







系列文章目录
第一章 YOLOv5模型训练集标注、训练流程
第二章 YOLOv5模型转ONNX,ONNX转TensorRT Engine
第三章 TensorRT量化
前言
学习笔记–恩培老师
一、yolov5模型导出ONNX
1.1 工作机制
使用tensort deconde plugin 来替代yolov5代码中的deconde操作,需要修改yolov5代码导出onnx模型的部分。
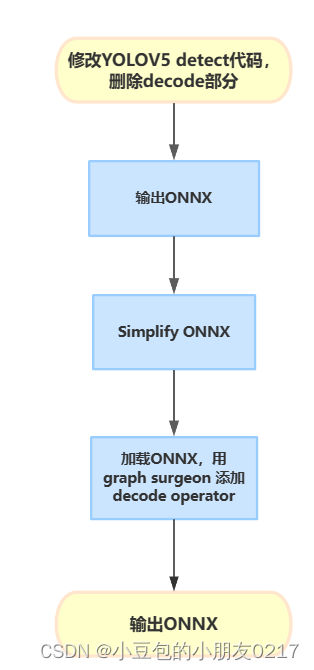
1.2 修改yolov5代码,输出ONNX
首先把Yolov5训练好的权重文件放进weights文件夹中,并命名为yolov5s_person.pt。
使用以下命令导出原始操作的onnx模型,以便和修改后的模型进行对比。
python export.py --weights weights/yolov5s_person.pt --include onnx --simplify --dynamic
如果报这种错就去export.py中改opset的版本
root@autodl-container-825011bf52-acd7f065:~/yolov5# python export.py --weights weights/yolov5s_person.pt --include onnx --simplify --dynamic
export: data=data/coco128.yaml, weights=['weights/yolov5s_person.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, keras=False, optimize=False, int8=False, per_tensor=False, dynamic=True, simplify=True, opset=17, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx']
YOLOv5 🚀 v7.0-274-g7d9a117 Python-3.8.10 torch-1.10.0+cu113 CPU
Fusing layers...
YOLOv5s_person summary: 213 layers, 7023610 parameters, 0 gradients, 15.8 GFLOPs
PyTorch: starting from weights/yolov5s_person.pt with output shape (1, 25200, 10) (13.8 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export failure ❌ 0.1s: Unsupported ONNX opset version: 17
root@autodl-container-825011bf52-acd7f065:~/yolov5#

参考https://blog.csdn.net/weixin_45303602/article/details/133608711
批量修改
#将patch复制到yolov5文件夹
cp export.patch yolov5/
#进入yolov5文件夹
cd yolov5/
#应用patch
git am export.patch
如果报以下错误的话就是没设置用户信息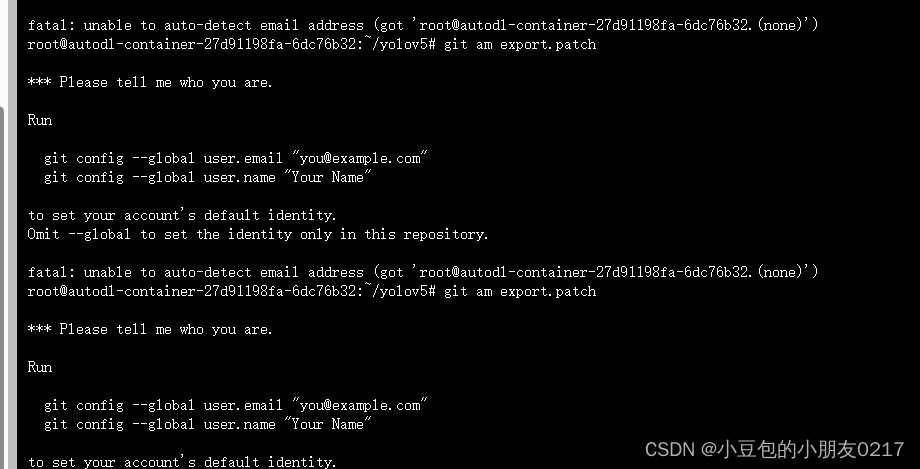
git config --global user.email "you@example.com"
git config --global user.name "Your Name"
完成设置后,再次尝试应用补丁命令。
如果出现:fatal: not a git repository (or any of the parent directories): .git
你当前所在的目录不是 Git 仓库或者你没有在 Git 仓库中执行该命令。
需要先进入到 Git 仓库所在的目录,然后再执行该命令。如果你不确定当前目录是否为 Git 仓库,可以使用 git status 命令来检查。
git有关用法可参考:https://blog.csdn.net/m0_70420861/article/details/135439659?spm=1001.2014.3001.5502
具体修改细节
在models/yolo.py文件,需要修改class Detect的forward方法,以删除其box decode运算,以直接输出网络结果。在后面的tensorrt部署中,我们将利用decode plugin来进行decode操作,并用gpu加速。修改内容如下:
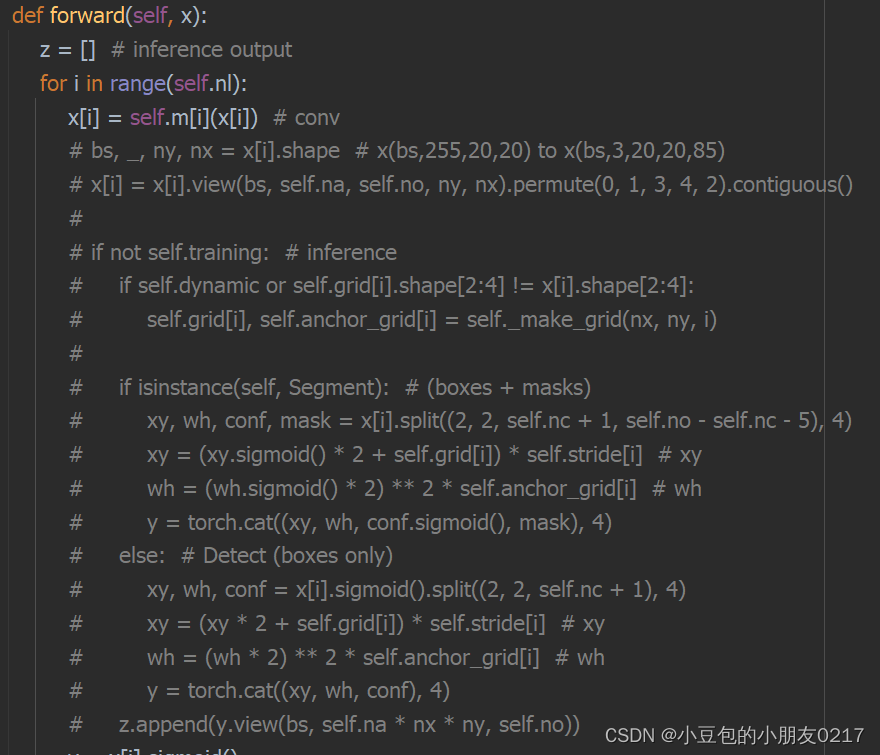
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
#
# if not self.training: # inference
# if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
# self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
#
# if isinstance(self, Segment): # (boxes + masks)
# xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)
# xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xy
# wh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # wh
# y = torch.cat((xy, wh, conf.sigmoid(), mask), 4)
# else: # Detect (boxes only)
# xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
# xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
# wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
# y = torch.cat((xy, wh, conf), 4)
# z.append(y.view(bs, self.na * nx * ny, self.no))
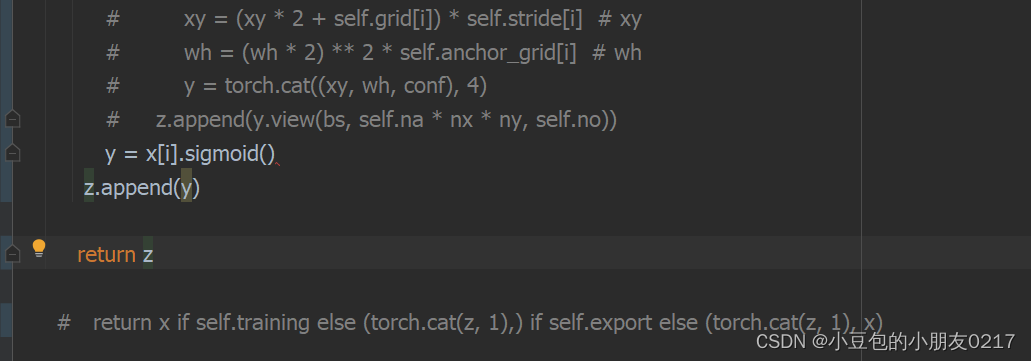
y = x[i].sigmoid()
z.append(y)
return z
# return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
可以看到这里删除了主要的运算部分,将模型输出直接作为list返回。修改后,onnx的输出将被修改为三个原始网络输出,我们需要在输出后添加decode plugin的算子。先导出onnx,再利用nvidia的graph surgeon来修改onnx。首先修改onnx export部分代码:
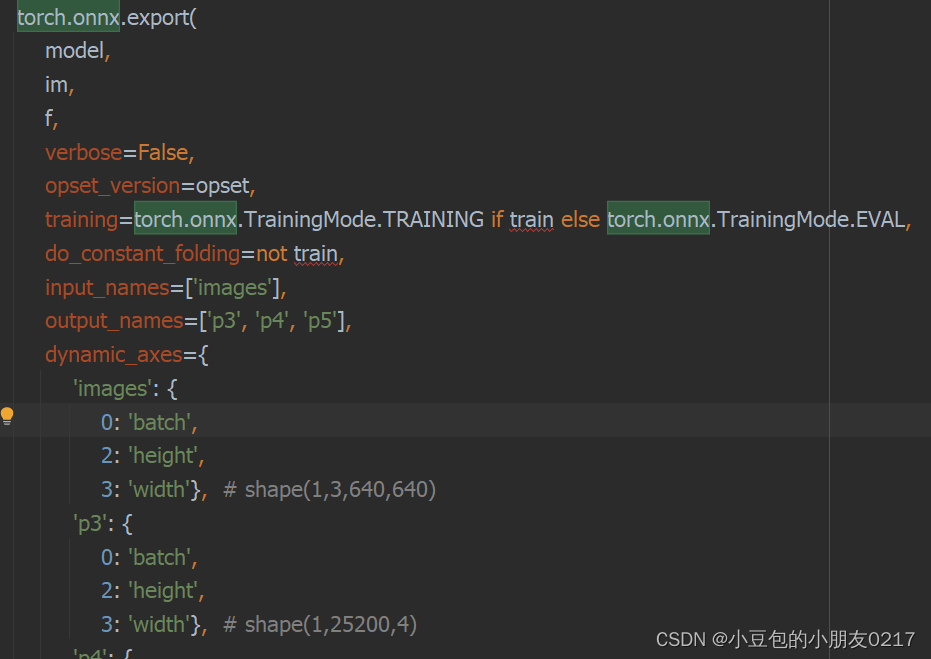
torch.onnx.export(
model,
im,
f,
verbose=False,
opset_version=opset,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['p3', 'p4', 'p5'],
dynamic_axes={
'images': {
0: 'batch',
2: 'height',
3: 'width'}, # shape(1,3,640,640)
'p3': {
0: 'batch',
2: 'height',
3: 'width'}, # shape(1,25200,4)
'p4': {
0: 'batch',
2: 'height',
3: 'width'},
'p5': {
0: 'batch',
2: 'height',
3: 'width'}
} if dynamic else None)
安装需要依赖
pip install seaborn
pip install onnx-graphsurgeon
pip install opencv-python==4.5.5.64
pip install onnx-simplifier==0.3.10
apt update
apt install -y libgl1-mesa-glx
安装完成后,准备训练好的模型文件,默认为yolov5s.pt,然后执行下列代码,生成Onnx文件。
安装不上onnx-graphsurgeon,使用下面的命令再次安装
pip install nvidia-pyindex
pip install onnx-graphsurgeon
python export.py --weights weights/yolov5s.pt --include onnx --simplify --dynamic
这里的yolov5s_person.pt文件就是我们刚刚训练好的best.pt复制过来的。
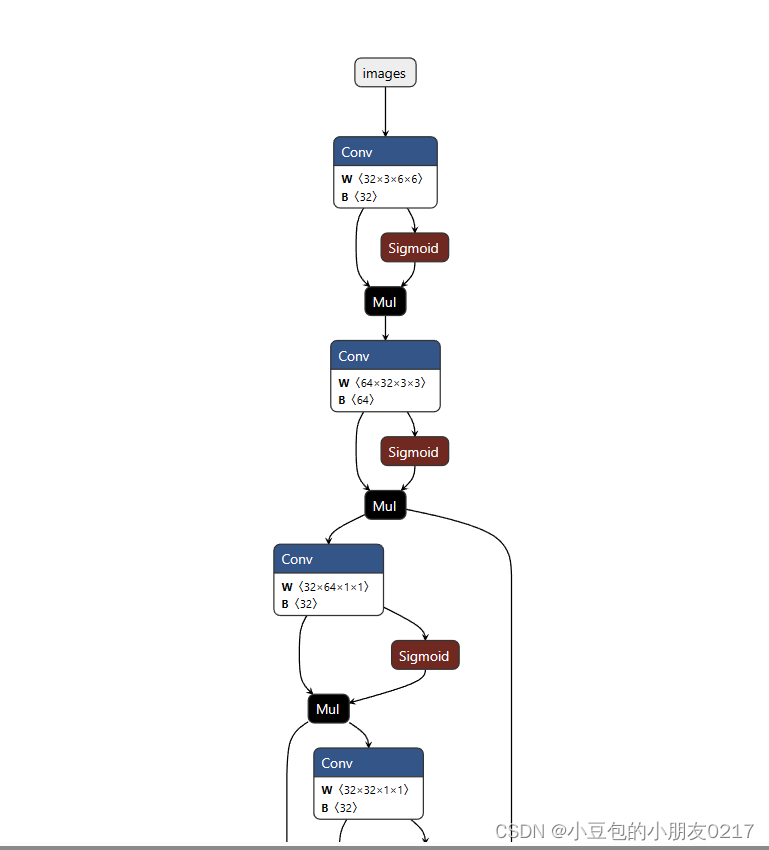
可视化模型工具
pip install netron
netron ./weights/yolov5s_person.onnx
二、TensorRT部署
2.1 模型部署
推荐博客TensorRT部署流程
yolov5转到onnx后进行模型的构建并保存序列化后的模型为文件。
- 模型导出成 ONNX 格式。
- 把 ONNX 格式模型输入给 TensorRT,并指定优化参数。
- 使用 TensorRT 优化得到 TensorRT Engine。
- 使用 TensorRT Engine 进行 inference。
- 创建builder
这里使用了std::unqique_ptr,只能指针包装我们的builder,实现自动管理指针生命周期。
// =========== 1. 创建builder ===========
auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
if (!builder)
{
std::cerr << "Failed to create builder" << std::endl;
return -1;
}
- 创建网络。这里指定了explicitBatch
// ========== 2. 创建network:builder--->network ==========
// 显性batch
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 调用builder的createNetworkV2方法创建network
auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{
std::cout << "Failed to create network" << std::endl;
return -1;
}
- 创建onnxparser,用于解析onnx文件
auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));
// 调用onnxparser的parseFromFile方法解析onnx文件
auto parsed = parser->parseFromFile(onnx_file_path, static_cast<int>(sample::gLogger.getReportableSeverity()));
if (!parsed)
{
std::cout << "Failed to parse onnx file" << std::endl;
return -1;
}
- 创建config。用于模型构建的参数配置
// ========== 3. 创建config配置:builder--->config ==========
auto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
std::cout << "Failed to create config" << std::endl;
return -1;
}
- 配置网络参数。
需要告诉tensorrt我们最终运行时,输入图像的范围,batch size范围。
auto input = network->getInput(0);
auto profile = builder->createOptimizationProfile();
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, nvinfer1::Dims4{1, 3, 640, 640});
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, nvinfer1::Dims4{1, 3, 640, 640});
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, nvinfer1::Dims4{1, 3, 640, 640});
// 使用addOptimizationProfile方法添加profile,用于设置输入的动态尺寸
config->addOptimizationProfile(profile);
// 设置精度,不设置是FP32,设置为FP16,设置为INT8需要额外设置calibrator
config->setFlag(nvinfer1::BuilderFlag::kFP16);
builder->setMaxBatchSize(1);
// 设置最大工作空间(最新版本的TensorRT已经废弃了setWorkspaceSize)
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30);
// 7. 创建流,用于设置profile
auto profileStream = samplesCommon::makeCudaStream();
if (!profileStream) { return -1; }
config->setProfileStream(*profileStream);
- 模型序列化,并进行保存
// ========== 4. 创建engine:builder--->engine(*nework, *config) ==========
// 使用buildSerializedNetwork方法创建engine,可直接返回序列化的engine(原来的buildEngineWithConfig方法已经废弃,需要先创建engine,再序列化)
auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));
if (!plan)
{
std::cout << "Failed to create engine" << std::endl;
return -1;
}
// ========== 5. 序列化保存engine ==========
std::ofstream engine_file("./weights/yolov5.engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
engine_file.write((char *)plan->data(), plan->size());
engine_file.close();
-
释放资源
因为使用了智能指针,所以不需要手动释放资源
完整build.cu代码
#include "NvInfer.h"
#include "NvOnnxParser.h" // onnxparser头文件
#include "logger.h"
#include "common.h"
#include "buffers.h"
#include "cassert"
// main函数
int main(int argc, char **argv)
{
if (argc != 2)
{
std::cerr << "用法: ./build [onnx_file_path]" << std::endl;
return -1;
}
// 命令行获取onnx文件路径
char *onnx_file_path = argv[1];
// =========== 1. 创建builder ===========
auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
if (!builder)
{
std::cerr << "Failed to create builder" << std::endl;
return -1;
}
// ========== 2. 创建network:builder--->network ==========
// 显性batch
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 调用builder的createNetworkV2方法创建network
auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{
std::cout << "Failed to create network" << std::endl;
return -1;
}
// 与上节课手动创建网络不同,这次使用onnxparser创建网络
// 创建onnxparser,用于解析onnx文件
auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));
// 调用onnxparser的parseFromFile方法解析onnx文件
auto parsed = parser->parseFromFile(onnx_file_path, static_cast<int>(sample::gLogger.getReportableSeverity()));
if (!parsed)
{
std::cout << "Failed to parse onnx file" << std::endl;
return -1;
}
// 配置网络参数
// 我们需要告诉tensorrt我们最终运行时,输入图像的范围,batch size的范围。这样tensorrt才能对应为我们进行模型构建与优化。
auto input = network->getInput(0); // 获取输入节点
auto profile = builder->createOptimizationProfile(); // 创建profile,用于设置输入的动态尺寸
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, nvinfer1::Dims4{1, 3, 640, 640}); // 设置最小尺寸
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, nvinfer1::Dims4{1, 3, 640, 640}); // 设置最优尺寸
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, nvinfer1::Dims4{1, 3, 640, 640}); // 设置最大尺寸
// ========== 3. 创建config配置:builder--->config ==========
auto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
std::cout << "Failed to create config" << std::endl;
return -1;
}
// 使用addOptimizationProfile方法添加profile,用于设置输入的动态尺寸
config->addOptimizationProfile(profile);
// 设置精度,不设置是FP32,设置为FP16,设置为INT8需要额外设置calibrator
config->setFlag(nvinfer1::BuilderFlag::kFP16);
// 设置最大batchsize
builder->setMaxBatchSize(1);
// 设置最大工作空间(新版本的TensorRT已经废弃了setWorkspaceSize)
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30);
// 创建流,用于设置profile
auto profileStream = samplesCommon::makeCudaStream();
if (!profileStream)
{
return -1;
}
config->setProfileStream(*profileStream);
// ========== 4. 创建engine:builder--->engine(*nework, *config) ==========
// 使用buildSerializedNetwork方法创建engine,可直接返回序列化的engine(原来的buildEngineWithConfig方法已经废弃,需要先创建engine,再序列化)
auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));
if (!plan)
{
std::cout << "Failed to create engine" << std::endl;
return -1;
}
// ========== 5. 序列化保存engine ==========
std::ofstream engine_file("./weights/yolov5.engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
engine_file.write((char *)plan->data(), plan->size());
engine_file.close();
// ========== 6. 释放资源 ==========
// 因为使用了智能指针,所以不需要手动释放资源
std::cout << "Engine build success!" << std::endl;
return 0;
}
2.2 模型推理
推理过程
- 读取模型文件
- 对输入进行预处理
- 读取模型输出
- 后处理(NMS)
1.创建运行时
2.反序列化模型得到推理Engine
3.创建执行上下文
4.创建输入输出缓冲区管理器
5.读取视频文件,并逐帧读取图像送入模型,进行推理
- 创建运行时
// ========= 1. 创建推理运行时runtime =========
auto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(sample::gLogger.getTRTLogger()));
if (!runtime)
{
std::cout << "runtime create failed" << std::endl;
return -1;
}
- 反序列化模型得到推理Engine
// ======== 2. 反序列化生成engine =========
// 加载模型文件
auto plan = load_engine_file(engine_file);
// 反序列化生成engine
auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan.data(), plan.size()));
if (!mEngine)
{
return -1;
}
- 创建执行上下文
// ======== 3. 创建执行上下文context =========
auto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{
std::cout << "context create failed" << std::endl;
return -1;
}
- 创建输入输出缓冲区管理器
samplesCommon::BufferManager buffers(mEngine);
- 读取视频文件,并逐帧读取图像,送入模型中,进行推理
- 首先对输入图像进行预处理,这实现对输入图像处理的gpu 加速。
- 预处理完成后,我们调用推理api executeV2,进行模型推理,并将模型输出拷贝到cpu
- 最后我们从buffer manager中获取模型输出,并执行nms,得到最后的检测框
- 依次将检测框画到图像上,再打印对应的fps和推理时间。并显示图像
完整runtime代码如下:
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include "logger.h"
#include "common.h"
#include "buffers.h"
#include "utils/preprocess.h"
#include "utils/postprocess.h"
#include "utils/types.h"
// 加载模型文件
std::vector<unsigned char> load_engine_file(const std::string &file_name)
{
std::vector<unsigned char> engine_data;
std::ifstream engine_file(file_name, std::ios::binary);
assert(engine_file.is_open() && "Unable to load engine file.");
engine_file.seekg(0, engine_file.end);
int length = engine_file.tellg();
engine_data.resize(length);
engine_file.seekg(0, engine_file.beg);
engine_file.read(reinterpret_cast<char *>(engine_data.data()), length);
return engine_data;
}
int main(int argc, char **argv)
{
if (argc < 3)
{
std::cerr << "用法: " << argv[0] << " <engine_file> <input_path_path>" << std::endl;
return -1;
}
auto engine_file = argv[1]; // 模型文件
auto input_video_path = argv[2]; // 输入视频文件
// ========= 1. 创建推理运行时runtime =========
auto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(sample::gLogger.getTRTLogger()));
if (!runtime)
{
std::cout << "runtime create failed" << std::endl;
return -1;
}
// ======== 2. 反序列化生成engine =========
// 加载模型文件
auto plan = load_engine_file(engine_file);
// 反序列化生成engine
auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan.data(), plan.size()));
if (!mEngine)
{
return -1;
}
// ======== 3. 创建执行上下文context =========
auto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{
std::cout << "context create failed" << std::endl;
return -1;
}
// ========== 4. 创建输入输出缓冲区 =========
samplesCommon::BufferManager buffers(mEngine);
auto cap = cv::VideoCapture(input_video_path);
int width = int(cap.get(cv::CAP_PROP_FRAME_WIDTH));
int height = int(cap.get(cv::CAP_PROP_FRAME_HEIGHT));
int fps = int(cap.get(cv::CAP_PROP_FPS));
// 写入MP4文件,参数分别是:文件名,编码格式,帧率,帧大小
cv::VideoWriter writer("./output/record.mp4", cv::VideoWriter::fourcc('H', '2', '6', '4'), fps, cv::Size(width, height));
cv::Mat frame;
int frame_index{0};
// 申请gpu内存
cuda_preprocess_init(height * width);
while (cap.isOpened())
{
// 统计运行时间
auto start = std::chrono::high_resolution_clock::now();
cap >> frame;
if (frame.empty())
{
std::cout << "文件处理完毕" << std::endl;
break;
}
frame_index++;
// 输入预处理(实现了对输入图像处理的gpu 加速)
process_input(frame, (float *)buffers.getDeviceBuffer(kInputTensorName));
// ========== 5. 执行推理 =========
context->executeV2(buffers.getDeviceBindings().data());
// 拷贝回host
buffers.copyOutputToHost();
// 从buffer manager中获取模型输出
int32_t *num_det = (int32_t *)buffers.getHostBuffer(kOutNumDet); // 检测到的目标个数
int32_t *cls = (int32_t *)buffers.getHostBuffer(kOutDetCls); // 检测到的目标类别
float *conf = (float *)buffers.getHostBuffer(kOutDetScores); // 检测到的目标置信度
float *bbox = (float *)buffers.getHostBuffer(kOutDetBBoxes); // 检测到的目标框
// 执行nms(非极大值抑制),得到最后的检测框
std::vector<Detection> bboxs;
yolo_nms(bboxs, num_det, cls, conf, bbox, kConfThresh, kNmsThresh);
// 结束时间
auto end = std::chrono::high_resolution_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
auto time_str = std::to_string(elapsed) + "ms";
auto fps_str = std::to_string(1000 / elapsed) + "fps";
// 遍历检测结果
for (size_t j = 0; j < bboxs.size(); j++)
{
cv::Rect r = get_rect(frame, bboxs[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
cv::putText(frame, std::to_string((int)bboxs[j].class_id), cv::Point(r.x, r.y - 10), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0x27, 0xC1, 0x36), 2);
}
cv::putText(frame, time_str, cv::Point(50, 50), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
cv::putText(frame, fps_str, cv::Point(50, 100), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
// cv::imshow("frame", frame);
// 写入视频文件
writer.write(frame);
std::cout << "处理完第" << frame_index << "帧" << std::endl;
if (cv::waitKey(1) == 27)
break;
}
// ========== 6. 释放资源 =========
// 因为使用了unique_ptr,所以不需要手动释放
return 0;
}
模型部署相关知识可参考TensorRT(C++)
使用cmake进行构建,cmake相关知识可参考cmake学习笔记
cmake -S .-B build
cmake --build build
./build/build
./build/build ./weights/yolo5s_person.onnx
#执行推理
./build/runtime
视频文件
./weights/yolov5.engine ./media/c3.mp4
总结
接下来是了解TensorRT插件,Int8量化流程。
推荐链接:https://github.com/NVIDIA/trt-samples-for-hackathon-cn/tree/master/cookbook















 3963
3963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









