







 本文介绍了Python中的核心内置类型bytes和bytearray,以及它们与内存视图的关系。重点讲解了字节串和字节数组的特点、创建方法、运算以及与字符串的差异,以及memoryview在高效数据操作中的应用。
本文介绍了Python中的核心内置类型bytes和bytearray,以及它们与内存视图的关系。重点讲解了字节串和字节数组的特点、创建方法、运算以及与字符串的差异,以及memoryview在高效数据操作中的应用。
Python 操作二进制数据的核心内置类型是字节串(bytes)和字节数组(bytearray)。它们都支持内存视图(memoryview),使用缓冲协议访问其他二进制对象的内存,而无需复制产生新的对象。它们都是序列类型,其中字节数组(bytearray)是可变类型;字节串是不可变的字节序列;
理解
注:这里是相关概念的讲解,不是 Python 的实现
0 和 1 是计算机工作的根本,单个的0和1只能表达两种状态,无法满足我们复杂的计算,于是计算机使用了8位即一个 byte 作为一个储存的基本单位。字节(Byte )是计算机信息技术用于计量存储容量的一种计量单位,作为一个单位来处理的一个二进制数字串,是构成信息的一个小单位。即:
- 位(bit):是计算机 内部数据 储存的最小信息单位, 0 和 1 组成,例如 0000 0001,有 8 个位
- 字节(byte):由 8bit 组成,计算机数据处理 的基本单位,习惯上用大写 B 来表示,1B = 8bit。常用16进制的形式:0x01, 0x为固定前缀,此外 0o前缀为8进制,0b为二进制形式
- 字节串(bytes):由多个 byte 组成的序列,每一个元素是一个 byte。这一点与字符串与字符的关系类似。
- 字节数组(bytearray):由 byte 为元素组成的 array,每一个元素是一个 byte。
- 字符(character):是指计算机中使用的字母、数字、字和符号等,不同编码占用的字节长度不同。如,一般 utf-8 编码下,一个汉字字符占用 3 个字节
- 字符串(string):由若干字符组成
以下是一个16位(两个字节)的字符:
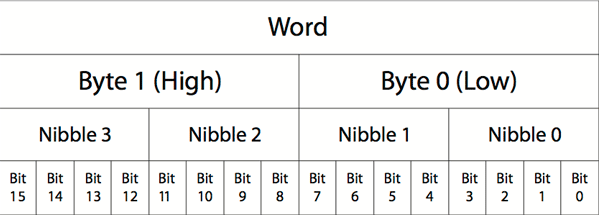
bytes 和 bytearray 区别:
- 字节串(bytes):可以看作是一组二进制数值(0-255) 的 str(不可变,每个元素是一个字节)
- 字节数组(bytearray):可以看作是一组二进制数值(0-255) 的 list(可变,每个元素是一个字节)
bytes 和 字符串区别:
- 字节串(bytes)是字节序列,它可以直接存储在硬盘, 字节串是给计算机看的
- 字符串(str)是字符序列,它是一种抽象的概念,不能直接存储在硬盘,字符串是给人类看的
它们之间的映射被称为编码/解码。在 Python 中,程序中的文本都用字符串表示,在执行时转换为字节码执行。
字节串 bytes
字节串 bytes 也叫字节序列,存储以字节为单位的数据,bytes 具有以下特点:
- 字节串是不可变的字节序列;
- 字节是 0~255 的整数;
- 数据传输和存储都是以字节为单位存储的:
1byte = 8bit,即 1 个字节等于 8 位;
字符串编码后得到的字节串,字节串由 0x00 ~ 0xFF 之间的整数组成:
>> '中国'.encode('utf-8')
b'\xe4\xb8\xad\xe5\x9b\xbd'下面,我们来学习 bytes 的基本操作。
创建空字节串字面量
>> b1, b2, b3, b4 = b'', b"", b'''''', b""""""
>> b1, b2, b3, b4
(b'', b'', b'', b'')创建非空字节串的字面值
>> b1 = b'Python'
>> b1
b'Python'也可以使用十六进制的形式创建字面值:
>> hex(ord('P')), hex(ord('y'))
('0x50', '0x79')
>> b3 = b'\x50\x79'
>> b3
b'Py'但不允许直接使用非 ASCII 字符创建:
>> b2 = b'中国'
File "<ipython-input-4-30ea9a50e9c6>", line 1
b2 = b'中国'
^
SyntaxError: bytes can only contain ASCII literal characters.
>> b2 = b'\xe4\xb8\xad\xe5\x9b\xbd'
>> b2
b'\xe4\xb8\xad\xe5\x9b\xbd'
>> b2.decode('utf-8')
'中国'数据构建
bytes
Python 的 bytes 对象是由若干个单字节构成的不可变序列。 由于许多主要二进制协议都基于 ASCII 文本编码,因此 bytes 对象供支持 ASCII 数据,并且在许多特性上与字符串对象相关方法相同。
想定义一个字节串和字节数组序列,可以通过字面值和内置函数来定义:
b'a' # b 前缀,引号中全为 ASCII 的形式,引号可为单、双、三引号
b'abc123554666588756' # 长度理论没有限制
b'我' # yntaxError: bytes can only contain ASCII literal characters
br'abc' # 禁止转义序列处理
rb'abc' # 同上
# 限制为 0 <= x < 256
bytes(10) # 指定长度的以零值填充的 bytes 对象
# b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
bytes(range(20)) # 通过由整数组成的可迭代对象
# b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b...'
obj = (1, 2)
bytes(obj) # 通过缓冲区协议复制现有的二进制数据
# b'\x01\x02'
bytes 字面值中只允许 ASCII 字符(无论源代码声明的编码为何),任何超出 127 的二进制值必须使用相应的转义序列形式加入 bytes 字面值。
字节串的构造函数
字节串构造函数bytes() 的四种用法总结如下:
| 函数 | 说明 |
|---|---|
| bytes() | 生成一个空的字节串,等同于 b'' |
| bytes(整型可迭代对象0~255) | 用可迭代对象初始化一个字节串 |
| bytes(整数n) | 生成 n 个值为 0 的字节串 |
| bytes(字符串,encoding='utf-8') | 用字符串的转换编码生成一个字节串 |
具体用法示例:
>> bytes()
b''
>> bytes(range(97,100))
b'abc'
>> bytes(3)
b'\x00\x00\x00'
>> bytes('中国', encoding='utf-8')
b'\xe4\xb8\xad\xe5\x9b\xbd'字节串的运算
字节串的运算按类别总结如下:
| 运算 | 详情 |
|---|---|
| 算数运算 | +、+= * 、*= |
| 比较运算 | <、<= > 、>= == 、!= |
| 成员运算 | in not in |
| 序列操作 | 索引 、切片 |
| 函数 | len() sum() max() min() any() all() |
bytes 和 str 的区别
bytes存储字节(0-255)str存储 Unicode 字符(0 - 65535或更大)
bytes 与 str转换
str ----------------- 编码(encode)----------------> bytes
>> s = "Hello YamFish"
>> b = s.encode('utf-8')
>> b
b'Hello YamFish'
>> s
'Hello YamFish'
bytes -------------- 解码(decode)----------------> str
>> b = b'\xe4\xbd\xa0\xe5\xa5\xbd\xe5\xb1\xb1\xe8\x8d\xaf\xe9\xb1\xbc\xe5\x84\xbf'
>> b.decode('utf-8')
'你好山药鱼儿'bytearray
bytearray 对象是 bytes 对象的可变对应对象,使用 bytearray() 内置函数创建:
bytearray() # 创建一个空实例
# bytearray(b'')
bytearray(10) # 创建一个指定长度的以零值填充的实例
# bytearray(b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00')
bytearray(range(20)) # 通过由整数组成的可迭代对象
bytearray(b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b...')
bytearray(b'Hi!') # 通过缓冲区协议复制现有的二进制数据
# bytearray(b'Hi!')
字节数组 bytearray
字节数组 bytearray 为可变的字节序列 。
创建函数
字节数组的构造函数 bytearray() :
| 函数 | 说明 |
|---|---|
| bytearray() | 生成一个空的字节数组 |
| bytearray(整型可迭代对象0~255) | 用可迭代对象生成一个字节数组 |
| bytearray(整数n) | 生成包含 n 个值为 0 的字节数组 |
| bytearray(字节串,encoding='utf-8') | 用字符串的转换编码生成一个字节数组 |
具体用法示例:
>> bytearray()
bytearray(b'')
>> ba = bytearray(range(65, 68))
>> ba
bytearray(b'ABC')
>> ba[1] = 98
>> ba
bytearray(b'AbC')
>> bytearray(3)
bytearray(b'\x00\x00\x00')
>> bytearray('中国', encoding='utf-8')
bytearray(b'\xe4\xb8\xad\xe5\x9b\xbd')字节数组是可变的字节序列,因此支持索引操作和切片赋值。
使用场景
bytes 的应用
bytes 只负责以字节序列的形式(二进制形式)来存储数据,至于这些数据到底表示什么内容(字符串、数字、图片、音频等),完全由程序的解析方式决定。如果采用合适的字符编码方式(字符集),字节串可以恢复成字符串;反之亦然,字符串也可以转换成字节串。
bytes 只是简单地记录内存中的原始数据,至于如何使用这些数据,bytes 并不在意,你想怎么使用就怎么使用,bytes 并不约束你的行为。
bytes 类型的数据非常适合在互联网上传输,可以用于网络通信编程;bytes 也可以用来存储图片、音频、视频等二进制格式的文件。
bytes 和 bytearray 关系
用 bytes 和 bytearray 可以非常方便的以字节为单位处理数据,比如网络中接收到的原始数据。
一个典型的场景,在读取 IO 数据流的时候,由于 bytes 不可变(无法追加),我们可以使用 bytearray。因用 bytes 接收数据流,每次读取一段内容都会生成一个新的对象,每次都需要重新分配内存。而使用 bytearray 等可变对象接收数据流,因为可变对象一般都有内存分配机制,每次分配内存时都会多分配一点,因此可以减少内存的分配次数。
类型转换
bytes 和 bytearray 之间,以及它们和其他基础数据类型可以进行转换。bytes 和 bytearray 之间的转换:
b = b'abc'
ba = bytearray(b) # bytearray(b'abc')
bytes(ba) # b'abc'
其他类型转为 bytes 和 bytearray:
s = 'hello'
b = s.encode()
b
# b'hello'
ba = bytearray(s.encode())
ba
# bytearray(b'hello')
i = 6
bytes(i)
# b'\x00\x00\x00\x00\x00\x00'
bytearray(i)
# bytearray(b'\x00\x00\x00\x00\x00\x00')
t = (1, 2, 3)
bytes(t)
# b'\x01\x02\x03'
bytearray(t)
# bytearray(b'\x01\x02\x03')
ser = pd.Series([1,2,3])
bytes(ser) # b'\x01\x02\x03'
bytearray(ser) # bytearray(b'\x01\x02\x03')
bytes 和 bytearray 转为其他类型:
b = b'123'
str(b) # "b'123'"
str(b, encoding='utf-8') # '123'
int(b) # 123
float(b) # 123.0
b = bytearray(b'123')
str(b) # "bytearray(b'123')"
str(b, encoding='utf-8') # '123'
int(b) # 123
float(b) # 123.0
内存视图 memoryview
bytes 和 bytearray 本质上依然是序列,与 list 或者 string 类似,也支持切片操作。Python 中的切片会创建一个完整的副本,比如 list[:5] 会创建一个新的 list 对象,包含了前 5 项数值。如果我们现在从一个文件中读取了一些数据,经过处理认为只需要将这些数据的前 10 字节保存起来,经典的做法是将 data[:10] 切片写入文件。正如前面提到的,切片的副本是完全可以避免的,这就可以借助 memoryview 获得更高效的实现。
memoryview 为内存视图,也可以理解为代理,通过这个代理操作内存对象时,不会触发内存的复制,也就是不会生成新的对象。
可以内置函数 memoryview() bytes-like 对象创建,object 必须支持缓冲区协议,支持缓冲区协议的内置对象有 bytes 和 bytearray 。
如,我们知道字符串的切片操作是会生成新的对象的,也就是触发了内存的复制:
s1 = b'abc'
s2 = s1[:] # 新的对象
如果我们通过memoryview 这个代理来操作切片,就不会生成新的对象:
b = b'abc'
b_proxy = memoryview(b)
b2 = b_proxy[:]
b2.tobytes()
# b'abc'
如果你需要把很长的字符串或数据流传递给函数作为参数,我觉得可以使用 memoryview 来提高性能。
bytes, bytearray 和 memoryview 在逻辑上可以类比以下 C 描述:
// bytes
char * data = "hello world";
// bytearray
char data[12] = "hello world";
// memoryview
char *p = data;
bytes 和 bytearray 操作
作为序列类型,支持序列类型的通用操作,与字符串类似,也支持类似字符串的一些操作,但也一些自己的特殊方法。
todo
相关操作
查看 utf-8 编码中英文字节占用量:
c = '我'.encode()
c
# b'\xe6\x88\x91'
type(c)
# bytes
len(c)
# 3
# 解码
c.decode()
# '我'
e = 'H'.encode()
e
# b'H'
type(e)
# bytes
len(e)
# 1

















 2311
2311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











