






其第三代文生图大模型 Stable Diffusion 3。该模型展现出了超越现有文本到图像生成系统的强大性能,为文本到图像生成技术带来了重大突破。
今天,Stability AI 终于发布了 Stable Diffusion 3 技术报告,帮助我们一窥 Stable Diffusion 3 背后的技术细节。报告要点如下:
众所周知,Stable Diffusion 3 在排版和提示遵循等方面表现出色,超越了 DALL·E 3、Midjourney v6 和 Ideogram v1 等最先进的文本到图像生成系统。其中:
与其他开放模型和封闭源系统相比,Stable Diffusion 3 在视觉美观度、提示遵循和排版等方面表现出色。
Stable Diffusion 3 采用了重新加权的矩形流形式,以改善模型性能。与其他矩形流形式相比,它的表现更为稳定。
新的多模态扩散 Transformer(Multimodal Diffusion Transformer,MMDiT)架构使用独立的权重集合来处理图像和语言表示,相比于之前的版本,改善了文本理解和拼写能力。
MMDiT 架构结合了 DiT 和矩形流(RF)形式。它使用两个独立的变换器来处理文本和图像嵌入,并在注意力操作中结合两种模态的序列。
MMDiT 架构不仅适用于文本到图像生成,还可以扩展到多模态数据,比如视频。
移除内存密集型的 T5 文本编码器可以显著减少 SD3 的内存需求,仅伴随少量性能损失。

图|来自 8B 整流模型的高分辨率样本,展示了其在排版、精确的提示跟随和空间推理,对细节的关注以及各种风格的高图像质量方面的能力。
完整技术报告链接:
https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf
接下来,让我们结合报告,一窥 Stable Diffusion 3 背后的技术细节。
MMDiT架构:Stable Diffusion 3背后的关键技术
MMDiT 架构是 Stable Diffusion 3 背后的关键技术之一。相比传统的单一模态处理方法,MMDiT 架构能够更好地处理文本和图像之间的关系,从而实现更准确、更高质量的图像生成。
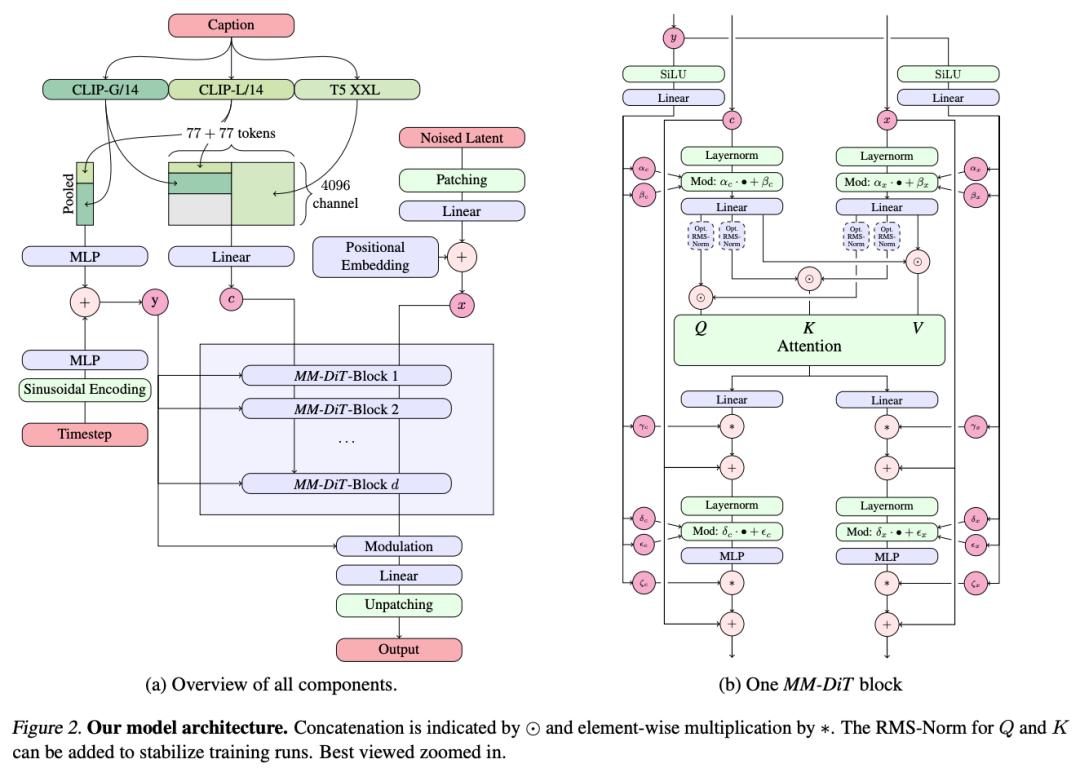
图|模型架构。
这一架构采用了独立的权重集合来处理图像和语言表示,这意味着对于文本和图像两种不同的输入模态,MMDiT 分别使用不同的权重参数来进行编码和处理,以此能够更好地捕捉每种模态的特征和信息。
在 MMDiT 架构中,文本和图像的表示分别通过预训练模型进行编码。具体地说,MMDiT 采用了三种不同的文本嵌入器(两个 CLIP 模型和 T5 模型),以及一个改进的自动编码模型来编码图像 token。这些编码器能够将文本和图像输入转换为模型可以理解和处理的格式,为后续的图像生成过程提供了基础。

图|T5 对于复杂提示非常重要,例如,涉及高度细节或较长的拼写文本(第 2 行和第 3 行)。然而,对于大多数提示,在推理时删除 T5 仍然可以达到具有竞争力的性能。
在模型结构上,MMDiT 架构建立在 Diffusion Transformer(DiT)的基础上。由于文本和图像的表示在概念上有所不同,MMDiT 使用了两组独立的权重参数来处理这两种模态。这样一来,模型能够在文本和图像的表示空间中分别进行操作,同时又能够考虑到彼此之间的关联关系,从而实现更好的信息传递和整合。
性能碾压其他文生图模型
通过与其他文本到图像生成模型进行性能比较,Stable Diffusion 3 展现出了明显的优势。在视觉美感、文本遵循和排版等方面,Stable Diffusion 3 都能够超越包括 DALL·E 3、Midjourney v6 和 Ideogram v1 在内的最先进系统。
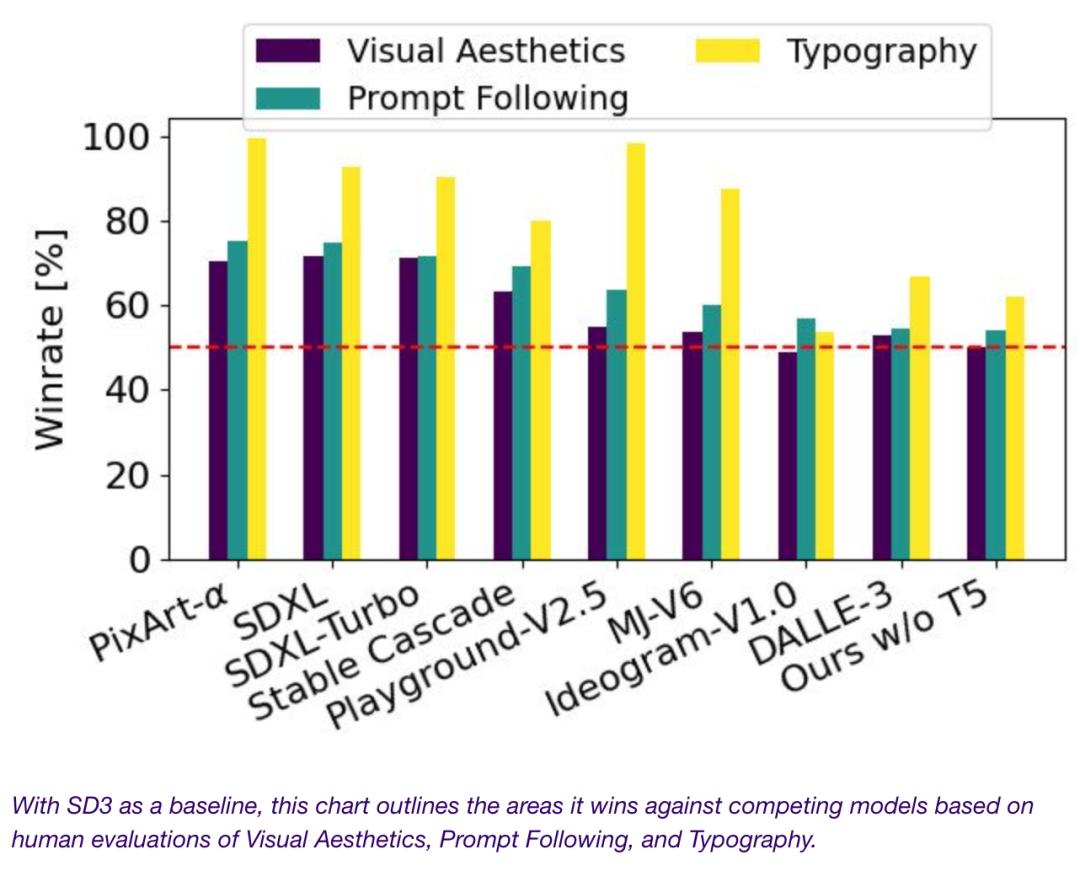
这一优势主要归功于 MMDiT 架构对图像和文本表示的独立处理,使得模型能够更好地理解和表达文本提示,并生成与之匹配的高质量图像。通过人类评估者提供的例子输出进行比较,Stable Diffusion 3 在视觉美感方面与其他模型相比表现出色。评估者被要求根据图像的美观程度选择最佳结果。结果显示,Stable Diffusion 3 在生成的图像美观度方面优于其他模型。

图|这是一幅异想天开、富有创意的图像,描绘了一种混合了华夫饼和河马的生物。这种富有想象力的生物有着河马独特的、笨重的身体,但它的外观却像一块金棕色的脆皮华夫饼。该生物的皮肤上有华夫饼,还有糖浆般的光泽。这设置在一个超现实的环境中,有趣地结合了河马的自然水域栖息地和早餐餐桌,包括超大的餐具或盘子作为背景。图像唤起一种有趣的荒诞感和烹饪幻想。
评估者根据模型输出与所给提示的一致性来评价模型的文本遵循能力。从测试结果来看,Stable Diffusion 3 在文本遵循方面表现优异,能够更准确地根据提示生成相应的图像内容。
排版指的是模型生成的图像中文本的布局、格式和外观。根据评估者的选择,Stable Diffusion 3 在排版方面也表现出色,能够更好地呈现出给定提示中的文本信息,使生成的图像更具可读性和吸引力。
另外,在不同硬件设备上的性能表现方面,Stable Diffusion 3 也展现出了出色的灵活性。
例如,在 RTX 4090 等设备上,最大模型(8B 参数)在进行图像生成时,可以在 34 秒内生成一幅分辨率为 1024x1024 的图像,而且还能够在初期预览阶段提供多种参数模型选择,从 800m 到 8B 参数的模型规模,以进一步消除硬件方面的限制。
在消费者级硬件上,Stable Diffusion 3 依然可以有较快的推断速度,并且资源利用率高。
此外,该技术提供了多种模型规模选择,以满足不同用户和应用场景下的需求,增强了其可扩展性和适用性。
Stable Diffusion 3 的提出不仅注重了图像生成的质量,还专注于与文本的对齐和一致性。其改进的 Prompt Following 功能使得模型能够更好地理解输入文本并根据其创作图像,而不仅仅是简单地产生图像。这种灵活性使 Stable Diffusion 3 能够根据不同的输入文本生成多样化的图像,满足不同主题和需求。
Stable Diffusion 3 采用了改进的 Rectified Flow(RF)方法,通过线性轨迹将数据和噪声相连接,使得推断路径更直,从而在少量步骤内进行采样。同时,Stable Diffusion 3还引入了一种新的轨迹采样调度,将更多的权重分配给轨迹的中间部分,从而改进了预测任务的难度。这种创新的方法改善了模型的性能,并在文本到图像生成任务中取得了更好的效果。
在文本到图像生成领域,Stable Diffusion 3 的问世标志着技术的重大进步。通过 MMDiT 架构的创新、Rectified Flow 的优化以及对硬件设备和模型规模的灵活调整,Stable Diffusion 3 在视觉美感、文本遵循和排版等方面表现出色,超越了当前的文本到图像生成系统。
Stable Diffusion 3 的诞生,不仅提高了生成图像的质量和准确性,还为未来的创意产业、个性化内容生成、辅助创作工具以及增强现实和虚拟现实应用等领域带来了新的可能性。
未来,随着这项技术的进一步发展和普及,我们可以期待看到更多创新的应用场景和解决方案。
这是一位SD资深大神整理的,100款Stable Diffusion超实用插件,涵盖目前几乎所有的,主流插件需求。
全文超过4000字。
我把它们整理成更适合大家下载安装的【压缩包】,无需梯子,并根据具体的内容,拆解成一二级目录,以方便大家查阅使用。
单单排版就差不多花费1个小时。
希望能让大家在使用Stable Diffusion工具时,可以更好、更快的获得自己想要的答案,以上。
如果感觉有用,帮忙点个支持,谢谢了。
想要原版100款插件整合包的小伙伴,可以来点击下方插件直接免费获取
100款Stable Diffusion插件:
面部&手部修复插件:After Detailer
在我们出图的时候,最头疼的就是出的图哪有满意,就是手部经常崩坏。只要放到 ControlNet 里面再修复。
现在我们只需要在出图的时候启动 Adetailer 就可以很大程度上修复脸部和手部的崩坏问题
AI换脸插件:sd-webui-roop
换脸插件,只需要提供一张照片,就可以将一张脸替换到另一个人物上,这在娱乐和创作中非常受欢迎。
模型预设管理器:Model Preset Manager
这个插件可以轻松的创建、组织和共享模型预设。有了这个功能,就不再需要记住每个模型的最佳 cfg_scale、实现卡通或现实风格的特定触发词,或者为特定图像类型产生令人印象深刻的结果的设置!
现代主题:Lobe Theme
已经被赞爆的现代化 Web UI 主题。相比传统的 Web UI 体验性大大加强。
提示词自动补齐插件:Tag Complete
使用这个插件可以直接输入中文,调取对应的英文提示词。并且能够根据未写完的英文提示词提供补全选项,在键盘上按↓箭头选择,按 enter 键选中

提示词翻译插件:sd-webui-bilingual-localization
这个插件提供双语翻译功能,使得界面可以支持两种语言,对于双语用户来说是一个很有用的功能。
提示词库:sd-webui-oldsix-prompt
提供提示词功能,可能帮助用户更好地指导图像生成的方向。
上千个提示词,无需英文基础快速输入提示词,该词库还在不断更新。
以后再也不担心英文写出不卡住思路了!
由于篇幅原因,有需要完整版Stable Diffusion插件库的小伙伴,点击下方插件即可免费领取
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









