







目录
一、引言
随着数据科学领域的快速发展,处理和分析高维数据成为了一个重要的挑战。在机器学习和数据分析中,PCA(主成分分析)算法作为一种有效的降维技术,被广泛用于提取数据中的关键信息,降低数据的复杂性,同时保留数据的主要特征。本博客将详细介绍PCA算法的概念、原理、优缺点以及实现步骤,并通过实验来验证其有效性。
二、PCA算法介绍
1.1算法概念
PCA(Principal Component Analysis),即主成分分析,是一种用于高维数据降维的统计方法。它通过线性变换将原始的高维数据映射到低维空间,同时保留数据中的主要信息。在降维过程中,PCA通过寻找数据中的主成分(即最能代表数据特征的线性组合)来实现数据的压缩和可视化。
1.2算法原理
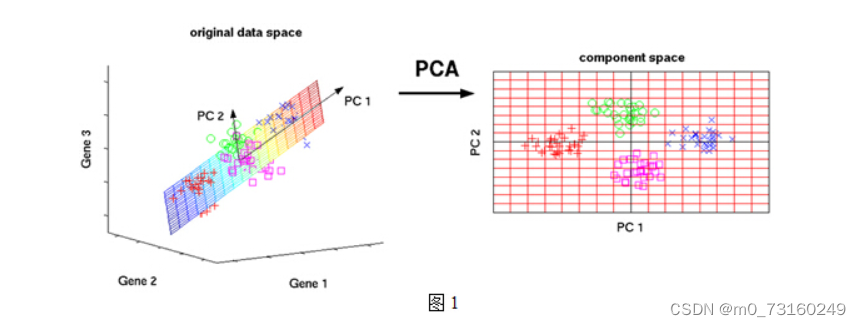
在数据分析中,我们常常将数据集视为多维空间中的一系列点。为了更有效地理解这些数据的内在结构和关键信息,我们采用主成分分析(PCA)来寻找最能代表数据变异性的几个方向。这些方向,如图中所示的橙色箭头以及标记为PC1和PC2的轴,是通过PCA算法计算得出的主成分。
当我们把这些数据点投影到这些主成分上时,我们的目标是使投影后的点尽可能分散,即它们之间的距离尽可能远。这样做可以确保我们捕获了数据中的最大变异,从而用较少的主成分来近似表示原始数据。
在选择这些主成分时,我们有一个重要的要求:它们必须是相互正交的(即没有线性关系),就像二维空间中的x轴和y轴一样。这种正交性保证了各个主成分之间没有信息冗余,每个主成分都捕捉了数据中独特且不同的变异信息。
通过PCA,我们可以将数据从原始的高维空间转换到一个由主成分构成的低维空间。在这个新的空间中,数据的维度大大降低,但关键信息得到了保留,使得我们能够更加直观地理解数据的结构和模式。
1.3优缺点
1.3.1优点
1.无监督学习:PCA算法不需要标签数据,适用于非监督学习任务。
2.降维效果好:PCA算法能够有效地降低数据的维度,简化数据的复杂性,同时保留数据的主要特征。
3.可解释性强:PCA算法将数据投影到低维空间后,得到的特征向量通常具有直观的含义,使得结果更容易解释。
4.稳健性:PCA算法对异常值和噪声的鲁棒性较强,能够有效地去除数据中的噪声和异常值。
1.3.2缺点
1.线性假设:PCA算法假设数据之间存在线性关系,如果数据之间存在非线性关系,PCA可能无法完全揭示数据的内在结构。
2.对初始变量有影响:PCA算法对初始变量的顺序和标签敏感,不同的变量顺序可能导致不同的主成分结果。
3.对缺失值敏感:PCA算法对缺失值较为敏感,如果数据中存在缺失值,可能会导致结果的不稳定。
4.需要选择主成分个数:在PCA中需要选择主成分的个数,这个选择会对结果产生重要影响。选择不当可能会导致降维后的数据失去一些重要信息。
1.4实现步骤
- 数据标准化:对原始数据进行标准化处理,使得每个特征的均值为0,方差为1。
- 计算协方差矩阵:计算标准化后的数据的协方差矩阵C=XXT,其中X为标准化后的数据矩阵,T表示转置。
- 计算特征值和特征向量:对协方差矩阵C进行特征值分解,得到特征值λ和对应的特征向量w。
- 选择主成分:根据特征值的大小选择主成分,通常选择前k个最大的特征值对应的特征向量。
- 投影数据:将原始数据投影到选择的主成分上,得到降维后的数据Z=X'W,其中X'为标准化后的数据矩阵,W为主成分矩阵(由选择的特征向量组成)。
举一个简单的例子:
1.输入数据X:2个特征,5个训练样本, 并去均值
2.计算协方差矩阵
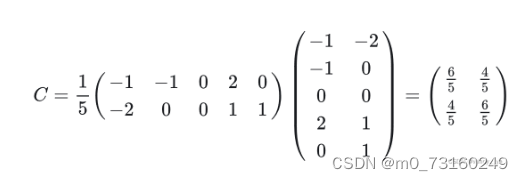
3.计算特征值和特征向量
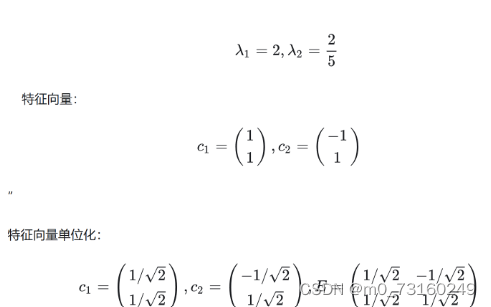
4.相似对角化
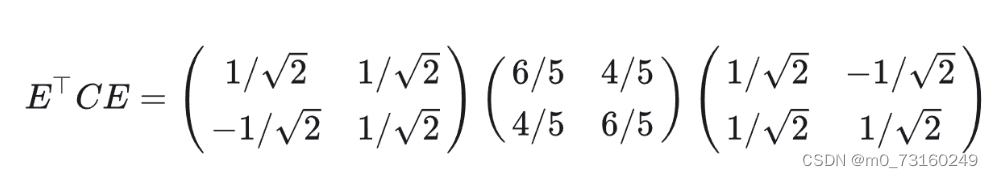
5.降到一维,那么就取𝑐1作为基,得最后结果(具体值没算)
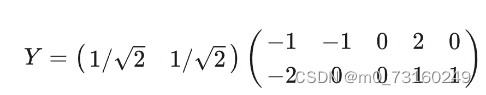
三、PCA算法实践
2.1数据集介绍
本实验用的是鸢尾花数据集。Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)三种中的哪一品种。
2.2PCA降维
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
# 加载鸢尾花数据集
iris = load_iris()
# Y是数据集的标签,代表三种鸢尾花:'setosa', 'versicolor', 'virginica'
Y = iris.target
# X是数据集的特征,四维:花瓣的长度、花瓣的宽度、花萼的长度、花萼的宽度
X = iris.data
# 创建一个PCA对象,设置要保留的主成分数量为2
pca = PCA(n_components=2)
# 对数据集X进行拟合,计算主成分
pca = pca.fit(X)
# 使用PCA模型将原始数据X转换到主成分空间,得到降维后的数据X_dr
X_dr = pca.transform(X)
# 对三种鸢尾花分别绘图
colors = ['red', 'black', 'orange'] # 设定颜色
# iris.target_names 是三种鸢尾花的名称
plt.figure() # 创建一个新的图形窗口
for i in [0, 1, 2]: # 循环遍历三种鸢尾花
# 绘制第i种鸢尾花的散点图
# X_dr[Y == i, 0] 表示第i种鸢尾花在第一个主成分上的坐标
# X_dr[Y == i, 1] 表示第i种鸢尾花在第二个主成分上的坐标
plt.scatter(X_dr[Y == i, 0],
X_dr[Y == i, 1],
alpha=1, # 设置散点的透明度
c=colors[i], # 散点的颜色
label=iris.target_names[i]) # 散点的标签(鸢尾花的名称)
plt.legend()
plt.title('PCA of IRIS dataset')
plt.show()2.3运行结果
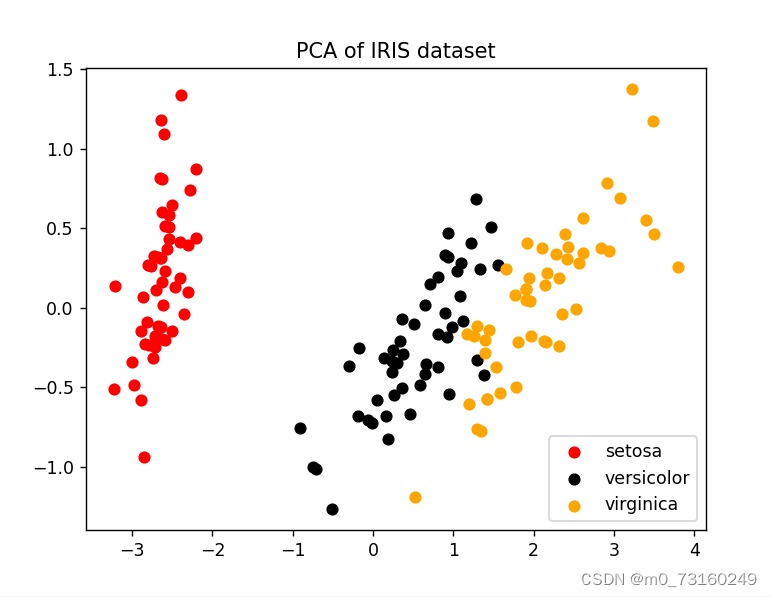
分析:
- 在PCA的结果图中,这些花通过红色、黑色和黄色圆点表示,并在二维坐标系中呈现出各自的聚类特点。
- 三种花的数据点在二维空间中形成了三个相对独立的区域,且每个区域内部的数据点相对集中,这有利于后续的分类任务。
- 特别是setosa类别的数据点,它们与其他两个类别的数据点有非常明显的分界线,这表明PCA在处理这个数据集时,能够很好地捕捉到setosa类别与其他类别之间的差异。
四、小结
经过对PCA算法的学习与实验,我深刻理解了其在数据降维和特征提取方面的强大功能。通过实际操作,我掌握了PCA的基本流程,包括数据标准化、协方差矩阵计算、特征值分解以及主成分的选取。实验结果显示,PCA能够有效降低数据维度,同时保留主要信息,使得数据可视化更加直观,分类效果也得到提升。















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









