







Deep Crossing 模型
如果说AutoRec模型是将深度学习的思想应用于推荐系统的初步尝试,那么DeepCrossing模型就是一次深度学习架构在推荐系统中的完整应用。
AutoRec模型讲解详见深度学习推荐模型(1)——AutoRec
Deep Crossing 模型是一种深度学习架构,用于解决推荐系统中的特征交叉问题。它通过结合深度神经网络和交叉网络来自动学习特征之间的交叉关系,而无需人工特征工程。
应用场景:微软搜索引擎Bing中的搜索广告推荐场景。
优化目标:预测广告点击率(CTR),以提高搜索广告的点击率和排序效果
模型特征

这些特征可以分成三类:
- 类别型特征: 可以被处理成 one-hot 或者 multi-hot 向量
- 如搜索词,广告关键词,广告标题,落地页,匹配程度
- 数值型特征:特征值是数字,可以直接拼接到特征向量中
- 如点击率,预估点击率
- 需要进一步处理的特征:一组特征,需要进一步处理
- 如广告计划,曝光样例,点击样例
- 其中,样例中的id是类别型特征,预算是数值型特征
要解决的问题
-
Q:如何解决稀疏特征向量稠密化问题?离散类特征编码后过于稀疏,不利于直接输入神经网络进行训练。
A:Deep Crossing通过Embedding层将稀疏的类别型特征转换成稠密的Embedding向量,解决了稀疏特征向量稠密化的问题 -
Q:如何解决特征自动交叉组合问题?传统的机器学习算法需要人工进行特征组合,不仅耗费资源,而且难以维护和线上部署。
A:Deep Crossing模型通过自动学习特征的组合方式,减轻或避免了手工进行特征组合的开销 -
Q:如何在输出层中达成问题设定的优化目标?
A:Deep Crossing模型在其内部网络中设计了不同的神经网络层来达成问题设定的优化目标,例如在广告点击率预测中,模型的优化目标就是广告的点击率(CTR)
网络结构
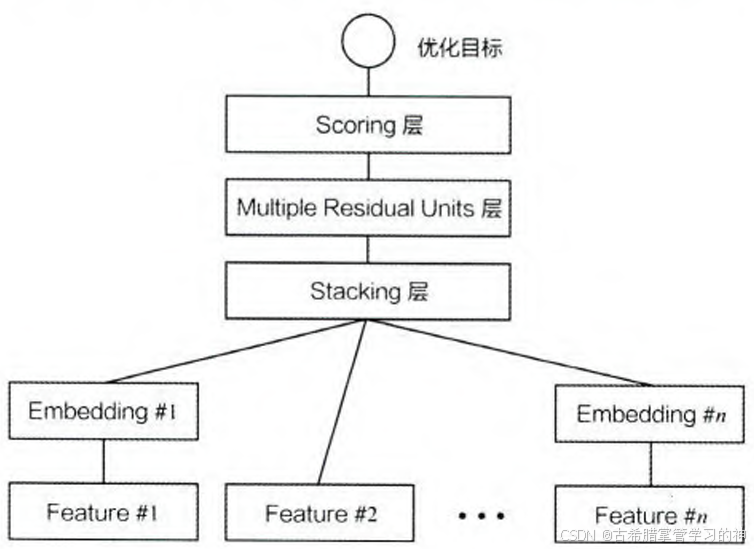
Deep Crossing 模型的网络结构包含以下几个部分:
-
Embedding层:
Embedding层将高维稀疏的特征转换成低维稠密的特征。Embedding向量的维度远小于原始的稀疏特征向量。- 对于类别型特征,通过Embedding层将其转换为稠密的向量
- 对于数值型特征,不需要经过Embedding层,直接进入下一层
Embedding层以经典的全连接层 FullyConnectedLayer)结构为主,但现在已经衍生出许多不同的方法,如Word2vec、Graph Embedding 等
-
Stacking层:
将Embedding层的输出特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量。 -
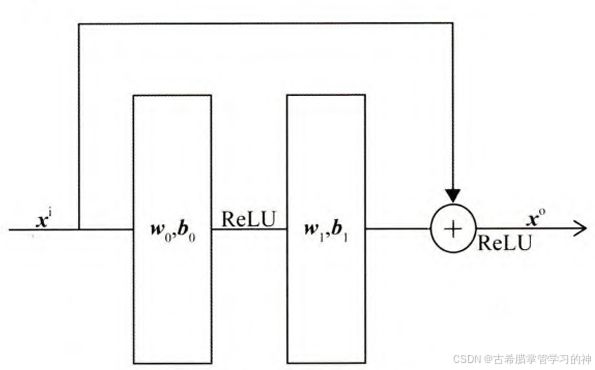
Multiple Residual Units层:
通过多层残差网络将各个维度的特征进行深层次的交叉,使模型能够学习到更多的非线性和组合特征的信息。- 在残差网络中,我们希望 H(x) 能够近似 x 经过某个复杂函数后的结果。但在实际训练中,我们并不是直接让网络学习复杂函数,而是让网络学习输入和输出之间的差值 F(x) = H(x) - x
- 残差网络的作用是减少过拟合和梯度消失现象
-
Scoring层:
Scoring层是输出层,用于拟合优化目标。- 对于CTR预估这种二分类模型,Scoring层使用逻辑回归模型
- 对于多分类问题,则使用softmax模型
优势
-
自动特征交叉:Deep Crossing 模型能够自动学习特征之间的交叉关系,无需人工特征工程或暴力搜索,降低了特征工程的复杂性
-
高阶交叉特征提取:与FM系列模型相比,Deep Crossing 能够提取更高阶的交叉特征,同时具有更高的计算效率
不足
- 针对性不强:利用全连接隐层进行特征交叉可能针对性不强,因为每个特征对结果的影响是不同的
- 模型复杂度:由于模型需要处理大量的特征交叉,可能会导致模型复杂度较高,训练和推理时间较长
参考
深度学习推荐系统(王喆)


















 4405
4405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









