










今天,老金给大家介绍一个利用最新的FLUX-Fill模型与FLUX-Redux模型相结合,进行图片合成的工作流。
这个图片合成工作流也是In-Context-LoRA生态系统圈作者在C站分享的一个工作流,我们先来看下这个工作流的网址:
https://civitai.com/models/933018?modelVersionId=1110698
再来看下它的工作流:
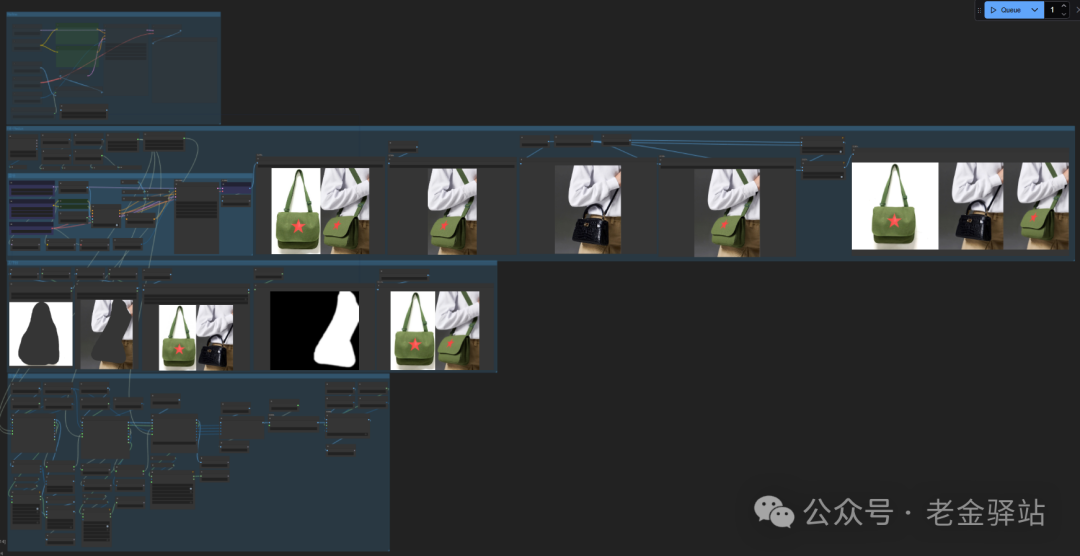
最后来看下最后出片的效果

不错吧,控制得相当好!
接下来,作者就带大家来安装这个工作流所需要的插件,有点多!
涉及到的节点插件有:ComfyUl-lmpact-Pack、comfyui-mixlab-nodes、ComfyUI_Comfyroll_CustomNodes、was-node-suite-comfyui、ComfyUI_essentials、ComfyUI-Easy-Use、ComfyUI-KJNodes、Comfyui-In-Context-Lora-Utils。
作者的原始工作流中还有一个Comfyui-art-venture节点,由于在安装中出现节点与节点依赖之间出现冲突,然后,把这个节点给舍弃咯,不影响整体出图。
这么多节点中有两个节点给大家介绍一下,一个是ComfyUl-lmpact-Pack,这个节点老金建议大家直接从comfyui-manager中直接安装,因为,手动安装了多次都不成功,还是看了作者issue中的建议,直接从comfyui-manager中搜索ComfyUl-lmpact-Pack,才安装成功的
还有一个就是Comfyui-In-Context-Lora-Utils节点,github网址如下:
https://github.com/lrzjason/Comfyui-In-Context-Lora-Utils
这个节点更简单,直接下载一下网址的插件包:
https://github.com/lrzjason/Comfyui-In-Context-Lora-Utils/archive/refs/heads/main.zip
下载后解压后放入custom_nodes目录下即可

这个节点主要是用于定义和合成图片重绘MASK、场景MASK,让FLUX-Fill模与FLUX-Redux这两个模型清晰地知道重绘的位置。
其它的节点大多都是一些常用的节点,在老金往期中都有过介绍,一路走来的网友应该都已安装咯!没有安装过的同学也不要着急,老金给大家做了一个一键压缩包,解压就能直接运行,需要的请文末自取。
老金试了下,效果还是不错的,有没有时尚的赶脚 。
。

有了这个工具,马上又想到一个组合,大家看看怎么样啊?

这里为了帮助大家更好地掌握 ComfyUI,分享一套字节大佬整理的ComfyUI工作流集合,其包含了很多好玩有趣,但又有点复杂的工作流节点和json配置。
涵盖了 Stable Scascade、3D、LLM+SD、Portrait Master、SVD 等相关类别的工作流,共计15个类目38项工作流。这些都放在了下方卡片,需要的点击免费获取:

对于初学者来说,最佳的学习方法是以这些现成的工作流为模板,一步步地复刻并理解它们。
通过观察和分析别人的工作流,你可以学习到各种节点搭建的技巧和方法。随着理解的深入,你将能够根据自己的需求创新和搭建属于自己的工作流。
希望本文能帮助你有效地提升你的设计效率和创造力。
对于从来没有接触过AI绘画的同学,我已经帮你们准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
这份完整版的AI绘画资料和SD整合包已经打包好了,需要的点击下方插件,即可前往免费领取!


















 1519
1519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









