






前言
就在几天前,Stability AI正式开源了Stable Diffusion 3 Medium(以下简称SD3M)模型和适配CLIP文件。这家身处风雨飘摇中的公司,在最近的一年里一直处于破产边缘,就连创始人兼CEO也顶不住压力提桶跑路。

即便这样,它依然被誉为生成式AI的Top3之一,比肩OpenAI和Midjourney的存在……没错,Stability AI就是那个唯一的开源公司。真正的Open Source半死不活,闭源公司万人追捧,这就是真实的世界,首先挣钱,再谈尊严。
SDXL发布的时候,我就写过深度测评,这次同样拒绝信息差,没有废话,给一个SD3M最直观的感受。
以下只讨论官方发布的基础版本模型,不包括开源社区发布的融合版。
Q:作为当前主流SD1.5,SDXL与SD3M有什么区别?
A:主要有三点区别
最显著的是模型规模和参数:
SD1.5参数为8600万;SDXL包含2.6亿参数,是1.5的3倍;SD3的模型参数范围从8亿到80亿,对应模型体积也不相同。
显而易见,以SD3M模型本体4GB的大小,在它之上至少还有1-2个体积更大的版本(已知SD3 Ultra存在)没有开源。
其次是语义理解能力:
SD1.5虽然采用了CLIP模型将自然语言与图像对应,但实际效果只能说聊胜于无,稍微复杂一点的长句就歇菜;
SDXL有所改进,一个CLIP不够两个来凑,能理解长句,还能勉强画出特定语种的文字,比如英文;
SD3M更进一步,直接在训练时就引入Transformer,直接搭建Diffusion-Transformer俗称DiT的结构(没错年初红极一时的Sora也是这个路径),带来的好处显而易见,就是真的能“听懂人话”,这里暂且不表,下一段再展开来说。
最后是出图质量:
正如真理只在大炮射程之内,画质的高低同样取决于像素。能堆出的像素越多,画面看起来就越精致,简单粗暴。
SD1.5默认像素512x512,如果过度提高像素(1024以上),很多时候会出现畸变导致画面崩坏;
SDXL默认像素1024起步,画面精细度肉眼可见的提高,但相比之下对GPU资源的消耗倍增,经常炼丹的朋友应该深有感受,动辄700m,大至1.3G的微调模型,真的难顶;
SD3M同样是1024起步,画质好于SDXL,主要是在对颜色和光影的把控上更为精准,8G显存就能带得动,直觉上感到这会是SDXL的平行替代品。
Q:相比起前几个版本,SD3M最显著的突破在哪里?
A:重点就在DiT这里,更具体一点,官方将其称为Multimodal Diffusion Transformer (MMDiT)
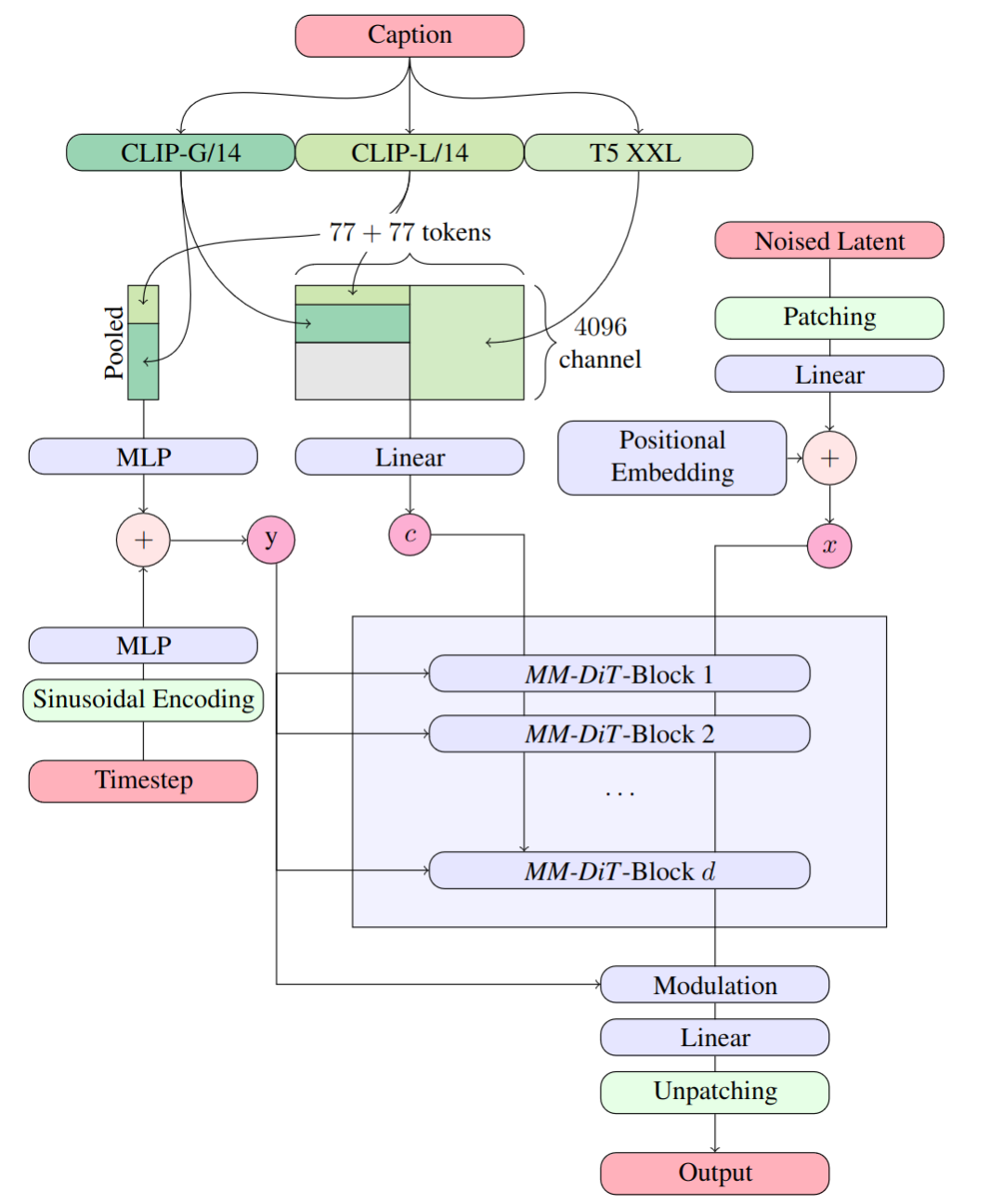
流程图看上去很复杂,实际上翻译成人话就是:模型现在更能看懂你想表达的意思。
经常抽卡的朋友应该深有体会,在文生图时,如果不加入控制条件,你让人物头戴一束花环,那么大概率在图的背景中同样会出现鲜花;又比如描述人物穿着的上衣绣着小猫图案,那么很大的可能这只小猫会出现在人的脚边;更不必说同一场景中描述多人物,简直就是一场难以形容的灾难。
大语言模型的加入解决了一个重要的问题:语义理解。
经常研究U-Net潜空间的朋友都知道,从SD1.5开始潜空间深度学习是成对的,一边是文字标签caption,一边是对应的图像表达,经过多轮加噪声和去像素,最终保存成经过预训练的文件。
然而现实世界中很少有词或词组是唯一概念,比如我们说“这只猫真好看”,有可能这是一只真的猫,有可能是一只玩偶,还有可能只是鞋子上的Hello Kitty……离开了对上下文的语义理解,即便有插件辅助,抽卡依然是很痛苦的事。
举个具体的例子,这样一段提示词:
三人走在城市街道上,华人,左边的男人穿着浅红色夹克和蓝色牛仔裤,拿着相机,中间的女人穿着酒红色毛衣,灰色裙子,戴着眼镜,右边的女人穿着海军蓝连衣裙,拿着手提包,天空晴朗,城市景观,逼真风格
Three people walk in the city street,asian chinese,the man on the left is wearing a light red jacket and blue jeans,holding a camera,the woman in the middle is wearing a wine red sweater,gray skirt,wearing glasses,the woman on the right is wearing a navy blue dress,holding a handbag,the sky is clear,the city landscape,realistic style
这段提示词里包括了多人场景,每个人物的服装特征,甚至还定义了相对位置。经常出图的朋友可以打开SD跑一张文生图试试,这种场景对于SDXL也是一场灾难。
而在SD3M这里,如下图所示:

没有抽卡,一步到位。不仅服装穿搭严格遵照了提示词的指引,连人物的左中右站位都是正确的。更进一步,如果你熟悉前几个版本SD模型对颜色的复现,不难看出SD3M对色彩的控制力有大幅强化(比如酒红)。
举个更直观的例子,下图将上衣颜色改成淡蓝、天蓝和海军蓝,三者的差异肉眼可见。

这还只是4GB的官方底模,基础能力恐怖如斯。
Q:在SD3M之外,难道还有其他版本?
A:已知至少存在Ultra版本,目前可以通过官方API调用,文生图单价约0.5元/张。
Q:再来几张图看看档次
A:以下提示词相同,相比上面的例子减少了右边的人。
漫画风格

3D风格

像素风+英文

黏土风+英文

Q:SD3M缺点在哪里?
A:主要有三点
**非完全体。**如果官方发布的Ultra版效果图保真的话,那效果至少是比肩Midjourney V5.2以上的存在。毕竟Stability也是要吃饭的,只能说理解。
**依然会肉眼可见的出错。**手的问题,四肢协调的问题,脸的问题,亟待开源社区补充方案。

**生态环境问题。**从SD1.5到SDXL,没人会用官方发布的底模,生态的丰富依赖模型创作者、插件作者,以及工作流设计师的共同努力。从现在算起,一个月之内应该能看到一些成果面世。
Q:硬件配置和软件环境?
A:SD3M需求8G显存,基于Comfy UI和Swarm UI可以运行,相信WebUI也不会迟到太久。
Q:最值得期待的是什么?
A:当然是微调模型!
底模代表了基座,微调模型就是建立在基座上的特定形式。底模能力越强大,就意味着能提供的精度越高,越能支撑微调模型的特征表达,最终展现出来的结果,很可能就是更好的复现物理世界的真实场景,或者更具有泛化能力的风格基调。
4GB的底模,体量仅仅相当于经典的Chilloumix,微调模型应该不至于像SDXL生态下的1.3GB这般臃肿吧。
更进一步来说,视频本身就是多个静态帧基于时间顺序的连接,从这个角度来看,图像模型能力的提升,最终能力会外延到视频领域,提高整体画面表现力的同时,部分打破或者削弱闭源视频的壁垒。
**简单总结,SD3M并不完美,但进步很大,值得上手。**至于NSFW什么的,那不重要,真的不重要。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!

对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









