






 本文详细描述了如何将UAVDT数据集中的DET数据集转换为VOC格式,包括生成txt文件、整理图片和标签、划分训练集和测试集,以及将数据转换为COCO、XML(VOC)和YOLO格式的过程。
本文详细描述了如何将UAVDT数据集中的DET数据集转换为VOC格式,包括生成txt文件、整理图片和标签、划分训练集和测试集,以及将数据转换为COCO、XML(VOC)和YOLO格式的过程。
主要是将UAVDT数据集转化成VOC格式的目标检测数据集
1.生成txt文件
首先要将gt.whole.txt里边的DET数据集按照图片名称进行分割,保证分割后的txt文件中包含该图片的所有标注信息,代码如下:
import os
#文件夹的路径
folder_path = "/workspace/uavdt_night/UAV-benchmark-M/M1102"
folder_path1 = os.path.join(folder_path ,'gt')#存放分割后的txt文件的路径
folder_path2 = os.path.join(folder_path , 'img1')#照片的路径,主要用于统计有多少张照片,方便创建txt文件
folder_path3 = os.path.join(folder_path , 'gt', 'M1102_gt_whole.txt')#存放标签的txt文件
photo_count = 0
# 判断图片数量
for file_name in os.listdir(folder_path2):
# 使用os.path.splitext()函数获取文件扩展名
_, extension = os.path.splitext(file_name)
# 如果文件是照片文件(例如.jpg或.png),则增加计数器
if extension.lower() in ['.jpg', '.jpeg', '.png', '.gif', '.bmp']:
photo_count += 1
print("Total photos:", photo_count)
if not os.path.exists(folder_path):
os.makedirs(folder_path)
with open(folder_path3,'r') as file:
lines = file.readlines()
for i in range(1,photo_count+1):
file_path1 = os.path.join(folder_path1, str(i) + '.txt')
with open(file_path1, 'w') as target_file:
for line in lines:
data = line.split(',')
if data[0] == str(i):
target_file.write(line)
2.生成完整的图片和标签文件夹
将各文件夹下的图片和txt文件按照依次递增的顺序存放到一个文件夹中,代码如下
import os
import shutil
# 图片文件夹和标签文件夹的根路径
root_folder = "/workspace/uavdt_night/UAV-benchmark-M"
# 目标图片文件夹路径
destination_img_folder = "/workspace/uavdt_night/all/img"
# 目标标签文件夹路径
destination_ann_folder = "/workspace/uavdt_night/all/ann"
# 用于计数的变量
img_count = 1
ann_count = 1
# 遍历指定文件夹中的所有文件夹
for folder_name in ["M0202", "M0203", "M0204","M0205","M0206","M0901","M0902","M1001","M1002","M1003","M1004","M1005","M1006","M1007","M1008","M1009","M1101","M1102"]:
# 构建当前文件夹中的图片文件夹路径
img_folder_path = os.path.join(root_folder, folder_name, "img1")
# 如果图片文件夹存在
if os.path.exists(img_folder_path):
# 遍历图片文件夹中的所有文件
for filename in os.listdir(img_folder_path):
# 获取文件的完整路径
file_path = os.path.join(img_folder_path, filename)
# 获取文件的扩展名
_, extension = os.path.splitext(filename)
# 生成新的文件名
new_filename = f"image_{img_count}{extension}"
# 构建目标文件的完整路径
destination_file = os.path.join(destination_img_folder, new_filename)
# 移动文件到目标文件夹
shutil.copy(file_path, destination_file)
# 更新计数器
img_count += 1
# 构建当前文件夹中的标签文件夹路径
ann_folder_path = os.path.join(root_folder, folder_name, "gt")
# 如果标签文件夹存在
if os.path.exists(ann_folder_path):
# 遍历标签文件夹中的所有文件
for filename in os.listdir(ann_folder_path):
# 获取文件的完整路径
file_path = os.path.join(ann_folder_path, filename)
# 生成新的文件名
new_filename = f"image_{ann_count}.txt"
# 构建目标文件的完整路径
destination_file = os.path.join(destination_ann_folder, new_filename)
# 移动文件到目标文件夹
shutil.copy(file_path, destination_file)
# 更新计数器
ann_count += 1
3.划分数据集
将全部的文件按照一定的比例进行切分,分成训练集和测试集
import os
import random
import shutil
def split_dataset(source_dir, train_dir, test_dir, split_ratio=0.8):
# 创建训练集和测试集文件夹
os.makedirs(train_dir, exist_ok=True)
os.makedirs(test_dir, exist_ok=True)
# 获取所有图片文件的列表
image_files = [f for f in os.listdir(source_dir) if f.endswith('.jpg') or f.endswith('.png')]
# 随机化文件列表
random.shuffle(image_files)
# 计算训练集和测试集的数量
num_train = int(len(image_files) * split_ratio)
num_test = len(image_files) - num_train
# 将文件移动到相应的文件夹中
for i, image_file in enumerate(image_files):
source_path = os.path.join(source_dir, image_file)
if i < num_train:
target_path = os.path.join(train_dir, image_file)
else:
target_path = os.path.join(test_dir, image_file)
shutil.move(source_path, target_path)
# 设置源文件夹和目标文件夹路径
source_directory = "/workspace/uavdt_night/all/img"
train_directory = "/workspace/uavdt_night/all/train"
test_directory = "/workspace/uavdt_night/all/test"
# 划分数据集并移动文件
split_dataset(source_directory, train_directory, test_directory)
4.划分标签
按照分割后的图片名称,将对应的标签文件进行分割,代码如下
import os
import shutil
def copy_txt_files(image_folder, txt_folder, output_folder):
# 创建输出文件夹
os.makedirs(output_folder, exist_ok=True)
# 获取图片文件夹中所有图片文件的名称列表
image_files = [f for f in os.listdir(image_folder) if f.endswith('.jpg') or f.endswith('.png')]
# 遍历图片文件夹中的图片文件
for image_file in image_files:
# 构建对应的txt文件路径
txt_file = os.path.splitext(image_file)[0] + '.txt'
txt_path = os.path.join(txt_folder, txt_file)
# 检查对应的txt文件是否存在
if os.path.exists(txt_path):
# 复制txt文件到输出文件夹中
shutil.copy(txt_path, output_folder)
# 设置图片文件夹路径、txt文件夹路径和输出文件夹路径
image_folder = "/workspace/uavdt_night/all/train"
txt_folder = "/workspace/uavdt_night/all/ann"
output_folder = "/workspace/uavdt_night/all/train_ann"
# 将txt文件复制到新的文件夹中
copy_txt_files(image_folder, txt_folder, output_folder)
5.转化成json(coco)格式
将分割后的标签文件由txt格式转化为json进行保存,代码如下
import json
import os
# 创建一个空的COCO格式数据结构
coco_data = {
"info": {},
"licenses": [],
"categories": [],
"images": [],
"annotations": []
}
# 读取txt文件并解析数据
def parse_txt_file(txt_file):
with open(txt_file, 'r') as f:
lines = f.readlines()
annotations = []
for line in lines:
# 解析每一行数据,格式为 <frame_index>,<target_id>,<bbox_left>,<bbox_top>,<bbox_width>,<bbox_height>,<out-of-view>,<occlusion>,<object_category>
frame_index, target_id, bbox_left, bbox_top, bbox_width, bbox_height, out_of_view, occlusion, object_category = map(str.strip, line.split(','))
annotations.append({
"bbox": [int(bbox_left), int(bbox_top), int(bbox_width), int(bbox_height)],
"category_id": int(object_category)
})
return annotations
# 遍历txt文件夹
txt_folder = "/workspace/uavdt_night/all/train_ann"
for filename in os.listdir(txt_folder):
if filename.endswith('.txt'):
txt_file = os.path.join(txt_folder, filename)
# 解析txt文件
annotations = parse_txt_file(txt_file)
# 将图像信息添加到COCO数据结构中
image_info = {
"id": len(coco_data["images"]) + 1,
"file_name": os.path.splitext(filename)[0] + '.jpg' # 假设txt文件与图像文件同名
}
coco_data["images"].append(image_info)
# 将目标标注信息添加到COCO数据结构中
for annotation in annotations:
annotation_info = {
"id": len(coco_data["annotations"]) + 1,
"image_id": image_info["id"],
"bbox": annotation["bbox"],
"category_id": annotation["category_id"],
"iscrowd": 0 # 假设目标不是一个crowd
}
coco_data["annotations"].append(annotation_info)
# 保存COCO格式数据为JSON文件
with open("/workspace/uavdt_night/all/train.json", 'w') as f:
json.dump(coco_data, f)
6.转换为xml(voc)格式
将json格式转化为.xml格式
import os
import json
import xml.etree.ElementTree as ET
# VOC 数据集目录
voc_dataset_dir = "/workspace/uavdt_night/all/voc_UAVDT"
# 创建 VOC 数据集目录(如果不存在)
if not os.path.exists(voc_dataset_dir):
os.makedirs(voc_dataset_dir)
# 解析 JSON 文件并生成 VOC 标注文件
def convert_to_voc(json_file):
with open(json_file, 'r') as f:
coco_data = json.load(f)
for image_info in coco_data["images"]:
image_filename = image_info["file_name"]
annotations = [annotation for annotation in coco_data["annotations"] if annotation["image_id"] == image_info["id"]]
# 获取图像序号(假设文件名格式为 /workspace/uavdt_night/all/test/image_1.jpg)
image_number = int(os.path.splitext(os.path.basename(image_filename))[0].split('_')[-1])
# 创建 VOC 标注文件
root = ET.Element("annotation")
# 添加图像文件名
filename_element = ET.SubElement(root, "filename")
filename_element.text = image_filename
# 添加图像尺寸信息(假设图像尺寸信息已经在 JSON 文件中提供)
width_element = ET.SubElement(root, "width")
width_element.text = str(image_info.get("width", "unknown"))
height_element = ET.SubElement(root, "height")
height_element.text = str(image_info.get("height", "unknown"))
depth_element = ET.SubElement(root, "depth")
depth_element.text = "3" # 假设图像是 RGB 格式的
# 添加目标标注信息
for annotation in annotations:
bbox = annotation["bbox"]
category_id = annotation["category_id"]
# 将类别 ID 转换为 VOC 格式的类别名称
category_name = "unknown" # 默认值
if category_id == 1:
category_name = "car"
elif category_id == 2:
category_name = "truck"
elif category_id == 3:
category_name = "bus"
# 添加 VOC 标签信息
object_element = ET.SubElement(root, "object")
name_element = ET.SubElement(object_element, "name")
name_element.text = category_name
bbox_element = ET.SubElement(object_element, "bndbox")
xmin_element = ET.SubElement(bbox_element, "xmin")
xmin_element.text = str(bbox[0])
ymin_element = ET.SubElement(bbox_element, "ymin")
ymin_element.text = str(bbox[1])
xmax_element = ET.SubElement(bbox_element, "xmax")
xmax_element.text = str(bbox[0] + bbox[2])
ymax_element = ET.SubElement(bbox_element, "ymax")
ymax_element.text = str(bbox[1] + bbox[3])
# 保存 VOC 标注文件
voc_annotation_file = os.path.join(voc_dataset_dir, os.path.splitext(image_filename)[0] + ".xml")
tree = ET.ElementTree(root)
tree.write(voc_annotation_file)
# 调用函数将 JSON 文件转换为 VOC 格式
json_file_path = "/workspace/uavdt_night/all/all.json"
convert_to_voc(json_file_path)
7.转化成yolo格式
将对应的xml格式转化为yolo格式
"""将voc格式转化为yolo格式"""
import os
import xml.etree.ElementTree as ET
def voc_to_yolo_multiple(voc_folder, yolo_folder, img_width, img_height):
for filename in os.listdir(voc_folder):
if filename.endswith('.xml'):
voc_xml_file = os.path.join(voc_folder, filename)
yolo_txt_file = os.path.join(yolo_folder, os.path.splitext(filename)[0] + '.txt')
voc_to_yolo(voc_xml_file, yolo_txt_file, img_width, img_height)
def voc_to_yolo(voc_xml_file, yolo_txt_file, img_width, img_height):
with open(voc_xml_file, 'r') as f:
tree = ET.parse(f)
root = tree.getroot()
yolo_labels = []
for obj in root.findall('object'):
name = obj.find('name').text
bndbox = obj.find('bndbox')
xmin = float(bndbox.find('xmin').text)
ymin = float(bndbox.find('ymin').text)
xmax = float(bndbox.find('xmax').text)
ymax = float(bndbox.find('ymax').text)
# 计算归一化坐标
x_center = (xmin + xmax) / (2 * img_width)
y_center = (ymin + ymax) / (2 * img_height)
box_width = (xmax - xmin) / img_width
box_height = (ymax - ymin) / img_height
# 将类别名转换为类别编号
class_id = -1
if name == 'car':
class_id = 0
elif name == 'truck':
class_id = 1
elif name == 'bus':
class_id = 2
if class_id != -1:
yolo_labels.append((class_id, x_center, y_center, box_width, box_height))
# 将 YOLO 格式的标签写入文件
with open(yolo_txt_file, 'w') as f:
for label in yolo_labels:
f.write('{} {:.6f} {:.6f} {:.6f} {:.6f}\n'.format(label[0], label[1], label[2], label[3], label[4]))
# 使用示例:将 VOC 文件夹中的所有 XML 文件转换为 YOLO 格式
voc_folder = '/workspace/uavdt_night/all/voc_UAVDT'
yolo_folder = '/workspace/uavdt_night/all/labels'
img_width = 1024 # 图像宽度
img_height = 540 # 图像高度
voc_to_yolo_multiple(voc_folder, yolo_folder, img_width, img_height)
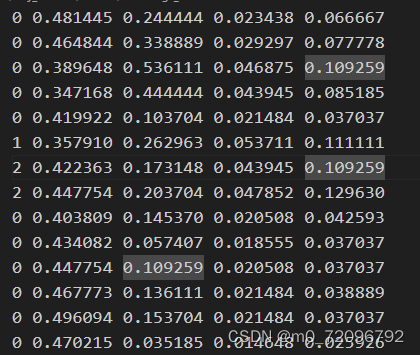
部分转化后的格式为:

















 1671
1671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









