







目录
软件技术基础实验分为4个内容: 堆栈操作、单链表操作、二叉树操作、查找与排序。虽然书上都有源码,但是要一个一个敲出来真的是很麻烦的事呀,所以为了便于大家理解和节约时间,这里我会给出全部实验的源码以及对应释义。
注:本实验全部使用C语言进行编写。
实验一、堆栈操作
实验目的
- 掌握栈的定义。
- 掌握栈基本操作的实现,并能用于解决实际问题。
实验内容
- 用顺序存储结构实现栈的基本操作:push,pop,isempty,isfull,createstack。
- 利用栈的基本操作实现conversion()函数,该函数能将任意输入的十进制整数转化为二进制形式表示。
- 扩展:将任意输入的十进制整数转化为八进制、十六进制形式表示。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <string.h>
// 定义常量,栈的最大大小
#define MAXSIZE 1024
// 数据类型定义,这里使用整型
typedef int datatype;
// 栈的结构体定义
typedef struct {
datatype elements[MAXSIZE]; // 栈内元素数组
int Top; // 栈顶指针,指向最后一个元素
} Stack;
// 创建空栈的函数
void setStackNull(Stack* S) {
S->Top = -1; // 栈顶指针初始化为-1,表示栈为空
}
// 判断栈是否已满的函数
int isfull(Stack* S) {
if (S->Top >= MAXSIZE - 1) // 如果栈顶指针大于等于最大值减一,则栈满
return 1;
else
return 0;
}
// 判断栈是否为空的函数
int isempty(Stack* S) {
if (S->Top < 0) // 如果栈顶指针小于0,则栈为空
return 1;
else
return 0;
}
// 压栈操作的函数
void push(Stack* S, datatype E) {
if (isfull(S)) // 如果栈满,则打印溢出信息
printf("Stack Overflow\n");
else {
S->Top++; // 栈顶指针加一
S->elements[S->Top] = E; // 将元素E放入栈顶
}
}
// 出栈操作的函数
datatype* pop(Stack* S) {
datatype* temp;
if (isempty(S)) { // 如果栈为空,则打印下溢信息
printf("Stack Underflow\n");
return NULL;
} else {
temp = (datatype*)malloc(sizeof(datatype)); // 分配内存空间
*temp = S->elements[S->Top]; // 将栈顶元素赋值给temp
S->Top--; // 栈顶指针减一
return temp; // 返回指向元素的指针
}
}
// 十进制整数转化为二进制数的函数
void conversion(int n) {
Stack S;
setStackNull(&S); // 初始化栈
int r, m;
r = n;
while (r) { // 循环直到数字为0
m = r % 2; // 取余数作为二进制位
if (isfull(&S)) // 如果栈满,打印溢出信息
printf("Over flow\n");
else
push(&S, m); // 压栈操作
r = r / 2; // 数字除以2
}
printf("转换后的二进制为:\n");
while (!isempty(&S)) { // 如果栈不为空
printf("%d", *pop(&S)); // 打印出栈元素
}
printf("\n");
}
// 任意进制转化为任意进制的函数
void conversion2(int n, int r) {
Stack S;
setStackNull(&S); // 初始化栈
int x;
int f = n;
while (f) { // 循环直到数字为0
if (isfull(&S)) // 如果栈满,打印溢出信息
printf("Over flow\n");
else
push(&S, f % r); // 压栈操作
f /= r; // 数字除以进制基数
}
printf("数据%d转化为%d进制后的结果为:", n, r);
while (!isempty(&S)) { // 如果栈不为空
x = *pop(&S); // 出栈操作
if (x >= 10) { // 如果数字大于等于10,则转换为字母表示
printf("%c", 'A' + x - 10);
} else {
printf("%d", x); // 否则直接打印数字
}
}
printf("\n");
}
// 主函数
int main() {
int num;
printf("请输入要转换为二进制的十进制数据:\n");
scanf("%d", &num); // 读取用户输入的十进制数
conversion(num); // 调用转换函数
// 扩展功能:任意进制转化为任意进制
int n, r;
printf("请输入转化的数字以及进制位:\n");
scanf("%d %d", &n, &r); // 读取用户输入的数字和目标进制
conversion2(n, r); // 调用任意进制转换函数
// 扩展功能:m进制转化为n进制
double mu;
int nu;
printf("请输入m进制转化为n进制中的m和n:\n");
scanf("%lf %d", &mu, &nu); // 读取用户输入的源进制和目标进制
printf("请输入需要转换的数据:\n");
char arra[1024];
scanf("%s", arra); // 读取用户输入的字符串
int s = strlen(arra); // 获取字符串长度
int sum = 0;
double j = 0;
for (int i = s - 1; i >= 0; i--) { // 从字符串末尾开始计算
sum += (arra[i] - '0') * pow(mu, j); // 累加每个位的值
j++;
}
conversion2(sum, nu); // 调用任意进制转换函数,将计算结果转换为目标进制
return 0;
}运行结果:

实验二、单链表操作
实验目的
- 掌握链表的概念。
- 熟练掌握线性表的链式存储结构。
- 熟练掌握线性表在链式存储结构上的运算。
实验内容
- 编程实现单链表的建立、插入、删除和访问算法,并输出结果。
#include <stdio.h>
#include <stdlib.h>
// 定义链表中数据的类型为字符
typedef char datatype;
// 定义链表节点的结构体
struct Node {
datatype data; // 节点存储的数据
struct Node* next; // 指向下一个节点的指针
};
// 使用typedef为链表类型定义一个别名,方便使用
typedef struct Node* linklist;
// 创建链表的函数
linklist createlist() {
char ch; // 用于存储用户输入的字符
linklist head, s, r; // head为头指针,s为新节点,r为当前节点
head = (linklist)malloc(sizeof(struct Node)); // 为头节点分配内存
r = head; // 初始化r为头节点
printf("请输入字符生成链表,以‘#’结束\n");
ch = getchar(); // 读取第一个字符
while (ch != '#') { // 当输入不为 '#' 时循环
s = (linklist)malloc(sizeof(struct Node)); // 为新节点分配内存
s->data = ch; // 将读取的字符赋值给新节点的数据
r->next = s; // 将新节点链接到链表末尾
r = s; // 移动r到新的末节点
ch = getchar(); // 继续读取下一个字符
}
r->next = NULL; // 设置链表末尾的next为NULL
return head; // 返回头指针
}
// 根据序号获取节点的函数
linklist get(linklist head, int i) {
int j;
linklist p;
p = head;
j = 0;
// 遍历链表直到p指向第i个节点或链表结束
while (p->next != NULL && j < i) {
p = p->next;
j++;
}
// 如果找到了第i个节点,则返回该节点
if (j == i)
return p;
else
return NULL; // 如果没有找到,返回NULL
}
// 删除指定序号节点的函数
linklist deletelink(linklist head, int i) {
linklist p = head, q;
int j = 0;
// 遍历链表直到找到第i个节点
while (p->next != NULL) {
j++;
if (j == i) {
q = p->next; // 要删除的节点
p->next = q->next; // 将p的next指向q的next,从而删除q
free(q); // 释放q占用的内存
return head; // 返回头指针
}
else {
p = p->next; // 继续向后查找
}
}
printf("error\n"); // 如果没有找到要删除的节点,打印错误信息
return head; // 返回头指针
}
// 根据序号插入节点的函数
void insertById(linklist head, int i, char x) {
linklist s, p;
int j;
s = (linklist)malloc(sizeof(struct Node)); // 为新节点分配内存
s->data = x; // 设置新节点的数据
p = head;
j = 0;
// 遍历链表直到p指向第i-1个节点
while (p != NULL && j < i - 1) {
j++;
p = p->next;
}
if (p != NULL) { // 如果找到了第i-1个节点
s->next = p->next; // 将新节点的next指向p的next
p->next = s; // 将p的next指向新节点
}
else {
printf("结点未找到!\n"); // 如果没有找到,打印错误信息
}
}
// 主函数
int main() {
char x; // 声明用于存储用户输入字符的变量
// 创建链表
linklist head, r;
head = createlist();
// 打印链表信息
printf("链表信息为:");
r = head->next; // 跳过头节点
while (r) {
printf("%c", r->data);
r = r->next;
}
printf("\n");
// 查询操作
int num;
printf("请输入要查询的序号:\n");
scanf("%d", &num);
r = get(head, num);
if (r == NULL)
printf("没有查到\n");
else
printf("查找的结果为:%c\n", r->data);
// 删除操作
printf("请输入要删除的序号:\n");
scanf("%d", &num);
head = deletelink(head, num);
// 打印删除后链表信息
printf("删除后链表信息为:");
r = head->next;
while (r) {
printf("%c", r->data);
r = r->next;
}
printf("\n");
// 插入操作
printf("请输入要插入的序号和字符:\n");
scanf("%d %c", &num, &x);
insertById(head, num, x);
// 打印插入后链表信息
printf("插入后链表信息为:");
r = head->next;
while (r) {
printf("%c", r->data);
r = r->next;
}
// 释放链表内存
r = head;
while (r != NULL) {
linklist temp = r;
r = r->next;
free(temp);
}
return 0;
}运行结果:
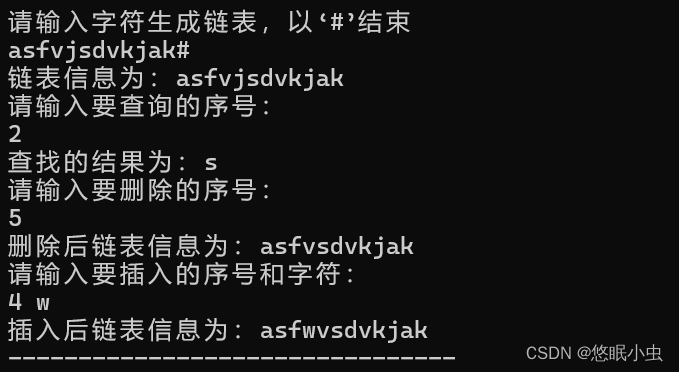
需要注意的是链表初始是1。
实验三、二叉树操作
实验目的
- 掌握二叉树的二叉链表存储结构。掌握二叉树的二叉链表存储结构。
- 掌握利用二叉树创建方法。
- 掌握二叉树的先序、中序、后序的递归实现方法。
实验内容
- 编写创建如下图所示二叉树的函数,函数名:create。
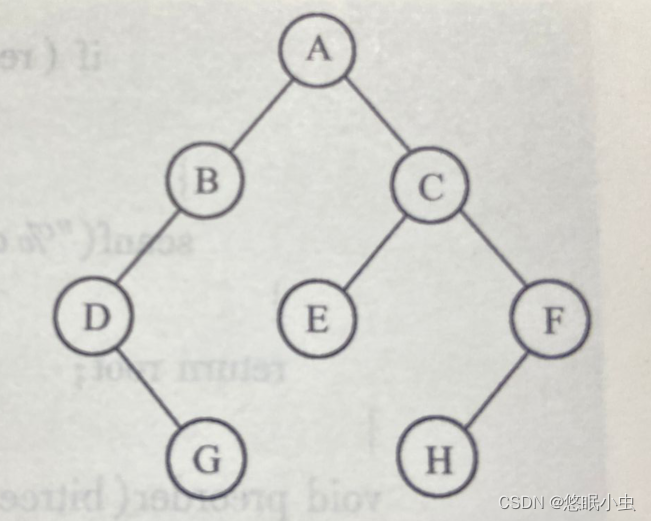
- 编写递归实现二叉树的中序、先序和后序遍历算法。函数名分别为 inorder,preorder,postorder。
- 编写主函数测试以上二叉树的创建和遍历函数。
#include <stdio.h>
#include <stdlib.h>
#define MAXSIZE 1024
typedef char datatype;
typedef struct node {
datatype data;
struct node* lchild;
struct node* rchild;
} Bitree;
Bitree* CreateTree() {
char ch; //接收用户输入的节点值
Bitree* Q[MAXSIZE]; //指针数组 Q,用于辅助构建二叉树,指针类型的数组构成队列
int front, rear; //用于指示数组 Q 的前后位置
Bitree* root, * s; //指针变量 root 和 s
root = NULL; //初始时二叉树为空
front = 1; //表示数组 Q 的初始状态
rear = 0;
printf("请输入二叉树的各个结点,@表示虚结点,#表示结束:\n");
scanf("%c", &ch);
while (ch != '#') {
printf("%c", ch);
s = NULL; //s 初始化为 NULL
if (ch != '@') {
s = (Bitree*)malloc(sizeof(Bitree));
s->data = ch; //节点值赋值给 s 的 data 成员
s->lchild = NULL; //s 的左孩子指针 lchild
s->rchild = NULL; //s 的右孩子指针 rchild
}
rear++; //rear 增加 1,并将 s 存储在 Q 数组的对应位置
Q[rear] = s;
if (rear == 1) //rear 的值为 1,即为第一个节点,将 root 指向 s
root = s;
else {
if (s && Q[front])
if (rear % 2 == 0)
Q[front]->lchild = s; //如果是偶数,则将s赋值给Q[front]节点的左孩子指针lchild
else
Q[front]->rchild = s;
if (rear % 2 == 1) //前节点是一个新的层级的节点
front++;
} //指向下一层的节点,指针 front 向下移动
scanf("%c", &ch);
}
return root; //返回二叉树的根节点指针root。
}
void preorder(Bitree* p) {
if (p != NULL) {
printf(" %c ", p->data);
preorder(p->lchild); //以当前节点 p 的左孩子作为参数,实现前序遍历左子树。
preorder(p->rchild);
}
}
void inorder(Bitree* p) {
if (p != NULL) {
inorder(p->lchild); //当前节点 p 的左孩子作为参数,实现中序遍历左子树
printf(" %c ", p->data);
inorder(p->rchild);
}
}
void postorder(Bitree* p) {
if (p != NULL) {
postorder(p->lchild);
postorder(p->rchild);
printf(" %c ", p->data);
}
}
int main() {
Bitree* root;
root = CreateTree();
printf("\n先序遍历结果如下:\n");
preorder(root);
printf("\n中序遍历结果如下:\n");
inorder(root);
printf("\n后序遍历结果如下:\n");
postorder(root);
printf("\n");
return 0;
}运行结果:

这里主要就是二叉树的3种遍历方法,还是很简单的。不懂的可以看这里
实验四、查找与排序
实验目的
- 掌握折半查找所需的条件、过程和实现方法
- 掌握二叉排序树的创建和查找过程。
- 掌握直接插入排序、希尔排序、快速排序算法的实现。
实验内容
- 编程实现至少两种查找算法 (1)折半查找 (2)哈希查找。
- 编程实现至少两种排序算法 (1)冒泡排序 (2)快速排序。
- 在同等条件下分析比较它们的效率。
顺序查找
#include <stdio.h>
#include <stdlib.h>
// 定义数据类型为int
typedef int datatype;
// 定义顺序表结构体
typedef struct {
datatype* elem; // 指向数组的指针,用于存储元素
int length; // 顺序表的长度
} Stable;
// 创建顺序表
void create(Stable* l) {
printf("请输入顺序表的内容:\n");
// 动态分配数组空间
l->elem = (datatype*)malloc(l->length * sizeof(datatype));
for (int i = 0; i < l->length; i++) {
printf("l.elem[%d] = ", i + 1);
scanf("%d", &l->elem[i]);
}
}
// 顺序查找
void s_search(const Stable* l, datatype k) {
int found = 0; // 初始化未找到
for (int i = 0; i < l->length; i++) {
if (l->elem[i] == k) {
printf("查找成功.\n");
found = 1; // 标记找到
printf("l.elem[%d] = %d\n", i + 1, k);
break; // 找到后退出循环
}
}
if (!found) {
printf("没有找到数据 %d !\n", k);
}
}
int main() {
Stable table;
datatype key;
printf("请输入顺序表的长度: ");
scanf("%d", &table.length);
// 调用create函数创建顺序表
create(&table);
printf("创建的顺序表内容:\n");
for (int i = 0; i < table.length; i++) {
printf("l.elem[%d] = %d\n", i + 1, table.elem[i]);
}
printf("输入查找关键字: ");
scanf("%d", &key);
// 调用s_search函数进行查找
s_search(&table, key);
// 释放顺序表占用的内存
free(table.elem);
return 0;
}运行结果:
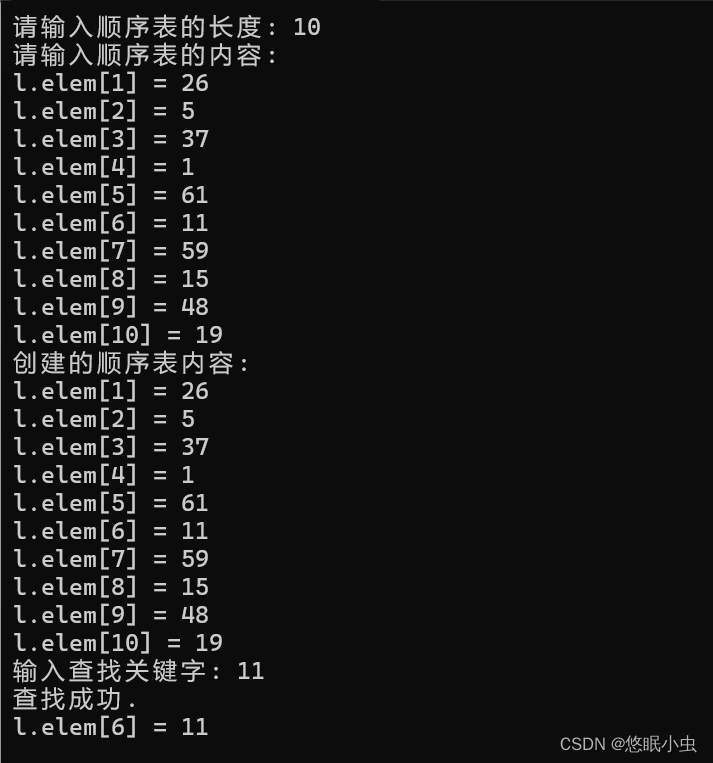
折半查找
#include <stdio.h>
#include<windows.h>
#define MAX 100 // 定义常量 MAX 作为数组大小
// 定义顺序表结构体
typedef struct {
int element[MAX + 1]; // 数组存储顺序表元素,MAX + 1 确保有足够的空间
int length; // 顺序表的长度
} Stable;
// 创建顺序表
void create_seq(Stable* l) {
printf("请输入顺序表的内容:\n");
for (int i = 0; i < l->length; i++) { // 循环读取用户输入的元素
printf("l.element[%d] = ", i + 1);
scanf("%d", &l->element[i]);
}
}
// 对顺序表进行冒泡排序
void sort_seq(Stable* l) {
int flag, t;
for (int i = 0; i < l->length - 1; i++) {
flag = 0; // 标记是否发生了交换
for (int j = 0; j < (l->length - 1) - i; j++) {
if (l->element[j] > l->element[j + 1]) {
t = l->element[j];
l->element[j] = l->element[j + 1];
l->element[j + 1] = t;
flag = 1; // 发生了交换
}
}
if (flag == 0) {
break; // 如果没有发生交换,说明已经排序完成,退出循环
}
}
}
// 自定义二分查找函数
int sea_self(const Stable* l, int k, int low, int high) {
if (low > high) {
printf("没有找到查找的值\n");
return -1;
}
int mid = (low + high) / 2; // 计算中间位置
if (l->element[mid] == k) {
printf("查找成功\n");
printf("l[%d] = %d\n", mid + 1, k);
return mid;
} else if (l->element[mid] < k) {
return sea_self(l, k, mid + 1, high); // 在右半边查找
} else {
return sea_self(l, k, low, mid - 1); // 在左半边查找
}
}
// 主函数
int main() {
double run_time;
LARGE_INTEGER time_start;
LARGE_INTEGER time_over;
double dqFreq;
LARGE_INTEGER f;
QueryPerformanceFrequency(&f);
dqFreq = (double)f.QuadPart;
Stable table;
int key;
printf("请输入线性表的长度:");
scanf("%d", &table.length);
create_seq(&table); // 创建顺序表
sort_seq(&table); // 对顺序表进行排序
printf("排序后的数据\n");
for (int i = 0; i < table.length; i++) {
printf("l[%d] = %d\n", i + 1, table.element[i]);
}
printf("请输入查找的值:\n");
scanf("%d", &key);
QueryPerformanceCounter(&time_start);
sea_self(&table, key, 0, table.length - 1); // 执行查找
QueryPerformanceCounter(&time_over);
run_time = 1000000*(time_over.QuadPart-time_start.QuadPart)/dqFreq;
printf("折半查找运行时间为:%fus\n",run_time);
return 0;
}运行结果:

哈希查找
#include <stdio.h>
#include<windows.h>
#define MAX 11
void ins_hash(int hash[], int key) {
int k, k1, k2; // 声明变量 k 为哈希值,k1 和 k2 用于探测
k = key % MAX; // 计算 key 对应的哈希位置
if (hash[k] == 0) { // 如果该位置为空,则直接插入
hash[k] = key;
} else { // 如果发生冲突
k1 = k + 1; // 从 k 的下一个位置开始向前探测
while (k1 < MAX && hash[k1] != 0) { // 向前探测直到找到空位或再次遇到冲突
k1++;
}
if (k1 < MAX) { // 如果找到了空位
hash[k1] = key; // 在空位插入 key
} else { // 如果没有找到空位,说明表已满
k2 = 0; // 从 0 开始向后探测
while (k2 < k && hash[k2] != 0) { // 向后探测直到找到空位或再次遇到冲突
k2++;
}
if (k2 < k) { // 如果找到了空位
hash[k2] = key; // 在空位插入 key
}
// 如果表满了,应该返回错误或采取其他措施,这里代码没有处理这种情况
}
}
}
void out_hash(int hash[]) {
int i;
for (i = 0; i < MAX; i++) { // 遍历哈希表
if (hash[i] != 0) { // 如果位置不为空
printf("hash[%d] = %d\n", i, hash[i]); // 打印元素
}
}
}
// 哈希表查找函数,使用线性探测法
void hash_search(int hash[], int key) {
int k, k1, k2, flag = 0; // 声明变量 k 为哈希值,k1 和 k2 用于探测,flag 用于标记是否找到
k = key % MAX; // 计算 key 对应的哈希位置
if (hash[k] == key) { // 如果直接在哈希位置找到 key
printf("查找成功: hash[%d] = %d\n", k, key);
flag = 1; // 设置找到标记
} else { // 如果没有直接找到
k1 = k + 1; // 从 k 的下一个位置开始向前探测
while (k1 < MAX && hash[k1] != key) { // 向前探测直到找到 key 或表尾
k1++;
}
if (k1 < MAX) { // 如果找到了 key
printf("查找成功: hash[%d] = %d\n", k1, key);
flag = 1; // 设置找到标记
}
// 如果向前没有找到,应该再向后探测,但代码中缺少这部分逻辑
// 此外,即使向后找到了,flag 也应该在找到后立即设置,而不是在 if 语句之外
}
if (!flag) { // 如果没有找到 key
printf("查找失败: 未找到 %d\n", key); // 打印未找到的消息
}
}
int main() {
double run_time;
LARGE_INTEGER time_start;
LARGE_INTEGER time_over;
double dqFreq;
LARGE_INTEGER f;
QueryPerformanceFrequency(&f);
dqFreq = (double)f.QuadPart;
int i, key, k;
int hash[MAX] = {0}; // 初始化哈希表,所有位置设为 0
printf("请输入数据,以-1结束:\n"); // 提示用户输入数据
// 读取第一个数据,如果读取失败或输入-1,则结束输入
if (scanf("%d", &key) != 1 || key == -1) {
key = -1;
}
while (key != -1) { // 循环读取数据直到输入-1
ins_hash(hash, key); // 将读取的数据插入哈希表
if (scanf("%d", &key) != 1 || key == -1) {
break;
}
}
out_hash(hash);
printf("请输入查找的值:");
scanf("%d", &k);
QueryPerformanceCounter(&time_start);
hash_search(hash, k);
QueryPerformanceCounter(&time_over);
run_time = 1000000*(time_over.QuadPart-time_start.QuadPart)/dqFreq;
printf("哈希查找运行时间为:%fus\n",run_time);
return 0;
}运行结果:

快速排序、希尔排序、插入排序算法
#include <stdio.h>
#include <stdlib.h>
#include<windows.h>
typedef struct {
int key;
} Record;
//插入排序
void insert_sort(Record R[], int n) {
for (int i = 1; i < n; i++) {
Record temp = R[i];
int j = i - 1;
while (j >= 0 && temp.key < R[j].key) {
R[j + 1] = R[j];
j--;
}
R[j + 1] = temp;
}
}
// 冒泡排序函数
void bubble_sort(Record R[], int n) {
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (R[j].key > R[j + 1].key) {
Record temp = R[j];
R[j] = R[j + 1];
R[j + 1] = temp;
}
}
}
}
//希尔排序
void shell_sort(Record R[], int n) {
int h = n / 2;
while (h > 0) {
for (int j = h; j < n; j++) {
Record temp = R[j];
int i = j - h;
while (i >= 0 && temp.key < R[i].key) {
R[i + h] = R[i];
i -= h;
}
R[i + h] = temp;
}
h /= 2;
}
}
int partition(Record R[], int low, int high) {
int i = low, j = high;
Record pivot = R[i];
while (i < j) {
while (i < j && R[j].key >= pivot.key)
j--;
if (i < j)
R[i++] = R[j];
while (i < j && R[i].key < pivot.key)
i++;
if (i < j)
R[j--] = R[i];
}
R[i] = pivot;
return i;
}
//快速排序
void quick_sort(Record R[], int low, int high) {
if (low < high) {
int pivot_pos = partition(R, low, high);
quick_sort(R, low, pivot_pos - 1);
quick_sort(R, pivot_pos + 1, high);
}
}
int main() {
double run_time;
LARGE_INTEGER time_start;
LARGE_INTEGER time_over;
double dqFreq;
LARGE_INTEGER f;
QueryPerformanceFrequency(&f);
dqFreq = (double)f.QuadPart;
int s = 7;
Record R[7];
for (int i = 0; i < s; i++) {
R[i].key = 0;
}
// 插入排序
printf("请输入使用插入算法排序的数据,以空格分隔:\n");
for (int i = 1; i < s; i++) {
scanf("%d", &R[i].key);
}
QueryPerformanceCounter(&time_start);
insert_sort(R, s);
QueryPerformanceCounter(&time_over);
run_time = 1000000*(time_over.QuadPart-time_start.QuadPart)/dqFreq;
printf("插入运行时间为:%fus\n",run_time);
printf("\n插入排序之后:\n");
for (int i = 1; i < s; i++) {
printf("%d\t", R[i].key);
}
// 冒泡排序
printf("\n\n请输入使用冒泡算法排序的数据,以空格分隔:\n");
for (int i = 1; i < s; i++) {
scanf("%d", &R[i].key);
}
QueryPerformanceCounter(&time_start);
bubble_sort(R, s);
QueryPerformanceCounter(&time_over);
run_time = 1000000*(time_over.QuadPart-time_start.QuadPart)/dqFreq;
printf("冒泡运行时间为:%fus\n",run_time);
printf("\n冒泡排序之后:\n");
for (int i = 1; i < s; i++) {
printf("%d\t", R[i].key);
}
// 希尔排序
printf("\n\n请输入使用希尔算法排序的数据,以空格分隔:\n");
for (int i = 1; i < s; i++) {
scanf("%d", &R[i].key);
}
QueryPerformanceCounter(&time_start);
shell_sort(R, s);
QueryPerformanceCounter(&time_over);
run_time = 1000000*(time_over.QuadPart-time_start.QuadPart)/dqFreq;
printf("希尔运行时间为:%fus\n",run_time);
printf("\n希尔排序之后:\n");
for (int i = 1; i < s; i++) {
printf("%d\t", R[i].key);
}
// 快速排序
printf("\n\n请输入使用快排算法排序的数据,以空格分隔:\n");
for (int i = 1; i < s; i++) {
scanf("%d", &R[i].key);
}
QueryPerformanceCounter(&time_start);
quick_sort(R, 1, s - 1);
QueryPerformanceCounter(&time_over);
run_time = 1000000*(time_over.QuadPart-time_start.QuadPart)/dqFreq;
printf("快排运行时间为:%fus\n",run_time);
printf("\n快排排序之后:\n");
for (int i = 1; i < s; i++) {
printf("%d\t", R[i].key);
}
return 0;
}运行结果:

OK啦,实验的代码内容就全部结束了,其实算法还是很简单的对吧,希望对大家能够有所帮助呀!
















 6834
6834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











