







一、YOLO-V1整体思想与网络架构
1.1 YOLO算法整体思路解读
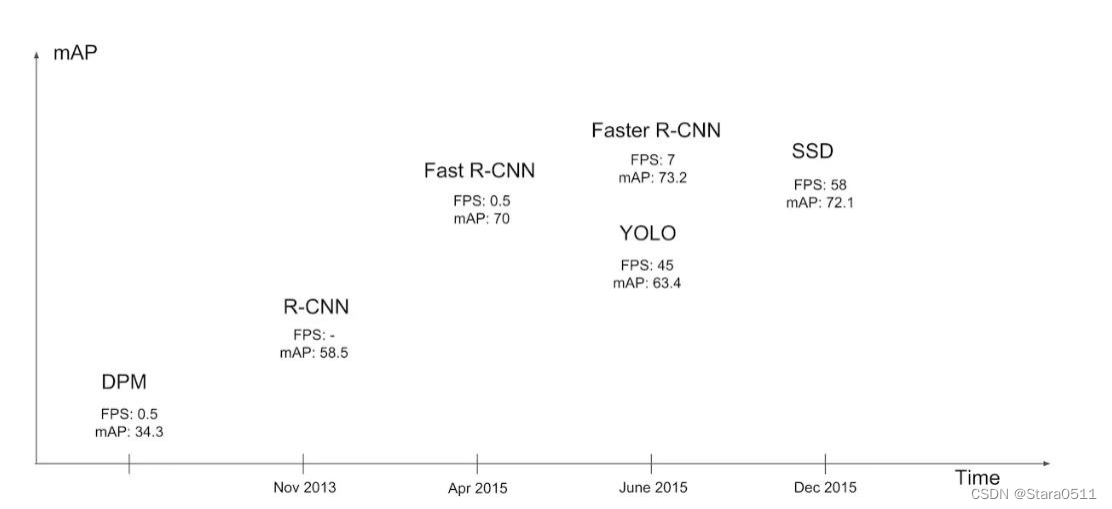
- YOLO-V1:
经典的one-stage方法
把检测问题转化成回归问题,一个CNN就搞定了!
可以对视频进行实时检测,应用领域非常广!
- 核心思想:
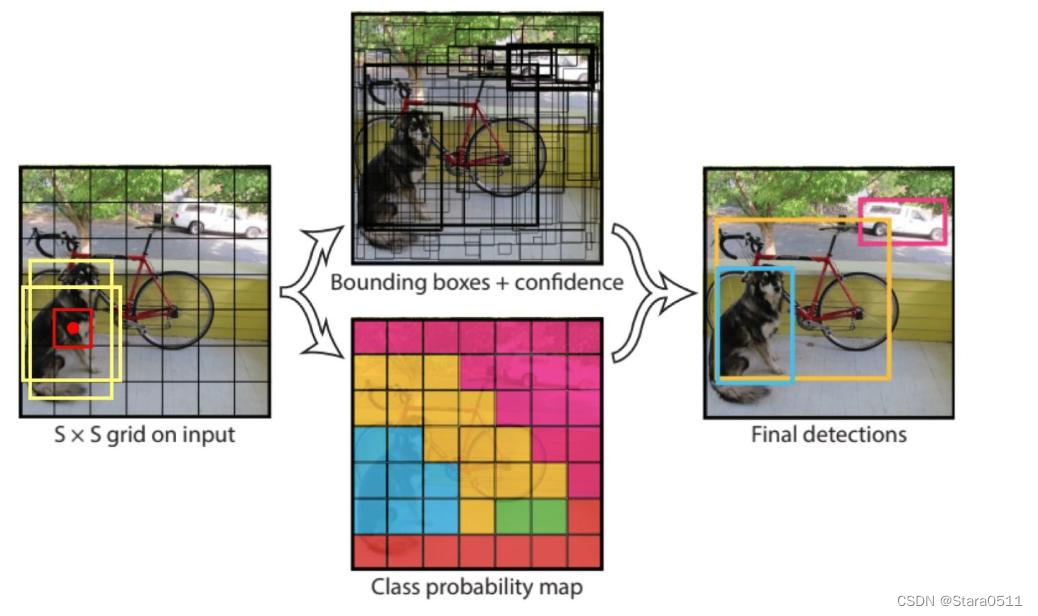
1、预测一张图像中有哪些物体,交给谁来预测呢?例如一张图像高度和宽度7×7,观察一下物体落在了图像当中的某个位置了,每个格子负责预测一下,在你这个格子上它是什么物体,比如如下图“狗”落在了图像当中一个区域,但是了现在只关心它的中心点落到哪里,比如红色框里有个中心点,红色中心点点到图像的某个格子,那么这个格子负责预测一下这个狗。怎么预测了,图像中有两个黄色的框,可以这么想黄色的框不是我们要的最终结果,我们先这样红色格子去做预测了,但是它也不知道这个狗长什么样子的,那么需要一些经验的东西,把候选框微调----回归任务(宽度、高度怎么变),并且还有起始位置x,y(起始位置可能是一个中心点)
2、首先输入是一个S×S的格子,在这个格子当中希望每个格子里每个点产生出来两种候选框去做微调,但是不是所有的候选框都做微调,必须是有物体的微调,什么时候判断有这样一个物体:每个格子预测一个值–置信度,置信度>阈值的就可能是一个物体,是物体了才对物体中有的两种候选框筛选出来一个(IOU大的一个),实际做结果把x,y,w,h算出来映射到原始图像当中,就能把这个框算出来。
1.2 整体网络架构解读
- 网络架构
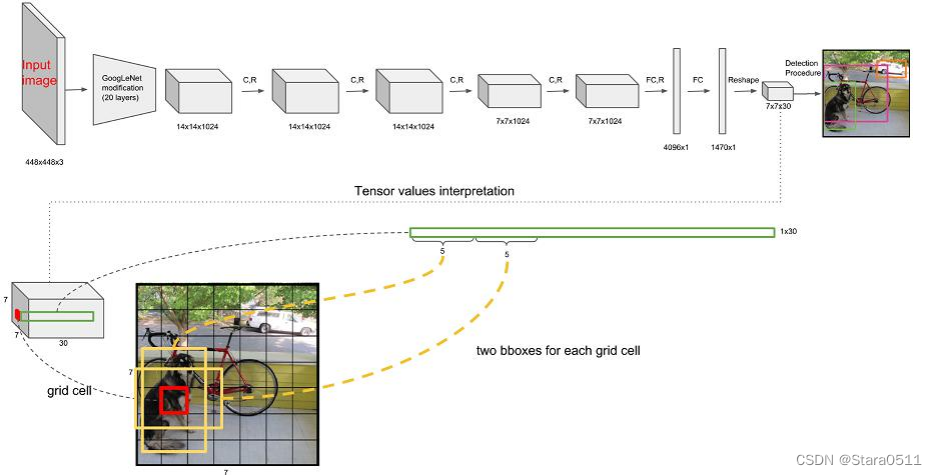
1.首先第一步拿到了一个输入图像,大小为448×448×3(大小不能变,主要原因是全连接层,全连接层是定死的)
2.中间过程:特征提取,就是一个卷积神经网络(7×7×1024的特征图)
3.第一个全连接4096×1,第二个全连接1470×1,Reshape一下7×7×30,这个值非常关键
7×7的格子,30:每个格子有30个值。对每一个格子要产生两种框。第一种框:B1:x1,y1,w1,h1,c1 其中这里的x1,y1不是实际坐标值,而是规划完之后相对整体图像来说的一个0-1之间的值,它在相对的一个长宽的一个位置。B2:x2,y2,w2,h2,c2 这样B1和B2总共10个值,剩下的20个是20分类(不同数据集可能是80),预测一下每一个分类概率值等于多少。例如狗:80%,猫:10%。如下图:
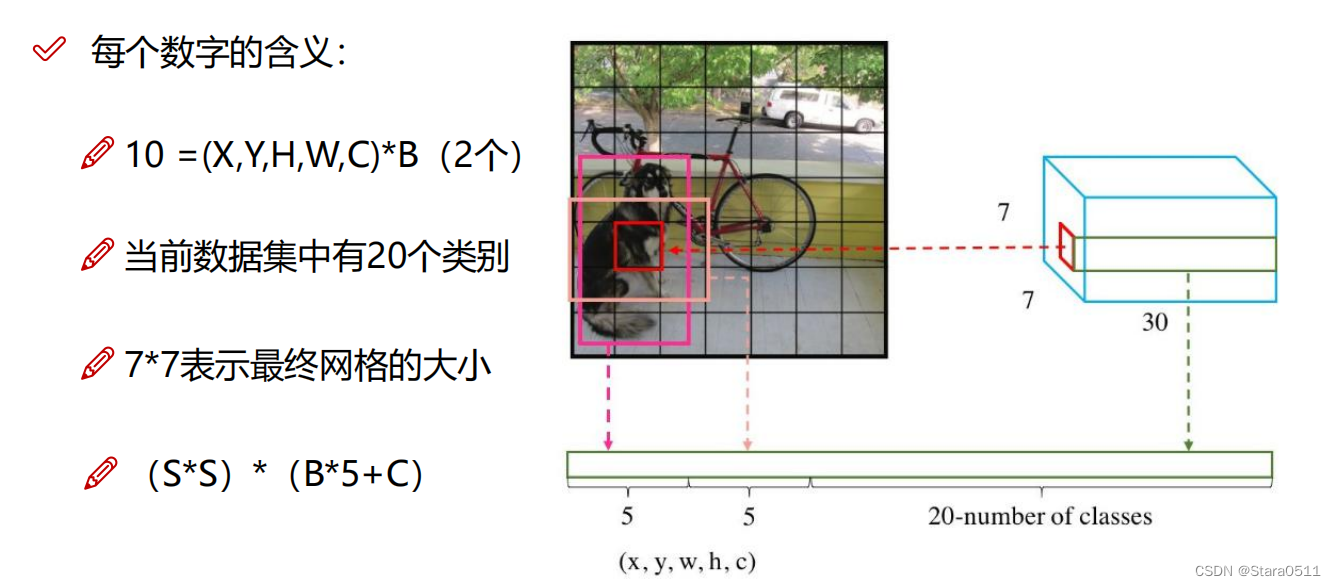
(S*S)*(B*5+C):最终格子大小S*S的,B:两个框,C:类别
1.3 位置损失计算
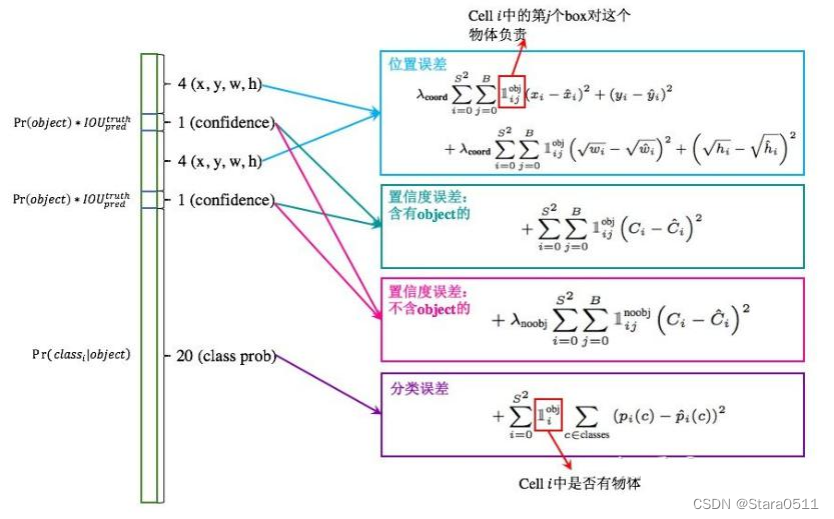
做预测的值x,y,w,h和最终真实值之间肯定会有差异,差异越小越好
- 位置误差:
S*S网格当中,对于每个格子都有预测,每一个都要实际计算。对于其中某一个格子有两种框。当前cell
i中的第i个box对这个物体负责:有两个候选框,但是对真实值来说它和两个候选框都能算一个IOU(最大的),然后算真实值和预测值之间的一个差异。加上根号说明了如果数值较小的话较为敏感,数值较大的话相对来说没有那么敏感,加根号解决了一点这个问题但是不够透彻在V1中。λcoord前面的系数在损失函数中表示权重项。

- 置信度误差:
这里分成了两部分,一部分是包含物体时置信度的损失,一个是不包含物体时置信度的值。
其中前一项表示有无人工标记的物体落入网格内,如果有,则为1,否则为0.第二项代表bounding box和真实标记的box之间的IoU。值越大则box越接近真实位置。confidence是针对bounding box的,由于每个网格有两个bounding box,所以每个网格会有两个confidence与之相对应。从损失函数上看,当网格i中的第j个预测框包含物体的时候,用上面的置信度损失,而不包含物体的时候,用下面的损失函数。对没有object的box的confidence loss,赋予小的loss weight, λnoobj记为在pascal VOC训练中取0.5。有object的box的confidence loss和类别的loss的loss weight正常取1。
- 类别损失:
类别损失这里也用了均方误差,实际上,感觉这里用交叉熵更好一些。其中
表示有无object的中心点落到网格i中,如果网格中包含有物体object的中心的话,那么就负责预测该object的概率。

总体来说,对于不同的任务重要程度不同,所以也应该给与不同的loss weight:
- 每个网格两个预测框坐标比较重要,给这些损失赋予更大的loss weight,在pascal VOC中取值为5
- 对没有object的box的confidence loss,赋予较小的loss weight,在pascal VOC训练中取0.5
- 对有object的box的confidence loss和类别的loss weight正常取值为1
1.4 NMS(非极大值抑制)
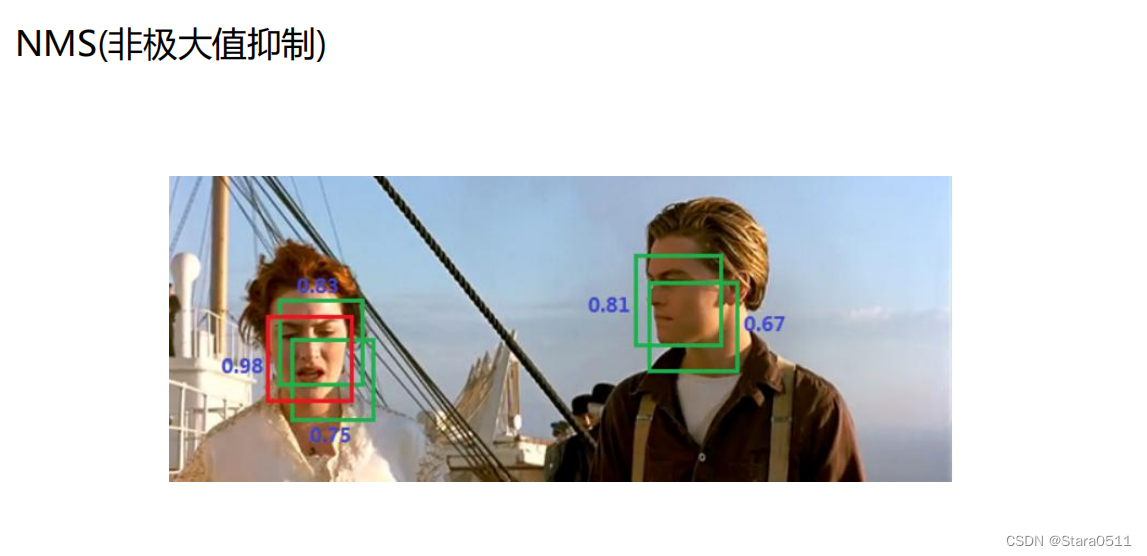
基本原理是先在图像中找到所有可能包含目标物体的矩形区域,并按照它们的置信度进行排列。然后从置信度最高的矩形开始,遍历所有的矩形,如果发现当前的矩形与前面任意一个矩形的重叠面积大于一个阈值,则将当前矩形舍去。使得最终保留的预测框数量最少,但同时又能够保证检测的准确性和召回率。具体的实现方法包括以下几个步骤:
1、对于每个类别,按照预测框的置信度进行排序,将置信度最高的预测框作为基准
2、从剩余的预测框中选择一个与基准框的重叠面积最大的框,如果其重叠面积大于一定的阈值,则将其删除。
3、对于剩余的预测框,重复步骤2,直到所有的重叠面积都小于阈值,或者没有被删除的框剩余为止。
通过这样的方式,NMS可以过滤掉所有与基准框重叠面积大于阈值的冗余框,从而实现检测结果的优化。值得注意的是,NMS的阈值通常需要根据具体的数据集和应用场景进行调整,以兼顾准确性和召回率。
总结来说,非极大值抑制原理是通过较高置信度的目标框作为基准,筛选出与其重叠度较低的目标框,从而去除掉冗余的目标框,提高目标检测的精度和效率。
1.5 YOLO-V1问题
优点:快速,简单!
每个Cell只预测一个类别,如果重叠无法解决
小物体检测效果一般,长宽比可选的但单一
















 3009
3009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











