









文章目录
论文题目:
分子图的定向消息传递
论文作者:
Johannes Gasteiger、Janek Gro ß和Stephan Günnemann德国慕尼黑工业大学
DimeNet++的作者(Johannes Gasteiger、Shankari Giri、Johannes T.Margraf、Stephan Günnemann慕尼黑工业大学)
发表时间:
2020// V2:2022.4.5
发表期刊:
评论: 在ICLR 2020上作为会议论文发表。作者姓名从 Johannes Klicpera 更改为 Johannes Gasteiger
科目: 机器学习 (cs.LG);计算物理 (physics.comp-ph);机器学习 (stat.ML)
论文摘要:
研究方向 --- 预测分子的量子力学性质
论文研究的核心问题:
GNN没有考虑从一个原子到另一个原子的空间方向
论文采用的研究方法:
嵌入原子之间传递的消息(基于消息之间的角度来转换消息来使用方向信息)
使用球面贝塞尔函数和球面谐波来构建理论上有充分依据的正交表示
论文的创新点
嵌入原子之间传递的消息(基于消息之间的角度来转换消息来使用方向信息)
-----> 距离和角度对于分子的平移、旋转和反转都是不变的
论文的不足之处
摘要
图神经网络最近在预测分子的量子力学性质方面取得了巨大成功。这些模型仅使用原子(节点)之间的距离将分子表示为图。然而,它们没有考虑从一个原子到另一个原子的空间方向,尽管方向信息在分子的经验势中起着核心作用,例如在角势中。为了减轻这种限制,我们提出了定向消息传递,其中我们嵌入原子之间传递的消息,而不是原子本身。每个消息与坐标空间中的方向相关联。这些定向消息嵌入在旋转上是等变的,因为相关联的方向随分子旋转。我们提出了一种类似于信念传播的消息传递方案,该方案通过基于消息之间的角度来转换消息来使用方向信息。此外,我们使用球面贝塞尔函数和球面谐波来构建理论上有充分依据的正交表示,这些表示在使用不到1/4的参数的同时,实现了比当前流行的高斯径向基表示更好的性能。我们利用这些创新来构建定向消息传递神经网络(DimeNet)。DimeNet在MD17上的表现平均优于之前的GNN 76%,在QM9上平均优于之前的GNN 31%。我们的实现可以在线获得。1
一、介绍
近年来,科学家们已经开始利用机器学习将预测分子特性所需的计算时间从几小时和几天减少到几毫秒。随着图神经网络(GNNs)的出现,这种方法最近经历了一场小革命,因为它们不需要任何形式的手动特征工程,并且明显优于以前的模型(Gilmer等人,2017;Schütt等人,2017)。GNNs通过将每个原子嵌入高维空间并通过在原子之间传递消息来更新这些嵌入来模拟原子之间的复杂相互作用。通过预测势能,这些模型有效地学习了经验势函数。经典地,这些函数被建模为四个部分的总和:(Leach,2001)
E
=
E
b
o
n
d
s
+
E
a
n
g
l
e
+
E
t
o
r
s
i
o
n
+
E
n
o
n
−
b
o
n
d
e
d
,
E=E_{\mathrm{bonds}}+E_{\mathrm{angle}}+E_{\mathrm{torsion}}+E_{\mathrm{non-bonded}},
E=Ebonds+Eangle+Etorsion+Enon−bonded,其中
E
b
o
n
d
s
E_{bonds}
Ebonds模拟对键长的依赖性,Eangle模拟键之间的角度,Etorsion模拟键旋转,即由键对定义的两个平面之间的二面角,Enon-bonded模拟未连接原子之间的相互作用,例如通过静电或范德华相互作用。然而,GNNs中的更新消息仅取决于先前的原子嵌入和原子之间的成对距离,而不取决于方向信息,如键角和旋转。因此,GNNs缺乏该方程的第二项和第三项,只能通过消息的复杂高阶交互来模拟它们。扩展GNNs以直接模拟它们并不简单,因为GNNs仅依赖于成对距离,这确保了它们对分子的平移、旋转和反转的不变性,这是重要的物理要求。
在本文中,我们建议通过使用与相邻原子的方向相关联的嵌入来解决这一限制,即通过将原子嵌入为一组消息。这些定向消息嵌入相对于上述变换是等变的,因为方向随分子移动。因此,它们保留了相邻原子之间的相对方向信息。我们建议让消息嵌入基于原子之间的距离和方向之间的角度进行交互。根据需要,距离和角度对于分子的平移、旋转和反转都是不变的。此外,我们表明,通过使用球面贝塞尔函数和球面谐波,距离和角度可以以一种有原则和有效的方式联合表示。我们利用这些创新来构建定向消息传递神经网络(DimeNet)。DimiNet既可以学习分子性质,也可以学习原子力。它是两次连续可微的,并且仅基于原子类型和坐标,这是执行分子动力学模拟的基本性质。DimeNet在MD17上的表现平均优于之前的GNN 76%,在QM9上平均优于之前的GNN 31%。我们论文的主要贡献是:
- 定向消息传递,它允许GNN通过连接等变和图神经网络领域的最新进展以及来自信念传播和经验势函数(如等式)的想法来整合定向信息。1.
- 基于球贝塞尔函数和球谐函数的理论原理正交基表示。贝塞尔函数实现了比高斯径向基函数更好的性能,同时将径向基维数降低了4倍或更多。
- 定向消息传递神经网络(DimeNet):一种新颖的GNN,其利用这些创新为分子预测设定了新的技术状态,并且适用于预测分子性质和分子动力学模拟。
二、相关工作
对于分子的ML。使用机器学习预测分子性质的经典方法是将原子邻域的表达性、手工制作的表示(Bartók等人,2013年)与高斯过程(Bartók等人,2010年;2017年;Chmiela等人,2017年)或神经网络(Behler&Parrinello,2007年)相结合。最近,这些方法在很大程度上被图形神经网络所取代,图形神经网络不需要任何手工制作的特征,而是 (GNN)仅基于原子类型和坐标分子来学习表示(Duvenaud等人,2015;吉尔默等人,2017;Schütt等人,2017;Hy等人,2018;Unke&Meuwly,2019)。我们提出的消息嵌入也可以解释为有向边嵌入或线图上的嵌入(Chen等人,2019b)。(无定向)边缘嵌入已经在以前的分子GNNs中使用(J ø rgensen等人,2018;陈等人,2019a)。然而,这些GNN同时使用节点和边嵌入,并且不利用任何方向信息。
图形神经网络。GNNs最早是在90年代提出的(Baskin等人,1997;Sperduti&Starita,1997年)和00s(Gori等人,2005年;Scarselli等人,2009年)。通用GNNs在很大程度上受到了它们在分子图中的应用的启发,并在分子变体几乎同时开始在各种任务中实现突破性性能(Kipf&Welling,2017;加斯泰格等人,2019;赞巴尔迪等人,2019)。最近的一些进展集中在比同构的1-Weisfeiler-Lehman检验更强大的GNNs上(Morris等人,2019;马龙等人,2019)。然而,对于分子预测,这些模型明显优于专注于分子的GNNs(见第7节)。最近的一些GNN通过考虑每个原子的局部坐标系的变化纳入了方向信息(Ingraham等人,2019)。然而,这种方法打破了排列不变性,因此仅适用于链状分子(例如蛋白质)。
等变神经网络。群体等方差作为现代机器学习的一个原理最早由Cohen&Welling(2016)提出。以下工作将这一原理推广到球体(Cohen等人,2018年)、分子(Thomas等人,2018年)、体积数据(Weiler等人,2018年)和一般流形(Cohen等人,2019年)。到目前为止,通过在每层的傅立叶和坐标空间之间来回切换(Cohen等人,2018)或通过使用全傅立叶空间模型(Kondor等人,2018;安德森等人,2019)。1. 前者引入了主要的计算开销,2, 后者对模型构建施加了重大限制,例如无法使用非线性。我们提出的解决方案没有这些限制。
三、分子预测的要求
近年来,机器学习已被用于预测各种各样的分子特性,包括低水平的量子力学特性,如势能、最高占据分子轨道(HOMO)的能量和偶极矩,以及高水平的特性,如毒性、渗透性和药物不良反应(Wu等人,2018)。在这项工作中,我们将关注标量回归目标,即目标t∈R。分子由原子序数 z = { z 1 , . . . , z N } z=\{z_1,...,z_N\} z={z1,...,zN}和位置 X = { x 1 , . . . , x N } X=\{x_1,...,x_N\} X={x1,...,xN}唯一定义。一些模型另外使用辅助信息Θ,例如原子的键类型或电负性。我们在这项工作中不包括辅助功能,因为它们是手工设计的,不是必需的。总之,我们定义了一个ML模型,用于分子预测,参数θ通过 f θ : { X , z } → R f_θ:\{X,z\}→R fθ:{X,z}→R
对称性和不变性。所有的分子预测都必须遵守一些基本的物理定律,无论是明确的还是隐含的。这方面的一个重要例子是物理学的基本对称性及其相关的不变性。原则上,这些不变性可以由任何神经网络通过相应的权重矩阵对称性来学习(Ravanbakhsh等人,2017)。然而,不明确地将它们合并到模型中会引入重复的权重并增加训练时间和复杂性。最基本的对称性是平移和旋转不变性(来自均匀性和各向同性)、排列不变性(来自粒子的不可区分性)以及宇称下的对称性,即单个空间坐标的符号翻转下的对称性。
分子动力学。当模型需要适合于分子动力学(MD)模拟并预测作用在每个原子上的力Fi时,就会出现额外的要求。力场是一个保守的向量场,因为它必须满足能量守恒(能量守恒的必要性源于时间的均匀性(Noether,1918))。定义保守向量场最简单的方法是通过势函数的梯度。我们可以通过预测势而不是力来利用这一事实,然后通过反向传播到原子坐标来获得力,即
F
i
(
X
,
z
)
=
−
∂
∂
x
i
f
θ
(
X
,
z
)
.
F_i(X,z)=-\frac\partial{\partial\boldsymbol{x}_i}f_\theta(X,\boldsymbol{z}).
Fi(X,z)=−∂xi∂fθ(X,z).
我们甚至可以直接将这些力纳入训练损失中,并直接训练用于MD模拟的模型(Pukrittayakamee等人,2009):
L
M
D
(
X
,
z
)
=
∣
f
θ
(
X
,
z
)
−
t
^
(
X
,
z
)
∣
+
ρ
3
N
∑
i
=
1
N
∑
α
=
1
3
∣
−
∂
f
θ
(
X
,
z
)
∂
x
i
α
−
F
^
i
α
(
X
,
z
)
∣
,
\mathcal{L}_{\mathrm{MD}}(X,z)=\left|f_\theta(X,z)-\hat{t}(X,z)\right|+\frac{\rho}{3N}\sum_{i=1}^N\sum_{\alpha=1}^3\left|-\frac{\partial f_\theta(X,z)}{\partial x_{i\alpha}}-\hat{F}_{i\alpha}(X,z)\right|,
LMD(X,z)=
fθ(X,z)−t^(X,z)
+3Nρi=1∑Nα=1∑3
−∂xiα∂fθ(X,z)−F^iα(X,z)
,其中目标t=E是地面真实能量(通常也是可用的),F是地面真实力,超参数ρ设置力的损失重量。对于稳定模拟,Fi必须是连续可微的,因此模型f θ本身是两次连续可微的。因此,我们不能使用不连续变换,如ReLU非线性。此外,由于原子位置X可以任意改变,我们不能使用预先计算的辅助信息Θ,例如键类型。
四、定向消息传递
图形神经网络。图神经网络将分子视为图,其中节点是原子,边通过预定义的分子图或简单地通过连接位于截止距离c内的原子来定义。每条边与原子之间的成对距离
d
i
j
=
‖
x
i
−
x
j
‖
2
d_{ij}=‖x_i-x_j‖_2
dij=‖xi−xj‖2相关联。GNN通过构造实现了所有上述物理不变性,因为它们仅使用成对距离而不是完整的原子坐标。然而,请注意,预定义的分子图或类似阶跃函数的截止不能用于MD模拟,因为这将在能量景观中引入不连续性。GNNs通过原子嵌入
h
i
∈
R
H
h_i∈R^H
hi∈RH表示每个原子i。通过沿着分子边缘传递消息,原子嵌入在每一层中被更新。消息通常基于边缘嵌入
e
(
i
j
)
∈
R
H
e
e_{(ij)}∈R^{H_e}
e(ij)∈RHe进行变换,并在原子的邻居
N
i
\mathcal N_i
Ni上求和,在l层通过更新嵌入
h
i
(
l
+
1
)
=
f
update
(
h
i
(
l
)
,
∑
j
∈
N
i
f
int
(
h
j
(
l
)
,
e
(
i
j
)
(
l
)
)
)
,
h_i^{(l+1)}=f_\text{update}(h_i^{(l)},\sum_{j\in\mathcal{N}_i}f_\text{int}(h_j^{(l)},e_{(ij)}^{(l)})),
hi(l+1)=fupdate(hi(l),j∈Ni∑fint(hj(l),e(ij)(l))),使用更新函数fupdate和交互函数fint,这两者通常都使用神经网络来实现。边缘嵌入
e
(
i
j
)
(
l
)
e^{(l)}_{(ij)}
e(ij)(l)通常仅取决于原子间距离,但也可以包含额外的键信息(Gilmer等人,2017年)或使用相邻原子嵌入在每一层中递归更新(J ø rgensen等人,2018年)。
方向性。原则上,成对距离矩阵包含分子的全部几何信息。然而,GNNs不使用全距离矩阵,因为这意味着在所有原子对之间全局传递消息,这增加了计算复杂性并可能导致过度拟合。相反,他们通常使用截止距离c,这意味着他们无法区分某些分子(Xu等人,2019)。例如。在大约2Å的截止值处,常规GNN将无法区分具有相同键长的六角形分子(例如环己烷)和两个三角形分子(例如环丙烷),因为两者的每个原子的邻域完全相同(参见附录,图6)。这个问题可以通过模拟相邻原子的方向而不仅仅是它们的距离来解决。一种原则性的方法是这样做,同时对变换群G保持不变(如第2节所述。3)是通过群等方差(Cohen&Welling,2016)。如果 f ( φ g X ( x ) ) = φ g Y ( f ( x ) ) , f(\varphi_g^X(x))=\varphi_g^Y(f(x)), f(φgX(x))=φgY(f(x)),,则函数f:x→Y被定义为等变函数,在输入和输出空间 φ g X φ _g^X φgX和 φ g y φ_g^y φgy中具有群作用。然而,等变CNN仅相对于一组离散旋转实现等方差(Cohen&Welling,2016)。为了精确预测分子性质,我们需要相对于旋转,即相对于SO(3)基团的连续等方差。
方向嵌入。我们通过注意到原子本身是旋转不变的来解决这个问题。这种不变性只被与之相互作用的邻近原子所破坏,即截断c内的原子。由于每个邻居分解到一个旋转不变性,它们还引入了额外的自由度,这需要在我们的模型中表示。我们可以这样做,通过在每个相邻原子(与等变CNN不同,它在固定的全局方向上应用滤波器)的方向上应用相同的学习滤波器,为每个原子i和邻居j生成单独的嵌入mji。这些方向嵌入相对于全局旋转是等变的,因为相关的方向随分子旋转,因此保存了相对的方向信息。
基于联合2D基的表示。我们通过利用角度 α ( k j , j i ) = ∠ x k x j x i α _{( kj , ji)} =∠x_kx_jx_i α(kj,ji)=∠xkxjxi在聚合 m j i m_{ji} mji的相邻嵌入mkj时使用与每个嵌入相关的方向信息。我们将夹角和与传入消息 m k j m_{kj} mkj相关的原子间距离 d k j d_{kj} dkj结合起来,在 a S B F ( k j , j i ) ∈ R N S H B F ⋅ N S R B F a^{( kj , ji)} _{SBF}∈R^{NSHBF · NSRBF} aSBF(kj,ji)∈RNSHBF⋅NSRBF中使用基于球贝塞尔函数和球谐函数的2D表示来共同表示两者,如Sec. 5中所述。我们经验性地发现,这种基表示提供了比单独使用原始角度更好的归纳偏差。值得注意的是,通过仅仅使用原子间的距离和角度,我们的模型对旋转具有不变性。
消息嵌入。与原子对
j
i
ji
ji相关的定向嵌入
m
j
i
m_{ji}
mji可以看作是从原子j发送给原子i的消息。因此,类似于置信传播,我们使用一组传入消息
m
j
i
m_{ji}
mji嵌入每个原子i,即
h
i
=
∑
j
∈
N
i
m
j
i
h_i =\sum_{j\in N_i} m_{ji}
hi=∑j∈Nimji,并基于传入消息
m
k
j
m_{kj}
mkj ( Yedidia等, 2003)更新消息
m
j
i
m_{ji}
mji。因此,如图1所示,我们定义消息嵌入的更新函数和聚合方案为
m
j
i
(
l
+
1
)
=
f
u
p
d
a
t
e
(
m
j
i
(
l
)
,
∑
k
∈
N
j
∖
{
i
}
f
i
n
t
(
m
k
j
(
l
)
,
e
R
B
F
(
j
i
)
,
a
S
B
F
(
k
j
,
j
i
)
)
)
,
m_{ji}^{(l+1)}=f_{\mathrm{update}}(m_{ji}^{(l)},\sum_{k\in\mathcal{N}_{j}\setminus\{i\}}f_{\mathrm{int}}(m_{kj}^{(l)},e_{\mathrm{RBF}}^{(ji)},a_{\mathrm{SBF}}^{(kj,ji)})),
mji(l+1)=fupdate(mji(l),k∈Nj∖{i}∑fint(mkj(l),eRBF(ji),aSBF(kj,ji))),
其中
e
R
B
F
(
j
i
)
e ^{(ji)}_{ RBF}
eRBF(ji)表示原子间距离
d
j
i
d_{ji}
dji的径向基函数表示,将在第二节中讨论。5 .我们发现,这种聚合方案不仅与信念传播有很好的类比,而且在实证上的表现也比备选方案要好。注意,由于
f
i
n
t
f_{int}
fint现在包含了原子对或键之间的夹角,我们使得我们的模型可以直接学习到方程中的第二项角动量
E
a
n
g
l
e
E_{angle}
Eangle。1 .此外,消息嵌入本质上是原子对的嵌入,基于高阶Weisfeiler - Lehman同构性检验的可证明更强大的GNN使用的是原子对的嵌入。因此,我们的模型可以证明区分常规GNN不能区分的分子(例如,以前的一个六角形和两个三角形分子的例子) ( Morris et al .,2014 )
五、基于物理的表示
表示距离和角度:
对于等式2中的相互作用函数 f i n t f_{int} fint 我们使用消息嵌入和原子间距离 d k j = ∥ x k − x j ∥ 2 d_{kj}=\|x_k-x_j\|_2 dkj=∥xk−xj∥2 之间的角度α_(kj,ji)的联合表示 a S B F ( k j , j i ) a^{(kj,ji)}_{SBF} aSBF(kj,ji), 以及距离dji的表示 e R B F ( j i ) e^{(ji)}_{RBF} eRBF(ji)。早期的工作使用一组高斯径向基函数来表示原子间距离,具有紧密间隔的平均值,例如均匀分布(Schütt等人,2017年)或指数分布(Unke&Meuwly,2019年)。在精神上类似于可操纵CNN使用的功能基(Cohen&Welling,2017;Cheng等人,2019)我们建议使用正交基来代替,这减少了冗余,从而提高了参数效率。此外,根据建模系统的特性选择的基甚至可以提供有用的感应偏置。因此,我们接下来推导出量子系统的适当基表示。
从薛定谔到傅立叶-贝塞尔:
为了以有原则的方式构造基表示,我们首先考虑可能解的空间。我们的模型旨在近似密度泛函理论(DFT)计算的结果,即由电子密度<Ψ(d) |Ψ(d)>给出的结果,电子波函数Ψ(d)和d=xk−xj。Ψ(d)的解空间由与时间无关的薛定谔方程
(
−
h
2
2
m
∇
2
+
V
(
d
)
)
Ψ
(
d
)
=
E
Ψ
(
d
)
(-\frac{h^2}{2m}∇^2+V(d))\Psi(d)=E\Psi(d)
(−2mh2∇2+V(d))Ψ(d)=EΨ(d) 定义,质量m和能量E为常数。我们不知道势V(d),因此以一种无信息的方式选择它,只需在截止距离c(我们在原子之间传递信息的范围内将其设置为0,在截止距离c之外将其设置为∞。因此,我们得到亥姆霍兹方程
(
∇
2
+
k
2
)
Ψ
(
d
)
=
0
(∇^2+k^2)\Psi(d)=0
(∇2+k2)Ψ(d)=0,波数
k
=
2
m
E
h
k=\frac{\sqrt{2mE}}{h}
k=h2mE,边界条件
Ψ
(
c
)
=
0
\Psi(c)=0
Ψ(c)=0 在截止c处。极坐标(d,α,φ)中变量的分离产生解(Griffiths&Schroeter,2018)
Ψ
(
d
,
α
,
φ
)
=
∑
l
=
0
∞
∑
m
=
−
l
l
(
a
l
m
j
l
(
k
d
)
+
b
l
m
y
l
(
k
d
)
)
Y
l
m
(
α
,
φ
)
,
(5)
\Psi(d,\alpha,\varphi)=\sum_{l=0}^\infty\sum_{m=-l}^l(a_{lm}j_l(kd)+b_{lm}y_l(kd))Y_l^m(\alpha,\varphi),\tag{5}
Ψ(d,α,φ)=l=0∑∞m=−l∑l(almjl(kd)+blmyl(kd))Ylm(α,φ),(5)
其中,第一类和第二类球贝塞尔函数
j
l
j_l
jl和
y
l
y_l
yl以及球谐函数
Y
l
m
Y^m_l
Ylm。正如物理学中常见的那样,我们只使用正则解,即那些在原点不接近∞的解,因此将
b
l
m
=
0
b_{lm}=0
blm=0。回想一下,我们的第一个目标是为
d
k
j
d_{kj}
dkj和
α
(
k
j
,
j
i
)
\alpha(kj,ji)
α(kj,ji)构造一个联合2D基,即依赖于d和单个角度α的函数。为了实现这一点,我们设置m=0并获得
Ψ
S
B
F
(
d
,
α
)
=
∑
l
a
l
j
l
(
k
d
)
Y
l
0
(
α
)
\Psi_{\mathbf{SBF}}(d,\alpha)=\sum_{l}a_{l}j_{l}(kd)Y_{l}^{0}(\alpha)
ΨSBF(d,α)=∑laljl(kd)Yl0(α) 。通过设置
k
=
z
l
n
c
k=\frac{z_{ln}}{c}
k=czln来满足边界条件,其中
z
l
n
z_{ln}
zln是
l
l
l 阶贝塞尔函数的第n个根,这些条件是数值预先计算的。在截止距离c内归一化
Ψ
S
B
F
\Psi_{SBF}
ΨSBF产生2D球形傅立叶-贝塞尔基
:
a
~
S
B
F
(
k
j
,
j
i
)
∈
R
N
S
H
B
F
⋅
N
S
R
B
F
:\tilde{a}_{\mathrm{SBF}}^{(kj,ji)}\in\mathbb{R}^{N_{\mathrm{SHBF}}\cdot N_{\mathrm{SRBF}}}
:a~SBF(kj,ji)∈RNSHBF⋅NSRBF,如图2所示,并由
a
~
S
B
F
,
l
n
(
d
,
α
)
=
2
c
3
j
l
+
1
2
(
z
l
n
)
j
l
(
z
l
n
c
d
)
Y
l
0
(
α
)
,
(6)
\tilde{a}_{\mathbf{SBF},ln}(d,\alpha)=\sqrt{\frac2{c^3j_{l+1}^2(z_{ln})}}j_l(\frac{z_{ln}}cd)Y_l^0(\alpha),\tag{6}
a~SBF,ln(d,α)=c3jl+12(zln)2jl(czlnd)Yl0(α),(6)
l
∈
[
0..
N
S
H
B
F
−
1
]
l∈[0..N_{SHBF}−1]
l∈[0..NSHBF−1] 和
n
∈
[
1..
N
S
R
B
F
]
n\in[1..N_{SRBF}]
n∈[1..NSRBF]。我们的第二个目标是为dji构建一个径向基,即一个仅依赖于d而不依赖于角度α和φ的函数。我们通过设置l=m=0并获得
Ψ
R
B
F
(
d
)
=
a
j
0
(
z
0
,
n
c
d
)
Ψ_{RBF}(d)=aj_0(\frac{z_{0,n}}{c} d)
ΨRBF(d)=aj0(cz0,nd) 来实现这一点, 其中根为
z
0
,
n
=
n
π
z_{0,n}=n\pi
z0,n=nπ, 初始化:
j
0
(
d
)
=
sin
(
d
)
/
d
j_0(d)=\sin(d)/d
j0(d)=sin(d)/d , 从而得到径向基
e
~
R
B
F
∈
R
N
R
B
F
\tilde{e}_{\mathbf{RBF}}\in \mathbb R^{N_{RBF}}
e~RBF∈RNRBF ,
e
~
R
B
F
,
n
(
d
)
=
2
c
sin
(
n
π
c
d
)
d
,
(7)
\tilde{e}_{\mathbf{RBF},n}(d)=\sqrt{\frac{2}{c}}\frac{\sin(\frac{n\pi}{c}d)}{d},\tag{7}
e~RBF,n(d)=c2dsin(cnπd),(7)
n
∈
[
1..
N
R
B
F
]
n\in[1..N_{RBF}]
n∈[1..NRBF] , 这两个基都是纯实值的,并且在感兴趣的域中是正交的。此外,它们使我们能够用
ω
α
≤
N
S
H
B
F
2
π
,
ω
d
k
i
≤
N
S
R
B
F
c
,
a
n
d
ω
d
j
i
≤
N
R
B
F
c
\omega_{\alpha}\leq\frac{N_{\mathrm{SHBF}}}{2\pi},\omega_{d_{k_{i}}}\leq\frac{N_{\mathrm{SRBF}}}{c},\mathrm{~and~}\omega_{d_{j_{i}}}\leq\frac{N_{\mathrm{RBF}}}{c}
ωα≤2πNSHBF,ωdki≤cNSRBF, and ωdji≤cNRBF 来限制最高频率分量.
连续截止:
由于阶跃函数在c处截止,
e
R
B
F
~
\tilde{\boldsymbol{e_{\mathrm{RBF}}}}
eRBF~ 和
e
R
B
F
~
\tilde{\boldsymbol{e_{\mathrm{RBF}}}}
eRBF~ 不是两次连续可微的。为了缓解这个问题,我们引入了一个包络函数u(d),它在
d
=
c
d=c
d=c处具有重数根3,导致最终函数
a
R
B
F
(
d
)
=
u
(
d
)
a
R
B
F
~
(
d
)
\boldsymbol{a_{\mathrm{RBF}}}(d)=u(d)\tilde{\boldsymbol{a_{\mathrm{RBF}}}}(d)
aRBF(d)=u(d)aRBF~(d) 和
e
R
B
F
(
d
)
=
u
(
d
)
e
R
B
F
~
(
d
)
\boldsymbol{e_{\mathrm{RBF}}}(d)=u(d)\tilde{\boldsymbol{e_{\mathrm{RBF}}}}(d)
eRBF(d)=u(d)eRBF~(d)
它们的一阶和二阶导数在截止点处变为0。我们用多项式来实现这一点
u
(
d
)
=
1
−
(
p
+
1
)
(
p
+
2
)
2
d
p
+
p
(
p
+
2
)
d
p
+
1
−
p
(
p
+
1
)
2
d
p
+
2
,
(8)
u(d)=1-\frac{(p+1)(p+2)}2d^p+p(p+2)d^{p+1}-\frac{p(p+1)}2d^{p+2},\tag{8}
u(d)=1−2(p+1)(p+2)dp+p(p+2)dp+1−2p(p+1)dp+2,(8)
其中,
p
∈
N
0
p\in \mathbb N_0
p∈N0. 我们没有发现模型对包络函数的不同选择敏感,并选择p=6。请注意,使用包络函数会导致基失去它们的正交性,这在实践中我们没有发现是一个问题。此外,我们通过反向传播对̃eRBF∈RNRBF中使用的贝塞尔波数kn=n π c进行微调,在将它们初始化为这些值后,我们发现这在预测精度上有很小的提高。
6 定向消息传递神经网络(DIMENET)
图4:DimeNet架构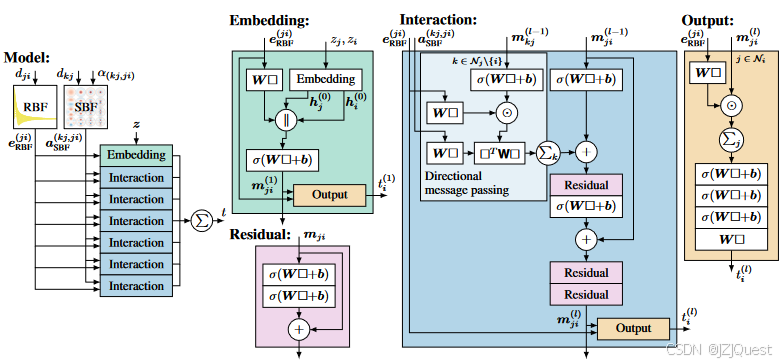
方框 表示层的输入,‖表示级联。使用球形贝塞尔函数表示距离dji,并且使用2D球形傅立叶-贝塞尔基共同表示距离 d k j d_{kj} dkj和角度 α ( k j , j i ) \alpha_{(kj,ji)} α(kj,ji)。嵌入块生成初始消息嵌入 m j i m_{ji} mji。这些嵌入通过定向消息传递在多个交互块中更新,定向消息传递使用相邻消息 m k j , k ∈ N j { i } m_{kj},k∈N_j \{i\} mkj,k∈Nj{i}, 2D表示 a S B F ( k j , j i ) a^{(kj,ji)}_{SBF} aSBF(kj,ji)和距离表示 e R B F ( j i ) e^{(ji)}_{RBF} eRBF(ji)。每个块将得到的嵌入传递给输出块,输出块使用径向基 e R B F ( j i ) e^{(ji)}_{RBF} eRBF(ji)变换它们,并对每个原子进行求和。最后,将所有层的输出相加以生成预测.
定向消息传递神经网络(DimeNet)的设计基于PhysNet架构的简化版本(Unke&Meuwly,2019),其中我们集成了定向消息传递和球面傅立叶-贝塞尔表示。DimeNet生成的预测对原子排列和分子的平移、旋转和反转是不变的。DimeNet既适用于各种分子性质的预测,也适用于分子动力学(MD)模拟。它是两次连续可微的,能够通过反向传播学习和预测原子力,如第3节所述。预测的力通过结构实现能量守恒,并且关于排列和旋转是等变的。模型可微性与具有有界最大频率的基表示相结合,进一步保证了对小变形稳定的平滑预测。图4给出了架构的概述。
嵌入块:
原子序数由跨分子共享的可学习的、随机初始化的原子类型嵌入
h
i
(
0
)
∈
R
F
h^{(0)}_i\in \mathbb R^F
hi(0)∈RF 表示。第一层从这些和原子之间的距离生成消息嵌入
m
j
i
(
1
)
=
σ
(
[
h
j
(
0
)
∥
h
i
(
0
)
∥
e
R
B
F
(
j
i
)
]
W
+
b
)
,
(9)
m_{ji}^{(1)}=\sigma([h_j^{(0)}\|h_i^{(0)}\|e_{\mathrm{RBF}}^{(ji)}]W+b),\tag{9}
mji(1)=σ([hj(0)∥hi(0)∥eRBF(ji)]W+b),(9)
其中‖表示级联,权重矩阵W和偏差b是可学习的。
交互块:
嵌入块之后是多个堆叠的交互块。该块实现等式4 的 f i n t f_{int} fint 和 f u p d a t e f_{update} fupdate,如图4所示。注意,2D表示 a R B F ( j i ) a^{(ji)}_{RBF} aRBF(ji) 首先经由线性层转换成n双线性维表示。这样做的主要目的是使 a R B F ( j i ) a^{(ji)}_{RBF} aRBF(ji) 的维数独立于后续的双线性层,后者使用相对较大的 N b i l i n e a r 双线性 × F × F N_{bilinear双线性}× F × F Nbilinear双线性×F×F 维权重张量。我们还尝试了使用双线性层作为径向基表示,但发现逐元素乘法 e R B F ( j i ) W ⊙ m k j e_{\mathrm{RBF}}^{(ji)}W\odot m_{kj} eRBF(ji)W⊙mkj 表现更好,这表明2D表示需要比单独的径向信息更复杂的变换。交互块使用多个残差块转换每个消息嵌入m_ji,这些残差块受ResNet(He等人,2016)的启发,由两个堆叠的密集层和一个跳过连接组成。
输出块:
每个块(包括嵌入块)之后的消息嵌入被传递到输出块。输出块使用径向基 e R B F ( j i ) e^{(ji)}_{RBF} eRBF(ji) 变换嵌入m_ji的每个消息,这确保了连续可微性并略微提高了性能。然后,对每个原子i的输入消息求和以获得 h i = ∑ j m j i h_i=∑_j m_{ji} hi=∑jmji,然后使用多个密集(全连接)层对其进行变换以生成逐个原子的输出 t i ( l ) t^{(l)}_i ti(l)。然后将这些输出相加以获得最终预测 t = ∑ i ∑ l t i ( l ) t=\sum_i\sum_l t^{(l)}_i t=∑i∑lti(l)。
连续可微性:
多个模型选择是实现两倍连续模型可微性所必需的。首先,DimeNet使用自门控Swish激活函数 ϕ ( x ) = x ⋅ s i g m o i d ( x ) \phi(x)=x·sigmoid(x) ϕ(x)=x⋅sigmoid(x)而不是常规的ReLU激活函数。其次,我们将径向基函数 e ~ R B F \tilde{e} _{\mathrm{RBF}} e~RBF 乘以包络函数 u ( d ) u(d) u(d),该包络函数 u ( d ) u(d) u(d)在截止c处具有3重根。最后,DimeNet不使用任何辅助数据,而仅依赖于原子类型和位置。
七、实验
模型:
有关超参数选择和训练设置,请参见附录B。我们使用6个最先进的模型进行比较:SchNet(Schütt等人,2017年)、PhysNet(基于参考实现的结果)(Unke&Meuwly,2019年)、可证明强大的图网络(PPGN,原作者提供的结果)(Maron等人,2019年)、MEGNet-simple(无辅助信息)(Chen等人,2019a)、Cormorant(Anderson等人,2019年)和对称梯度域机器学习(sGDML)(Chmiela等人,2018年)。
注意,sGDML不能用于QM9,因为它只能在单个分子上训练。
biao 1:
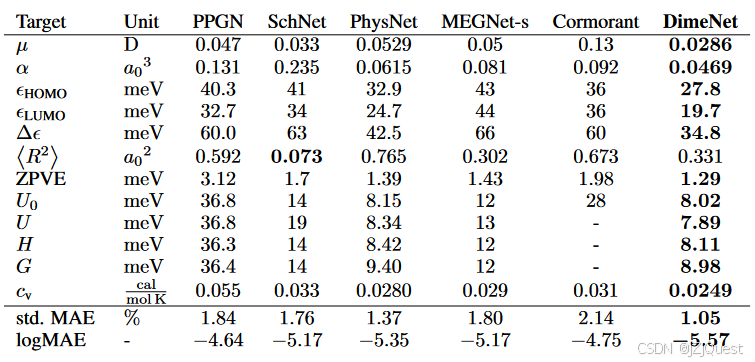
MAE在QM9上。DimeNet在11个目标上设定了最先进的水平,平均优于第二好的模型31%(平均标准 MAE)。
QM9
我们在训练中使用110 000个分子,在验证中使用10 000个分子,在测试集中使用10 831个分子。我们仅使用U0、U、H和G的原子化能,即减去原子参考能量,这些能量对于每种原子类型是恒定的,并使用eV执行训练。在表1中,我们报告了每个目标的平均绝对误差(MAE)和总体平均标准化MAE(Std.MAE)和平均标准化logMAE(详情见附录C)。我们简单地通过取 ϵ L U M O − ϵ H O M O \epsilon_{LUMO}-\epsilon_{HOMO} ϵLUMO−ϵHOMO 来预测 ϵ \epsilon ϵ,因为它是通过DFT计算以这种方式计算的。我们为每个目标训练一个单独的模型,与为所有目标训练一个共享模型相比,这显著改善了结果(见附录E)。DimeNet在12个目标中的11个上设定了新的技术水平,并降低了平均std。与第二好的模型相比,MAE提高了31%,平均logMAE提高了0.22。
MD17:
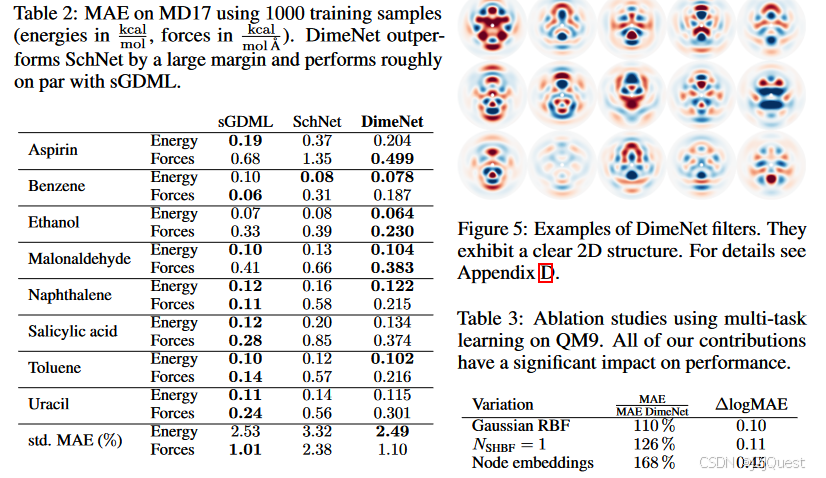
我们使用MD17(Chmiela等人,2017)来测试分子动力学模拟中的模型性能。该基准的目标是预测八个有机小分子的能量和原子力,给定热化(即非平衡、轻微移动)系统的原子坐标。地面实况数据通过使用DFT的分子动力学模拟来计算。为每个分子训练单独的模型,目标是提供高度准确的个体预测。该数据集通常用于50 000个训练样本和10 000个验证和测试样本。我们发现DimeNet可以在这种设置中匹配最先进的性能。例如。对于苯,根据力重量ρ,DimeNet的能量达到0.035 kcal mol−1 MAE,能量和力达到0.07 kcal mol−1和0.17 kcal mol−1Å−1,与Anderson等人报告的结果相匹配。(2019)和Unke&Meuwly(2019)。然而,这种精度比DFT计算的精度低两个数量级(大约。2.3 kcal mol-1的能量(Faber等人,2017年)),因此与真实世界数据的任何剩余差异几乎完全是由于DFT模拟中的误差。因此,只有通过更精确的地面实况数据才能真正达到更好的精度,这需要更昂贵的方法(例如CCSD(T)),因此需要样本效率更高的ML模型(Chmiela等人,2018)。因此,我们转而在仅使用1000个训练样本的更困难的任务上测试我们的模型。如表2所示,DimiNet的性能远远优于SchNet,并且与sGDML的性能大致相当。然而,sGDML使用手工设计的描述符,为小数据集提供了强大的优势,只能在单个分子(一组固定的原子)上训练,并且不能很好地随着原子或训练样本的数量而扩展。
消融研究:
点击下面的链接(obsidian)查看消融研究的详述。
[[消融研究]]
为了测试定向消息传递和傅立叶-贝塞尔基是否是DimeNet性能提高的实际原因,我们单独消融它们,并比较QM9上多任务学习的平均标准化MAE和logMAE。表3显示,我们的两个贡献对模型的性能都有显著影响。使用64个高斯RBF代替16和6个贝塞尔基函数来表示d_ji和d_kj,误差增加了10%,这表明该基不仅减少了参数的数量,而且还提供了有用的归纳偏差。当我们通过设置NSHBF=1来忽略消息之间的角度时,DimeNet的错误增加了约26%,这表明直接合并方向信息确实提高了性能。使用节点嵌入而不是消息嵌入(因此也忽略了方向信息)具有最大的影响,并使MAE增加了68%,此时DimeNet的性能比SchNet差。此外,图5示出了滤波器表现出对距离和角度两者的结构上有意义的依赖性。例如,这些过滤器中的一些显然是由苯环激活的(120°角,1.39Å距离)。这进一步证明了该模型学习利用方向信息。
八、总结
在这项工作中,我们介绍了定向信息传递,这是一种用于分子预测的更强大和更具表现力的交互方案。除了普通GNN使用的原子间距离之外,定向消息传递使图形神经网络能够利用定向信息。我们已经表明,原子间距离可以用球形贝塞尔函数以有原则和有效的方式表示。此外,我们已经表明,通过利用2D球面傅立叶-贝塞尔基函数,这种表示可以扩展到方向信息。我们利用这些创新构建了DimeNet,这是一个既适合预测分子性质又适合用于分子动力学模拟的GNN。我们已经在QM9和MD17上展示了DimeNet的性能,并表明我们的贡献是实现DimeNet最先进性能的基本要素。DimeNet直接模拟等式中的前两项。1,它们被称为分子中重要的“硬”自由度(Leach,2001)。未来的工作应旨在纳入该等式的第三项和第四项。这可以进一步改善预测,并使其能够应用于比QM9等常见基准中使用的分子大得多的分子。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









