






双重差分分析方法在经济领域多用于对于公共政策或项目实施效果的评价。
1 标准双重差分模型估计原理
1.1 估计原理
1.1.1 原理

1.1.2 模型

1.1.3 绝对值差分vs相对值差分
在实证过程中,尽管用了“差分的差”,但是得到的依旧是绝对值,因此用相对量(如增长率)的差分更合理。实际操作是:对绝对值取对数,再进行第一次和第二次差分。如

1.2 假定
-
假定1:“平行趋势假定”(parallel trend assumption)。DID最为重要和关键的前提条件:共同趋势(Common Trends),两组之间可以存在一定的差异,但是双重差分方法要求这种差异不随着时间产生变化,也就是说,处理组和对照组在政策实施之前必须具有相同的发展趋势。这是DID的最大优点,即可以部分地缓解因 “选择偏差”(selection bias)而导致的内生性(endogeneity)
-
假定2:暂时性冲击与政策虚拟变量不相关。这是保证双向固定效应为一致估计量(consist estimator)的重要条件。在此,可以允许个体固定效应与政策虚拟变量相关(可通过双重差分或组内变换消去,或通过LSDV法控制)。
1.3 操作实例
1.3.1 读入所需数据,生成政策前后以及控制组虚拟变量,并将它们相乘产生交互项
1.3.1.1 法1
use "http://dss.princeton.edu/training/Panel101.dta", clear
gen time = (year>=1994) & !missing(year) //设置虚拟变量,政策执行时间为1994年
gen treated = (country>4) & !missing(country) //生成地区的虚拟变量
gen did = time*treated //产生交互项
reg y time treated did, r //随后将这三个变量作为解释变量,y作为被解释变量进行回归
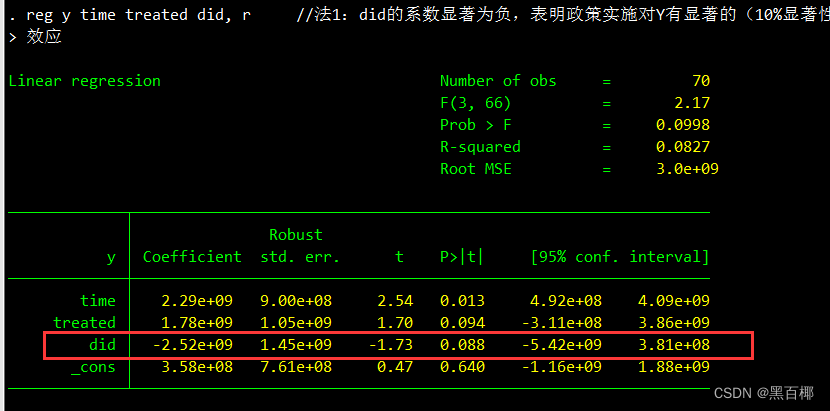
did的系数显著为负,表明政策实施对Y有显著的(10%显著性水平下)负效应
1.3.1.2 法2 结果怎么看,还不知道
ssc install diff // 下载外部命令
diff y, t(treated) p(time)
/* diff命令的语法格式:
diff outcome_var [if] [in] [weight] ,[ options]
“outcome_var”表示结果变量
option中有两个必选:
“treat(处理变量) ” (0: controls; 1:treated)
“period(实验期虚拟变量)”(1=实验期,0=非实验期)
其他option
cov(varlist),协变量,加上kernel可以估计倾向得分
kernel, 执行双重差分倾向得分匹配
id(varname),kernel选项要求使用
qdid(quantile),执行分位数双重差分
pscore(varname) 提供倾向得分
logit,进行倾向得分计算,默认probit回归
ddd(varname),三重差分
*/
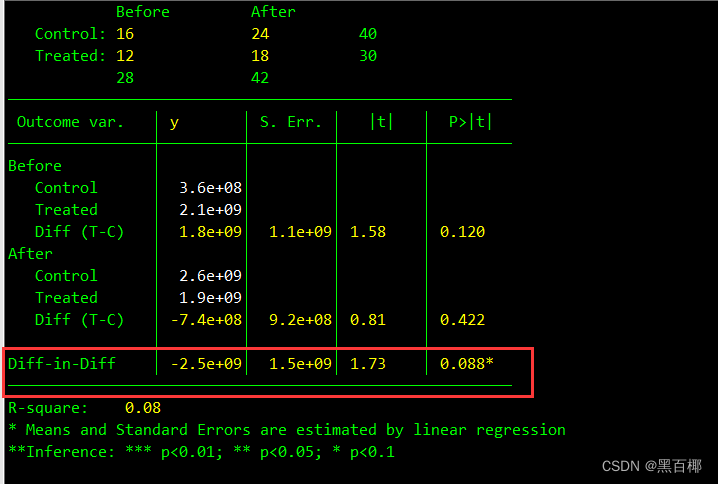
关注两种方法的结果,发现交乘项的不论是系数还是t值都一致
2 面板数据DID模型
双重差分的面板估计,仍然用OLS估计

注意,模型中不需要加入处理虚拟变量treati。因为模型中已加入个体固定效应ui,包含更多信息,是控制个体不随时间变化的特征。而treati仅控制不同组个体不随时间变化的特征,若ui和treati,同时加入,会产生多重共线性问题。
同理,模型中也不需要加入处理期虚拟变量posti,因为模型中加入了时间固定效应λt,λt包含更多的信息,控制每一期的时间效应,而postt仅控制了处理期前后的时间效应,若λt和postt同时加入,会产生多重共线性问题。
交叉乘积项系数θ表示处理效应。
stata处理上,做好变量处理,其余见固定效应模型与stata的实现
3 三重差分(DDD)分析
3.1 DDD适用于
平行趋势检验未获通过,即处理组和控制组因非干预措施引起的目标值增长速度不同时,做**三重差分(DDD)**分析就是一个可选方法。
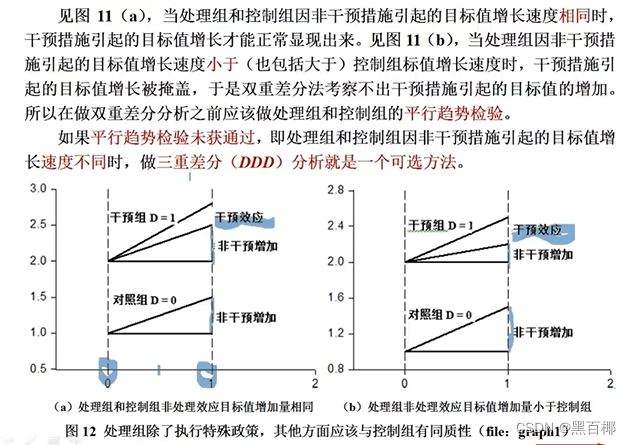
3.2 标准三重差分回归模型

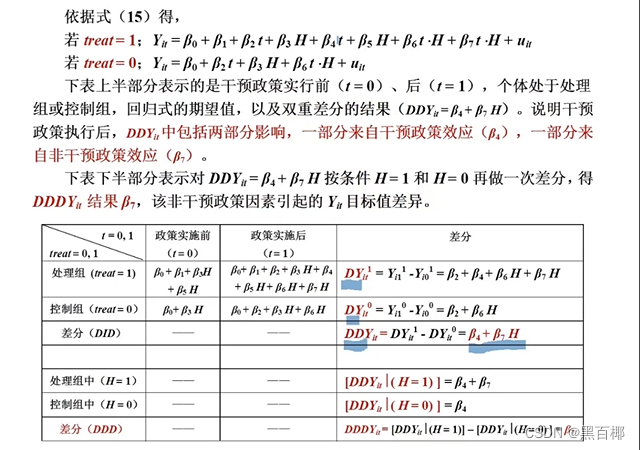
H表示除了研究的政策之外,可能导致结果变量Y变化的其他因素。
β4表示要研究的政策的处理效应,β7表示某因素在-研究的政策-的干预后对Y的影响
3.3 stata操作
*==========三重差分DDD=============
* 其实就是在双重差分基础上多了一些交乘项
* 假设y_bin变量是另外一个影响因素
gen did_y = did*y_bin
gen time_y = time*y_bin
gen treated_y = treated*y_bin
* 法1 reg回归
reg y time treated y_bin did time_y treated_y did_y, r
* 法2 diff 添加ddd选项来说明导致平行趋势检验没通过的变量是哪个
diff y, t(treated) p(time) ddd(y_bin)
4 面板数据多期DID模型
传统DID假定处理组的所有个体开始受到政策冲击的时点完全相同,但有时会出现处理组个体接受处理时间点不一致的情况,多期DID (Time-varying DID),也被称为多时点DID 或异时DID。
当描述个体处理期时点不完全一致的情形,面板数据DID模型中的postt,替换为postit,即处理期的时间点因个体i而异。模型如下:


如何将数据和基本信息匹配
*============多期DID==============
* 基础数据和面板数据对应
use Panel101.dta, clear
joinby country using DDD基础信息.dta
gen t = 0
replace t=1 if year >= treatime
gen did = treated*t
* 之后的回归用该did变量代替前面的did进行标准DID回归或者DDD回归、固定效应即可
* ------------------------ 以下不确定------------------------
gen time = (year>=1994) & !missing(year) //设置虚拟变量,政策执行时间为1994年
* 法1 考虑多期
reg y time treated did, r
est store mutiDID1
* 法2 考虑多期 diff
diff y, t(treated) p(t)
est store mutiDID2
* 法3 不考虑多期
gen did2 = time*treated
reg y time treated did2, r
est store standDID1
* 法2 不考虑多期 diff
diff y, t(treated) p(time)
est store standDID2
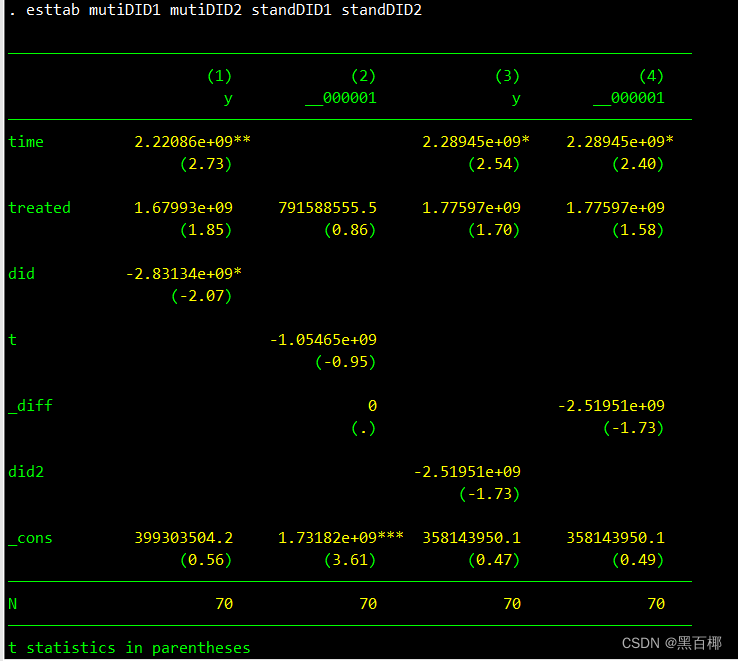
esttab mutiDID1 mutiDID2 standDID1 standDID2
对比结果如图所示,考虑多期时用diff显得很奇怪,是否代表多期DID不能用diff?
5 内生性和稳健性检验
5.1 平行趋势检验
在介绍完DID的基本思想和模型设定后,我们再来说说DID的稳健性检验,也就是要想办法证实所有效应确实是由政策实施所导致的。
所谓共同趋势或者平行趋势,是指处理组和控制组在政策实施之前必须具有相同的发展趋势。
如果不满足这一条件,那么两次差分得出的政策效应β就不完全是真实的政策效应,其中有一部分是由处理组和控制组本身的差异所带来的。如果平行趋势假设成立,那么在政策时点之前,处理组和控制组应该不存在显著差异。
5.1.1 时间趋势图
绘制处理组和控制组的y的均值的时间趋势 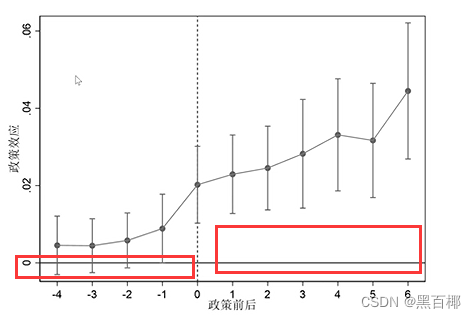 政策前几年,置信区间包括0,即不显著,接受系数为0的原假设;政策后,置信区间不包括0,显著,拒绝系数为0的原假设,说明政策实施后处理组和控制组发生了不同的变化。实际上,即使政策实施后的好几年才显著不为0,也可以表示通过了平行趋势检验,这是由于考虑到了政策实施有滞后效应。
政策前几年,置信区间包括0,即不显著,接受系数为0的原假设;政策后,置信区间不包括0,显著,拒绝系数为0的原假设,说明政策实施后处理组和控制组发生了不同的变化。实际上,即使政策实施后的好几年才显著不为0,也可以表示通过了平行趋势检验,这是由于考虑到了政策实施有滞后效应。
5.1.2 事件研究法
生成年份虚拟变量yearj与处理组虚拟变量treati的交互项,加入模型中进行回归(M、N分别表示政策前和政策后的期数),那么交互项treatixYEARj的系数δj衡量的就是第j期处理组和控制组之间的差异。
step1 生成年份虚拟变量与实验组虚拟变量的交互项,此处选在政策前后各3年进行对比。
gen period = year - 1994 // 计算距离政策实施前后的年份
forvalues i = 3(-1)1{ // 政策发生之前,向前做三期
gen pre_`i' = (period == -`i' & treated == 1)
}
gen current = (period == 0 & treated == 1)
forvalues j = 1(1)3{ // 政策发生之后,向后做三期
gen time_`j' = (period == `j' & treated == 1)
}
drop pre_1 // 为了避免多重共线性,drop掉一期
step2 随后将这些交互项作为解释变量进行回归,并将结果储存在reg中以备后续检验。
xtreg y time treated pre_* current time_* i.year, fe
est sto reg
step3 采用coefplot命令进行绘图
coefplot reg, ///
keep(pre_* current time_*) /// //横坐标
vertical ///
recast(connect) ///
yline(0) xline(3, lp(dash)) ///
addplot(line @b @at) ///
ciopts(lpattern(dash) ///
recast(rcap) ///
msize(medium)) msymbol(circle_hollow) scheme(simono)
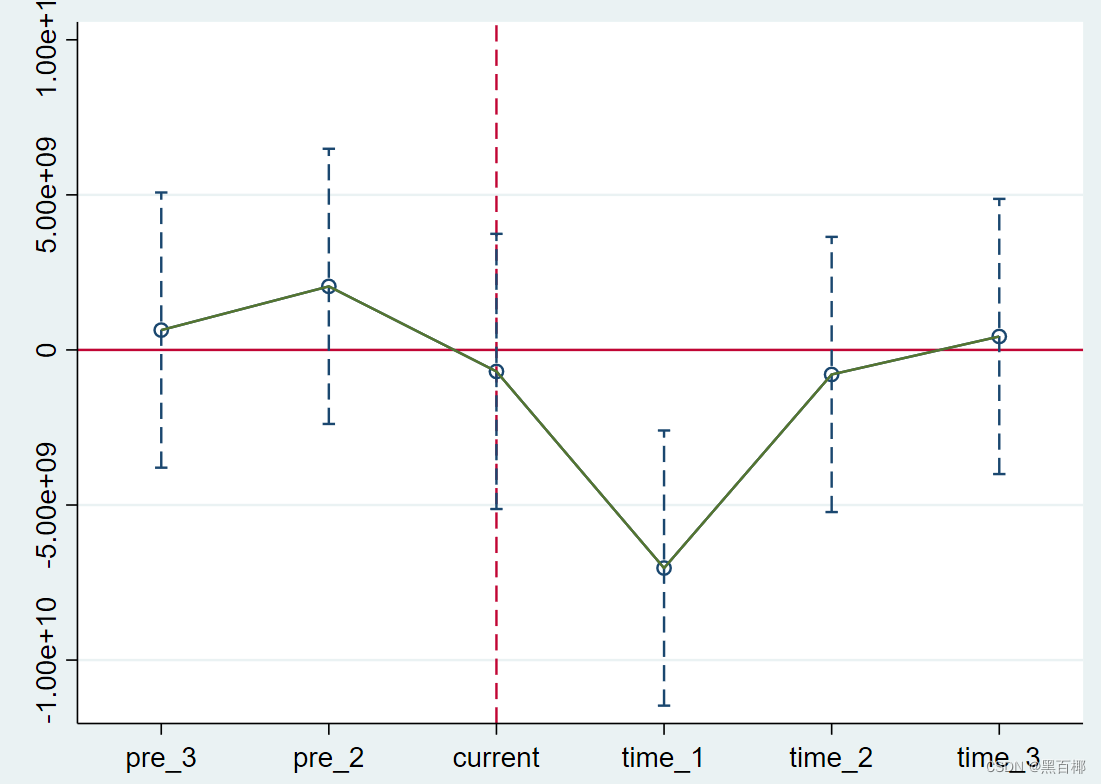 结果发现系数在政策前的确在0附近波动,而政策后一年系数显著为负,但很快又回到0附近。这说明实验组和控制组的确是可以进行比较的,而政策效果可能出现在颁布后一年,随后又很快消失。
结果发现系数在政策前的确在0附近波动,而政策后一年系数显著为负,但很快又回到0附近。这说明实验组和控制组的确是可以进行比较的,而政策效果可能出现在颁布后一年,随后又很快消失。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









