caffe import params as P
def full_connect(bottom, num_output,
weight_filler=dict(type="xavier"),
bias_filler=dict(type="constant", value=0),
param=[dict(lr_mult=1, decay_mult=1), # weight learning rate parameters
dict(lr_mult=2, decay_mult=0)] # bias learning rate parameters
):
fc = L.InnerProduct(bottom, num_output=num_output,
weight_filler=weight_filler,
bias_filler=bias_filler,
param=param)
return fc
def e2n_conv(bottom, num_output, kernel_h, kernel_w,
weight_filler=dict(type="xavier"),
bias_filler=dict(type="constant", value=0),
param=[dict(lr_mult=1, decay_mult=1), # weight learning rate parameters
dict(lr_mult=2, decay_mult=0)] # bias learning rate parameters
):
"""Edge-to-Node convolution.
This is implemented only as a 1 x d rather than combined with d x 1,
since our tests did not show a consistent improvement with them combined.
"""
# 1xL convolution.
conv_1xd = L.Convolution(bottom, num_output=num_output, stride=1,
kernel_h=1, kernel_w=kernel_w,
weight_filler=weight_filler, bias_filler=bias_filler,
param=param)
return conv_1xd
def e2e_conv(bottom, num_output, kernel_h, kernel_w,
weight_filler=dict(type="xavier"),
bias_filler=dict(type="constant", value=0),
param=[dict(lr_mult=1, decay_mult=1), # weight learning rate parameters
dict(lr_mult=2, decay_mult=0)] # bias learning rate parameters
):
"""Implementation of the e2e filter."""
# kernel_h x 1 convolution.
conv_dx1 = L.Convolution(bottom, num_output=num_output, stride=1,
kernel_h=kernel_h, kernel_w=1,
weight_filler=weight_filler, bias_filler=bias_filler,
param=param)
# 1 x kernel_w convolution.
conv_1xd = L.Convolution(bottom, num_output=num_output, stride=1,
kernel_h=1, kernel_w=kernel_w,
weight_filler=weight_filler, bias_filler=bias_filler,
param=param)
# Concat all the responses together.
# For dx1, produce a dxd matrix.
concat_dx1_dxd = L.Concat(*[conv_dx1] * kernel_w, concat_param=dict(axis=2))
# For 1xd, produce a dxd matrix.
concat_1xd_dxd = L.Concat(*[conv_1xd] * kernel_h, concat_param=dict(axis=3))
# Sum the dxd matrices together element-wise.
sum_dxd = L.Eltwise(concat_dx1_dxd, concat_1xd_dxd, eltwise_param=dict(operation=P.Eltwise.SUM))
return sum_dxd
- Pytorch代码
class BrainNetCNN(torch.nn.Module):
def __init__(self, example, num_classes=10):
super(BrainNetCNN, self).__init__()
self.in_planes = example.size(1)
self.d = example.size(3)
self.e2econv1 = E2EBlock(1,32,example,bias=True)
self.e2econv2 = E2EBlock(32,64,example,bias=True)
self.E2N = torch.nn.Conv2d(64,1,(1,self.d))
self.N2G = torch.nn.Conv2d(1,256,(self.d,1))
self.dense1 = torch.nn.Linear(256,128)
self.dense2 = torch.nn.Linear(128,30)
self.dense3 = torch.nn.Linear(30,2)
def forward(self, x):
out = F.leaky_relu(self.e2econv1(x),negative_slope=0.33)
out = F.leaky_relu(self.e2econv2(out),negative_slope=0.33)
out = F.leaky_relu(self.E2N(out),negative_slope=0.33)
out = F.dropout(F.leaky_relu(self.N2G(out),negative_slope=0.33),p=0.5)
out = out.view(out.size(0), -1)
out = F.dropout(F.leaky_relu(self.dense1(out),negative_slope=0.33),p=0.5)
out = F.dropout(F.leaky_relu(self.dense2(out),negative_slope=0.33),p=0.5)
out = F.leaky_relu(self.dense3(out),negative_slope=0.33)
return out
net = BrainNetCNN(trainset.X)
if use_cuda:
net = net.cuda()
#net = torch.nn.DataParallel(net, device_ids=[0])
cudnn.benchmark = True
def init_weights_he(m):
#https://keras.io/initializers/#he_uniform
print(m)
if type(m) == torch.nn.Linear:
fan_in = net.dense1.in_features
he_lim = np.sqrt(6) / fan_in
m.weight.data.uniform_(-he_lim,he_lim)
# print(m.weight)
net.apply(init_weights_he)
推荐及下篇笔记
-
本笔记推荐的阅读清单:
- Convolutional Neural Networks for Adjacency Matrices:https://github.com/jeremykawahara/ann4brains?tab=readme-ov-file
- 论文原文
-
下篇笔记:【区域脑图论文笔记】BrainNet:Inference of brain network topology using Machine Learning



















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











