



在企业知识库的智能化实践中,一个常见的挑战是如何在一个系统中同时管理多个业务领域(如人力资源、IT支持、财务报销)的知识。如果简单地将所有场景的文档(如PDF)混合到一个统一的向量数据库中,会导致严重的“知识干扰”问题。
例如,当用户咨询“医疗报销流程”时,系统可能错误地检索到“IT设备申请指南”中的内容,从而生成不准确、不可信的答案,极大地影响用户体验和系统可靠性。
为解决这一问题,今天我将深入探讨一套系统性的多场景RAG知识隔离架构,涵盖核心思路、推荐架构、具体实现方案及一个基于LlamaIndex的完整可落地代码示例。希望能帮助到大家。
一、核心思路:场景路由+ 知识隔离
根本的解决之道在于改变“一锅烩”的做法,转而采用“分而治之”的策略。其核心流程分为三步:
- 1.场景判断:首先,系统需要准确识别用户当前问题所属的业务场景。
- 2.定向检索:随后,系统仅在该特定场景对应的专用知识库中进行检索。
- 3.精准生成:最后,利用检索到的场景相关知识生成最终答案。
通过这种方式,可以确保每个问题的解答都基于最相关、最纯净的知识源,有效避免了跨场景信息的干扰。
二、推荐架构:分层RAG + 动态路由
我们推荐采用分层RAG结合动态路由的架构来实现上述思路。该架构清晰地分离了路由决策与知识检索两大功能模块,如下图所示:
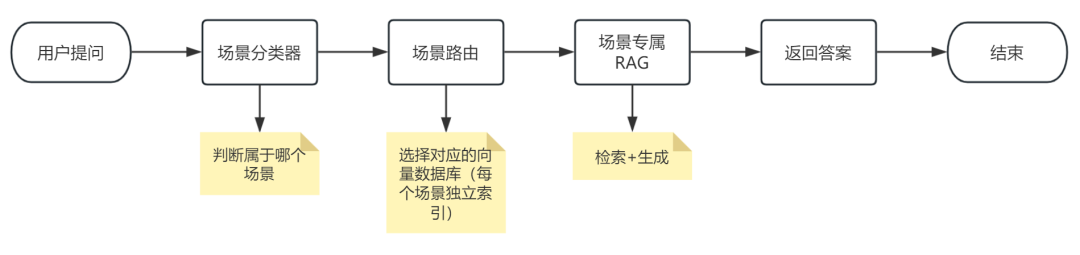
架构描述:用户查询首先进入“路由层”,该层负责进行场景分类。分类结果将决定查询被分发到哪个“场景专属检索层”。每个场景都有自己的向量索引和检索器,最终由生成模型结合检索结果和原始问题输出答案。

三、主流实现方案详解
方案1:多向量库 + 分类器路由(推荐)
适合场景数量固定(如20~100个),每个场景知识量中等。
实现步骤:
1. 预处理阶段:
-
为每个PDF(场景)单独构建向量数据库(如 Chroma、Pinecone、Weaviate 的不同collection/index)
-
例如:hr_policy_db, it_support_db, finance_db…
2. 构建场景分类器:
- 方法A(轻量级):用规则+关键词(如包含“报销”→财务,“请假”→HR)
不用大模型来实现,而是使用基于向量机的机器学习算法+TF-IDF 来实现
-
方法B(ML):训练一个文本分类模型(如BERT微调),输入问题,输出场景标签
-
方法C(LLM-based):用LLM做零样本分类(Prompt Engineering)
prompt = f"""
你是一个场景分类器。请判断以下问题属于哪个业务场景:
可选场景:[HR政策, IT支持, 财务报销, 行政管理, 法务咨询]
问题:{user_query}
输出格式:仅返回场景名称,不要解释。
"""
3. 运行时流程:
-
用户提问 → 分类器输出场景标签(如“财务报销”)
-
系统自动选择 finance_db 进行检索
-
用检索结果 + 原始问题 → 生成答案
优点:
-
知识完全隔离,无干扰
-
可单独更新某个场景知识库
-
检索效率高(只查一个小库)
工具推荐:
- 向量库:Chroma(本地)、Pinecone(云)、Qdrant(高性能)
- 分类器:scikit-learn(SVM/TF-IDF)、HuggingFace Transformers(BERT)、LLM AP
方案2:元数据过滤(Metadata Filtering)
适合使用支持元数据过滤的向量数据库(如 Pinecone, Weaviate, Qdrant)
实现步骤:
-
1.构建统一向量库:将所有场景的知识块(chunk)存入一个向量库,但为每个块附加详细的元数据,其中必须包含场景标签。
-
# 示例:每个文本块附加 metadatachunk = {"text": "报销需提供发票原件...","metadata": {"scene": "finance", "source_pdf": "finance_policy_v2.pdf"}} -
2.检索时动态过滤:先通过分类器判断场景,在检索时向向量库发送查询指令和元数据过滤条件(例如
filter={"scene": "finance"}),向量库只返回符合过滤条件的相关块。
优点:
- •只需维护一个向量库,管理简单。
- •新增场景时非常方便,只需为新文档打上标签即可。
方案3:HyDE + 查询重写(高级方案)
此方案适用于场景边界模糊、用户问题表述不明确的情况。
实现步骤:结合查询理解技术,先使用LLM将用户原始问题重写或扩展为更明确、更易于检索的查询(Hypothetical Document Embeddings, HyDE),然后再对改写后的查询进行场景分类和检索。还可以加入置信度机制,当分类器不确定时,可要求用户明确其问题领域。
完整实现示例:基于LlamaIndex的多场景RAG系统
以下是一个使用Python、LlamaIndex框架和Chroma向量数据库实现的完整、可落地的解决方案。
1. 技术栈与项目结构
- •核心框架:LlamaIndex
- •向量数据库:Chroma(本地持久化)
- •大语言模型与嵌入模型:阿里云DashScope(通义千问)
- •项目结构:
project/
│
├── config.py # 场景配置
├── classifier.py # 场景分类器
├── rag_engine.py # 核心RAG引擎
├── app.py # 主程序入口
├── data/ # 知识文档
│ ├── hr/ # 存放HR政策PDF
│ ├── it/ # 存放IT支持PDF
│ └── finance/ # 存放财务报销PDF
└── storage/ # 向量索引持久化目录
2. 核心代码实现
(1)场景配置 (config.py)
定义所有需要管理的业务场景及其关键词和文档路径。
SCENES = {
"hr": {
"name": "人力资源政策",
"keywords": ["请假", "年假", "入职", "离职", "合同", "社保"],
"path": "./data/hr"
},
"it": {
"name": "IT支持",
"keywords": ["电脑", "网络", "账号", "打印机", "软件", "VPN"],
"path": "./data/it"
},
"finance": {
"name": "财务报销",
"keywords": ["报销", "发票", "差旅", "付款", "预算", "费用"],
"path": "./data/finance"
}
}
(2)场景分类器 (classifier.py)
实现一个两级分类器:先通过关键词快速匹配,若不成功则使用LLM进行智能分类。
import os
from openai import OpenAI
from config import SCENES
client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
def classify_scene_by_keywords(query: str) -> str | None:
for scene, info in SCENES.items():
if any(kw in query for kw in info["keywords"]):
return scene
return None
def classify_scene_by_llm(query: str) -> str:
scene_descs = [f"{k}:{v['name']}"for k, v in SCENES.items()]
prompt = f"""你是一个企业知识库路由系统。请根据用户问题,判断其最可能属于以下哪个业务场景:
{chr(10).join(scene_descs)}
问题:{query}
要求:只输出场景英文标识(如 hr, it, finance),不要解释。"""
try:
response = client.chat.completions.create(model="qwen-plus", messages=[{"role": "user", "content": prompt}], temperature=0.0, max_tokens=10)
pred = response.choices[0].message.content.strip().lower()
return pred if pred in SCENES else"hr"
except Exception as e:
print(f"LLM分类失败:{e}")
return"hr"
def classify_scene(query: str) -> str:
scene = classify_scene_by_keywords(query)
if scene:
return scene
return classify_scene_by_llm(query)
(3)多场景RAG引擎 (rag_engine.py)
核心类,负责为每个场景初始化或加载向量索引,并提供查询接口。
import os
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader, StorageContext, load_index_from_storage
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
from llama_index.llms.dashscope import DashScope
from llama_index.embeddings.dashscope import DashScopeEmbedding
from config import SCENES
from classifier import classify_scene
Settings.llm = DashScope(api_key=os.getenv("DASHSCOPE_API_KEY"), model_name="qwen-max")
Settings.embed_model = DashScopeEmbedding(api_key=os.getenv("DASHSCOPE_API_KEY"), model_name="text-embedding-v1")
class MultiSceneRAG:
def __init__(self):
self.indices = {}
self._init_indices()
def _init_indices(self):
client = chromadb.PersistentClient(path="./storage/chroma_db")
for scene, info in SCENES.items():
print(f"Loading index for scene: {scene}")
collection = client.get_or_create_collection(f"scene_{scene}")
vector_store = ChromaVectorStore(chroma_collection=collection)
persist_dir = f"./storage/{scene}"
storage_context = StorageContext.from_defaults(vector_store=vector_store, persist_dir=persist_dir)
if os.path.exists(persist_dir):
try:
index = load_index_from_storage(storage_context)
print(f"成功加载已有索引 for scene: {scene}")
except Exception as e:
print(f"加载索引失败,正在重建 for scene {scene}: {e}")
index = self._build_new_index(info["path"], storage_context, persist_dir)
else:
print(f"构建新索引 for scene: {scene}")
index = self._build_new_index(info["path"], storage_context, persist_dir)
self.indices[scene] = index.as_query_engine()
def _build_new_index(self, data_path, storage_context, persist_dir):
documents = SimpleDirectoryReader(data_path).load_data()
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
os.makedirs(persist_dir, exist_ok=True)
index.storage_context.persist(persist_dir=persist_dir)
return index
def query(self, user_query: str) -> str:
scene = classify_scene(user_query)
print(f"路由到场景:{SCENES[scene]['name']}({scene})")
query_engine = self.indices[scene]
response = query_engine.query(user_query)
return str(response)
(4)主程序 (app.py)
提供一个简单的交互界面。
from rag_engine import MultiSceneRAG
if __name__ == "__main__":
rag = MultiSceneRAG()
while True:
query = input("\n请输入您的问题(输入'quit'退出): ")
if query.lower() == 'quit':
break
answer = rag.query(query)
print(f"答案:\n{answer}\n")
3. 测试与验证
-
1.准备数据:将HR政策PDF放入
data/hr/,IT指南放入data/it/,财务制度放入data/finance/。 -
2.首次运行:执行
python app.py,系统会自动为每个场景构建向量索引并持久化到./storage/目录。 -
3.提问测试:
-
- •输入“用人单位在哪些节日期间应当依法安排劳动者休假?”,系统应路由到
hr场景并给出准确答案。 - •输入“公司日常报销流程及步骤?”,系统应路由到
finance场景。 - •输入“IT运维服务规范的参考标准?”,系统应路由到
it场景。
- •输入“用人单位在哪些节日期间应当依法安排劳动者休假?”,系统应路由到
五、总结与建议
首选建议:对于大多数企业级应用,我们推荐采用方案一(多向量库+分类器路由),并结合LlamaIndex或LangChain等框架来构建。该方案通过“轻量级分类器(规则+LLM兜底)”与“物理隔离的向量索引”相结合,在保证知识隔离与检索精准度的同时,具备了良好的可维护性和可扩展性。
实施路径建议:
- 1.原型验证:首先使用Chroma在本地环境快速搭建demo,验证核心流程。
- 2.效果评估:使用3到5个真实业务问题测试路由准确性和答案质量。
- 3.迭代优化:根据测试结果,决定是否需要引入更复杂的分类器(如微调BERT)或优化Prompt,以持续提升系统性能。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

















 4821
4821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









