







GCN结合Transformer是一种创新的深度学习模型,它通过融合图卷积网络(GCN)对图结构数据的强大建模能力与Transformer在处理序列数据时的卓越性能,实现了对复杂图结构数据的深度理解和高效处理。
因此,这个策略在很多实际应用场景中非常好用,很多GCN结合Transformer的出色成果都能证明。在GCN(图卷积网络)结合Transformer的最新工作中,就展现出了其强大的性能和广泛的应用潜力:
MP-GT:通过结合GCN和Transformer方法来增强App使用预测的准确性,实现了74.02%的性能提升,且训练时间减少了79.47%。
MotionAGFormer:结合GCNFormer和Transformer以捕捉复杂的局部关节关系,提高3D姿势估计的准确性。实验表明其参数减少了3/4,计算效率涨了3倍。
为了方便大家能够更好的掌握这个创新思路,然后运用到自己的文章中,我为大家整理了最新的Transformer+GCN研究论文!
需要的同学关注工粽号【沃的顶会】 回复 GCN结合 即可全部领取
Tran-GCN:
A Transformer-Enhanced Graph Convolutional Network for Person Re-Identification in Monitoring Videos
文章解析
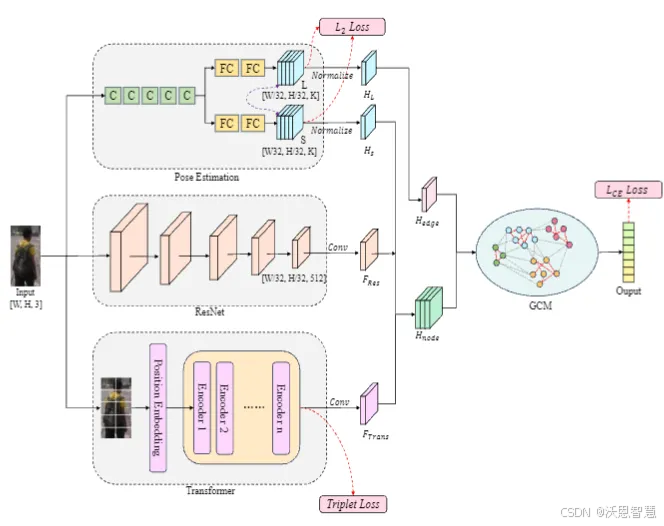
本文提出了一种名为Tran-GCN的模型,旨在通过整合局部特征、全局依赖关系和行人姿态信息来提高监控视频中的行人重识别性能。
该模型包括四个关键组件:姿态估计学习分支、Transformer学习分支、卷积学习分支和图卷积模块,分别用于提取行人姿态信息、学习全局依赖关系、提取局部特征和融合多种信息。
创新点
1.提出了一种新的Tran-GCN模型,结合了Transformer和图卷积网络的优势。
2.通过姿态估计学习分支提取行人的姿态信息,增强了模型对姿态变化的鲁棒性。
3.引入了Transformer学习分支,有效捕捉局部特征之间的全局依赖关系。
4.设计了图卷积模块,整合局部特征、全局特征和身体信息,提高了识别精度。
需要的同学关注工粽号【沃的顶会】 回复 GCN结合 即可全部领取
Integrating Features for Recognizing Human Activities through Optimized Parameters in Graph Convolutional Networks and Transformer Architectures
文章解析
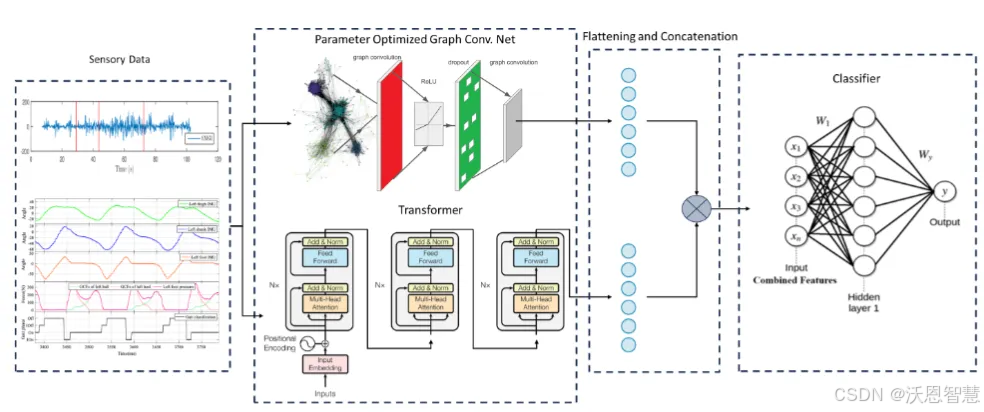
本文研究了特征融合技术对人类活动识别准确率的影响。通过使用四个公开数据集(HuGaDB、PKU-MMD、LARa和TUG),评估了Transformer模型和参数优化的图卷积网络(PO-GCN)的性能。
实验结果表明,PO-GCN在多个数据集上表现优于传统模型,特别是在HuGaDB和TUG数据集上分别提高了2.3%和5%的准确率。特征融合技术显著提升了模型的识别能力。
创新点
1.提出了参数优化的图卷积网络(PO-GCN)模型,显著提升了活动识别的准确率。
2.通过特征融合技术,结合了Transformer模型和PO-GCN模型的优势,进一步提高了识别性能。
3.在多个公开数据集上验证了模型的有效性,展示了其在不同场景下的泛化能力。
需要的同学关注工粽号【沃的顶会】 回复 GCN结合 即可全部领取
Spatial-temporal Graph Convolutional Networks with Diversified Transformation for Dynamic Graph Representation Learning
文章解析
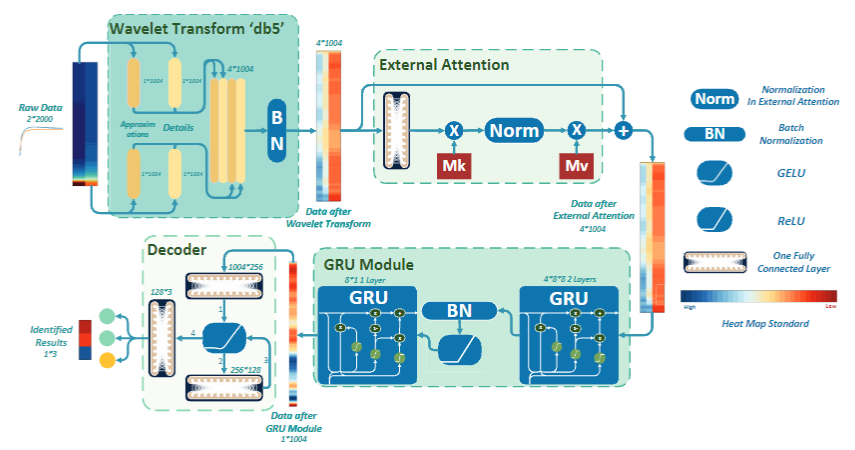
本文提出了一种新的空间-时间图卷积网络(STGCNDT),通过引入张量M-乘积和三种不同的变换方案(离散傅里叶变换、离散余弦变换和哈尔小波变换)来捕捉动态图中的复杂时间模式。
该模型能够有效地整合时空信息,避免了现有动态图卷积网络中时空信息分离的问题,并在通信网络中的链路权重估计任务上显著优于现有模型。
创新点
1.提出了STGCNDT模型,通过张量M-乘积和多样化变换方案有效捕捉动态图中的复杂时间模式。
2.设计了统一的图张量卷积网络(GTCN),避免了时空信息的分离和损失。
3.引入了三种变换方案(离散傅里叶变换、离散余弦变换和哈尔小波变换),增强了模型的表示能力。

















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









