






技术背景
说到向量数据库就得提到Embedding技术,在人工智能的机器学习和深度学习领域,Embedding指的是将高维离散数据(如词汇、物品、用户等)映射到低维连续向量空间中的技术。下面我们用两个例子来对Embedding进行示意说明:
| 水果 | 甜度 | 酸度 | 向量值 |
|---|---|---|---|
| 苹果 | 0.7 | -0.3 | [0.7,0.3] |
| 梨 | 0.8 | -0.2 | [0.8,0.2] |
| 桃子 | 0.6 | -0.5 | [0.6,-0.5] |
| 葡萄 | 0.9 | -0.2 | [0.9,-0.2] |
| 西瓜 | 0.6 | -0.1 | [0.6,-0.1] |
| 柠檬 | 0.4 | 0.8 | [0.4,0.8] |
上面只是一个简单物品量化的例子,实际中的维度或特征可能会有几百上千个。
根据上面的数据集,我们就可以进行我们的实验了,假设甜度为0.6,酸度为-0.3为最适宜食用的水果标准的话。那当我们向机器提问苹果、梨、桃子、葡萄、西瓜、柠檬这6种食物哪个最推荐食用? 机器就可以通过向量计算(相似度/相关度)出最接近水果食用标准的水果,如下图所示:绿色为标准,离他最近的是红色线苹果
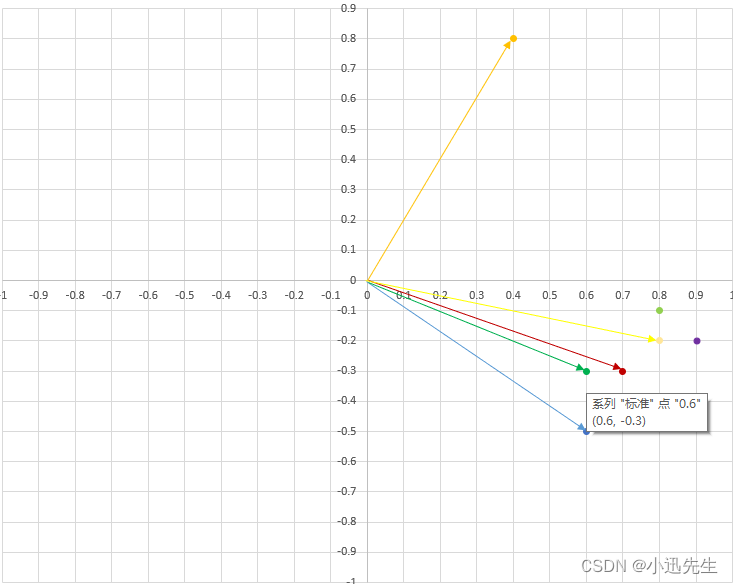
向量距离有两种算法,两个坐标点的距离(欧氏距离),或者向量夹角大小(余弦夹角);
Chroma 简介
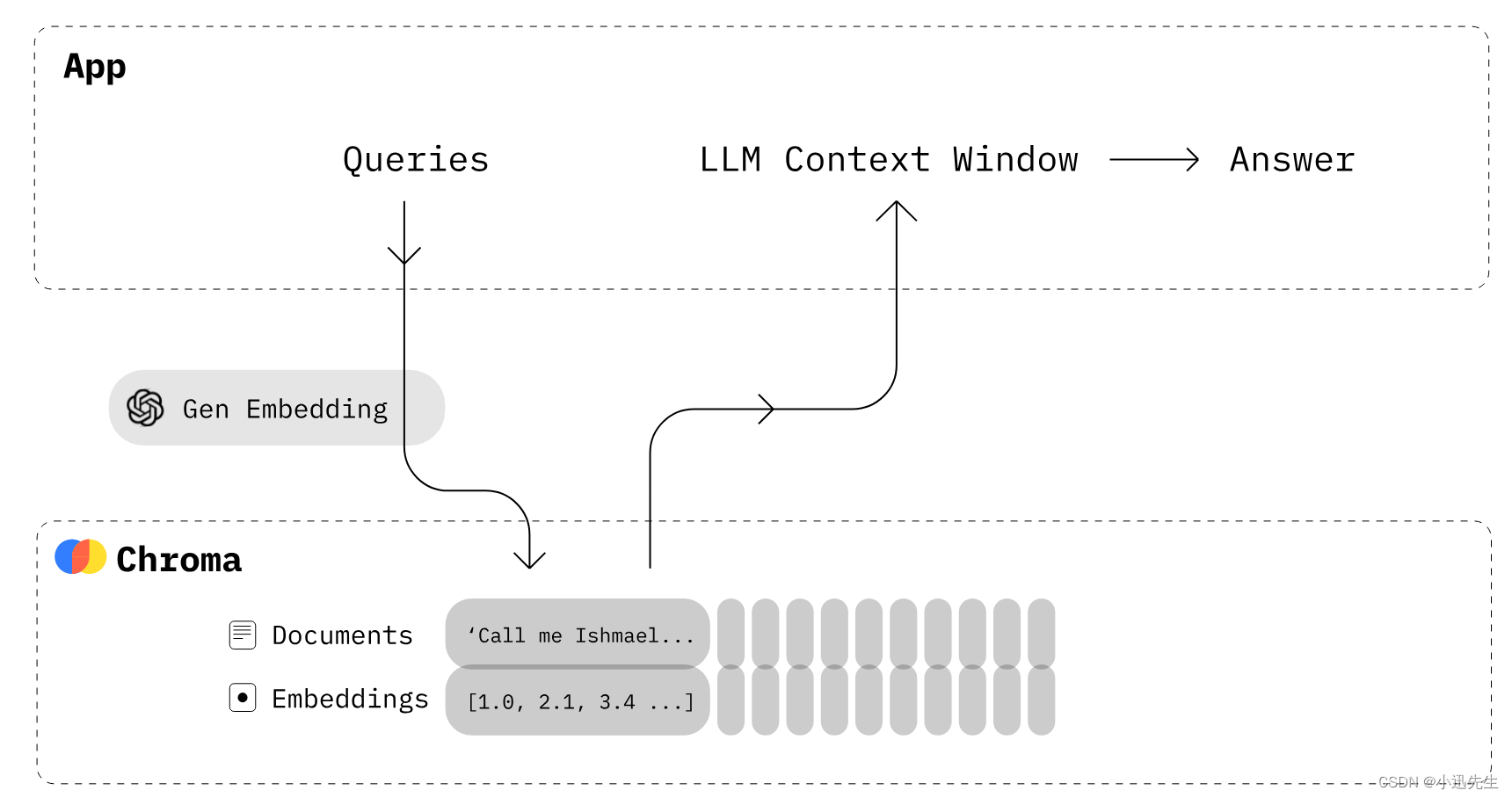
Chroma是人工智能原生开源向量数据库。它可以通过使知识、事实等数据向量化到LLM,让构建LLM的应用程序变得容易,详细内容可以点击官网地址进行查阅。
安装及使用
安装Chroma
按照下面命令进行Chroma安装
pip install chromadb
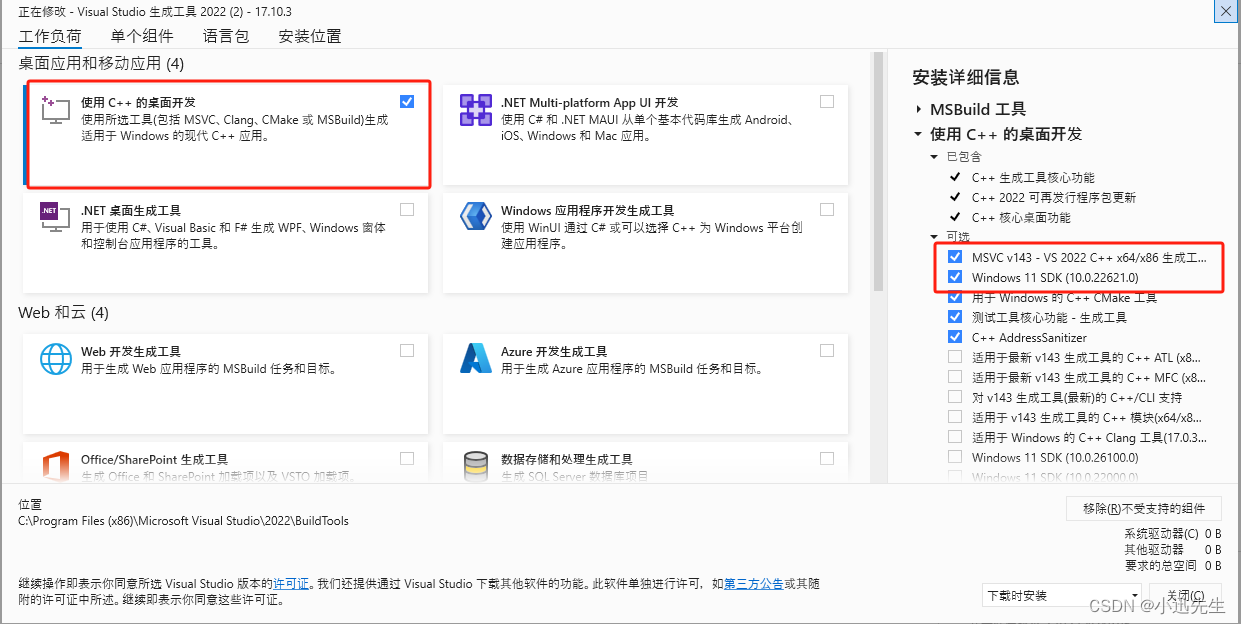
你可能会碰到Microsoft Visual C++ 14.0 or greater is required这个异常,直接按照异常建议的下载地址,下载vs_BuildTools.exe,并点击安装c++桌面程序即可,如下图所示:
运行Chroma
按照下面命令,运行Chroma
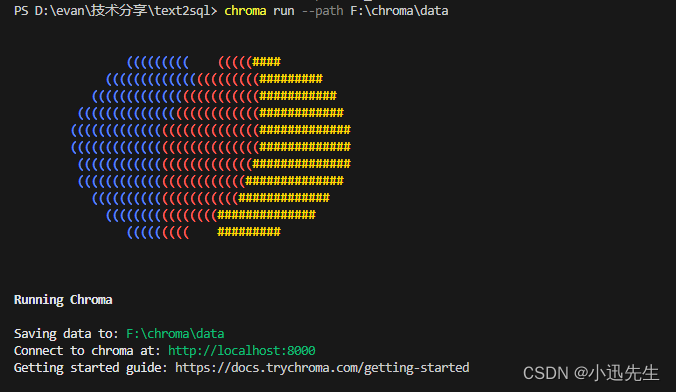
chroma run --path F:\chroma\data
将上面数据路径改成自己的地址即可运行,运行后,可以看到下面的效果:
新增并查询向量数据
按上面命令启动Chroma后,我们可以按下面代码进行测试:
import chromadb
chroma_client = chromadb.Client()
# chroma_client = chromadb.HttpClient(host='localhost', port=8000)
collection = chroma_client.create_collection(name="demo")
#chroma_client = chromadb.PersistentClient(path="/path/to/save/to") # 设置持久化路径
# 添加文档、嵌入向量和元数据到集合中
collection.add(
documents=["苹果", "梨", "桃子", "葡萄", "西瓜", "柠檬"],
metadatas=[{"sweetness": "甜度", "acidity": "酸度"}] * 6, # 使用列表乘法重复元数据字典
embeddings=[[0.7, -0.3], [0.8, -0.2], [0.6, -0.4], [0.9, -0.2], [0.6, -0.1], [0.4, 0.8]],
ids=["A1", "A2", "A3", "A4", "A5", "A6"]
)
#获取查看添加的向量数据
result=collection.get(
ids=["A1", "A2","A3","A4","A5","A6"],
include=["metadatas", "documents", "embeddings"] # 明确指定包含嵌入向量(默认不会返回embeddings)
)
print(result)
运行代码效果如下:

chroma的详细使用,可以去官网查阅(上面已经提供过地址了)。
总结
向量数据库是支撑现代AI技术,特别是RAG等高级应用的关键基础设施之一,它通过优化数据管理和检索过程,增强了AI应用的效率、准确性和实用性。















 1997
1997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









