






Python数据分析之Pandas-1
基本介绍
- pandas是基于numpy的一种工具,该工具是为了解决数据分析任务而创建的。pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数与方法。
- 导入库:
代码如下:
import pandas as pd
import numpy as np
基本数据结构
pandas中有两种常用的基本结构:
- Series
- 一维数组,与numpy中的一维array类似。二者与Python基本的数据结构List也很相近。Series能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
- DateFrame
- 二维的表格数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下内容主要以DataFrame为主。
series类型
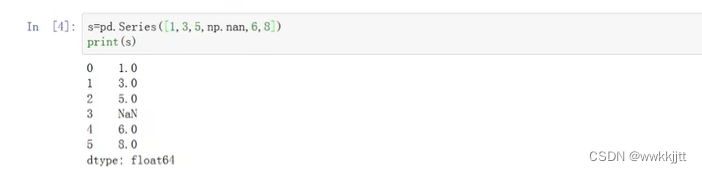
- pandas库的 一维Series可以用一维列表初始化:
- 默认情况下,series的下标都是数字(可以使用额外参数指定),类型是统一的。
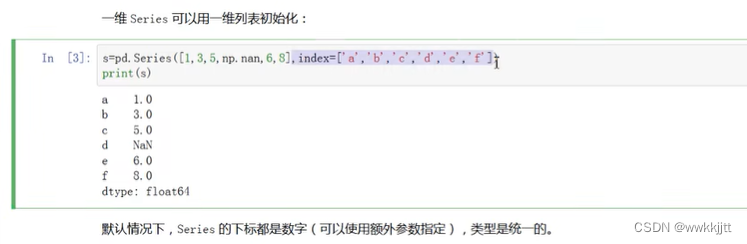
- 通过index来指定下标:
- 查看索引(数据的行标签)

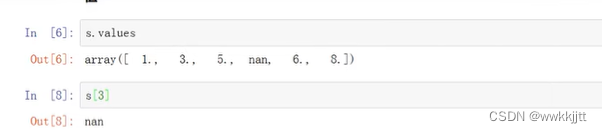
- 查看series的整个数组的值,查看series索引为3位置的值:
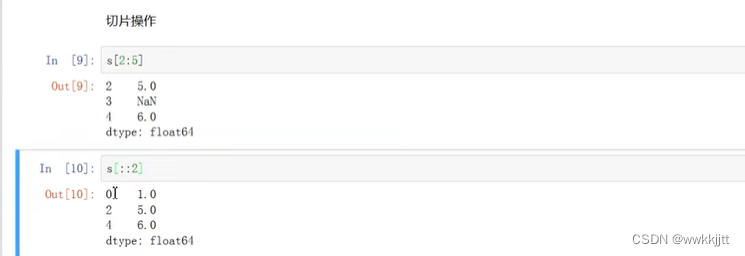
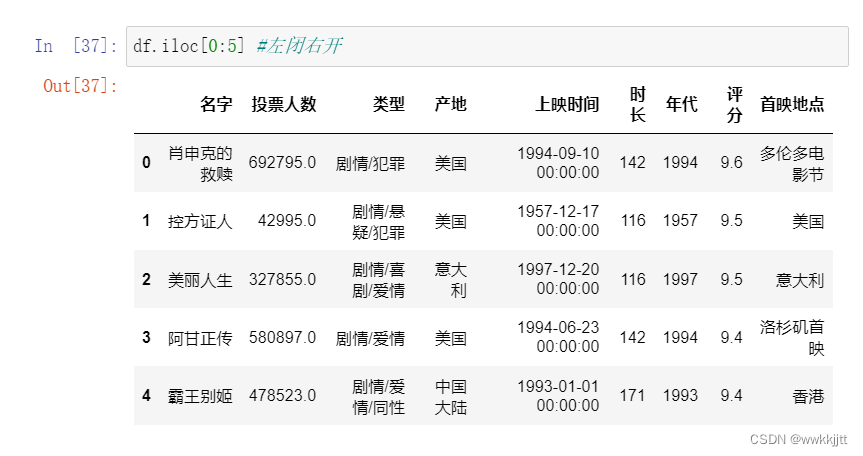
- 切片操作[开始:结束:步长],左闭右开:
- 索引赋值,给索引命名:
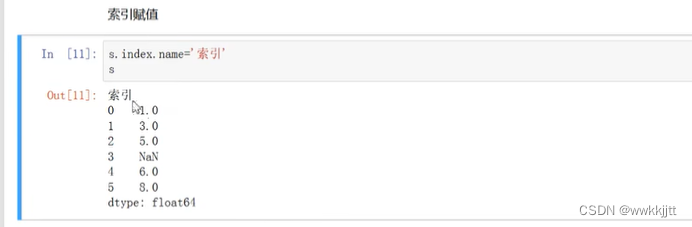
- 将索引用列表的方式更换为“abcdef”:
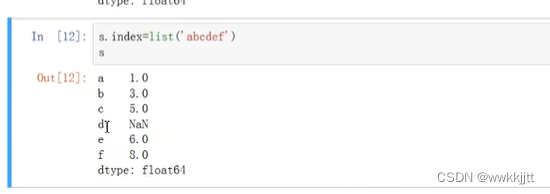
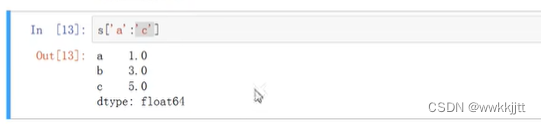
- 通过“abcdef”的索引方式对一维数组切片,左闭右闭:
DataFrame类型
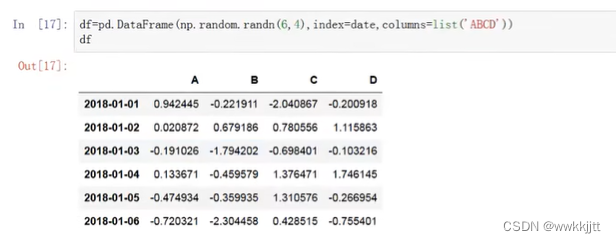
- pandas库的DataFrame是个二维结构,这里首先构造一组时间序列,作为我们第一位的下标。从2018年1月1日起,创建6个时间。

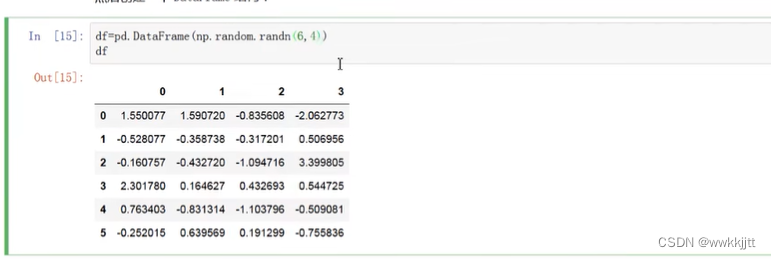
- 用传入二维数组(np生成正态分布的6行4列的随机数)的方式,创建一个DataFrame结构。默认情况下不指定index和columns,那它们的值将用从0开始的数字代替。
- 这里我们用刚刚创建的时间序列,指定index的值;用“ABCD”指定columns的值,将得到以下DataFrame结构:
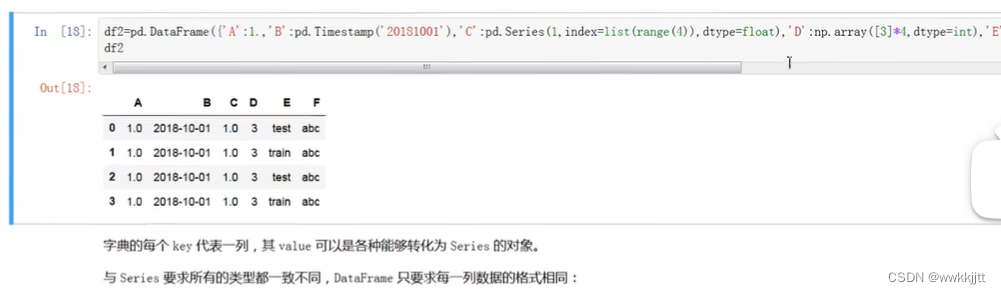
- 除了向DataFrame传入二维数组的方式,还可以使用字典传入数据。如下示例:
查看数据
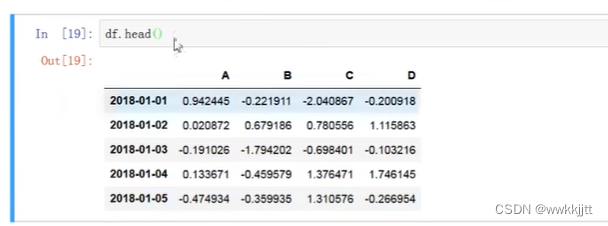
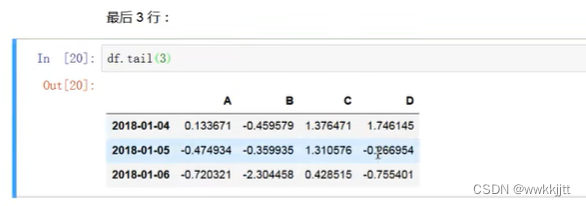
- 头尾数据:head和tail方法可以分别查看最前面的几行和最后面的几行。(默认是5行)
- 下标:使用index属性查看

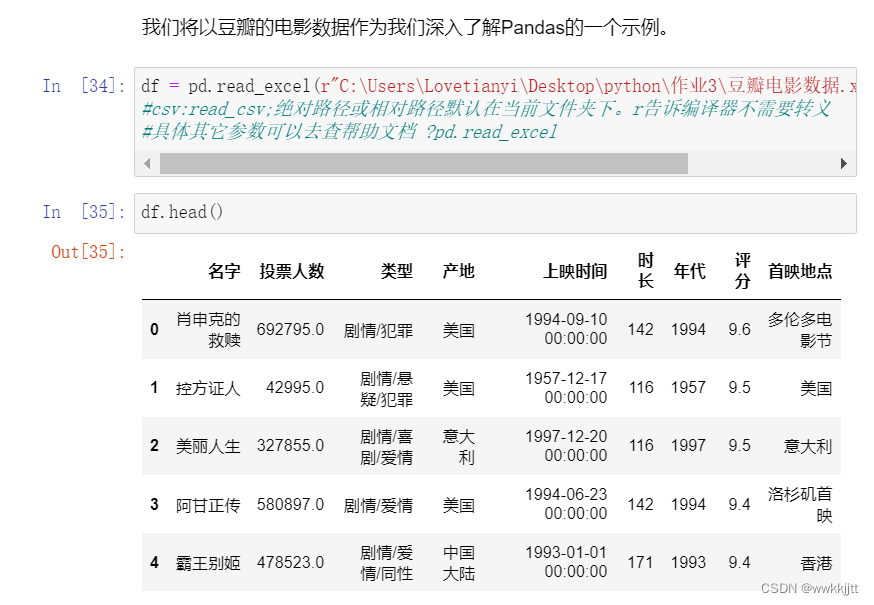
数据读取与数据操作
- 行操作:
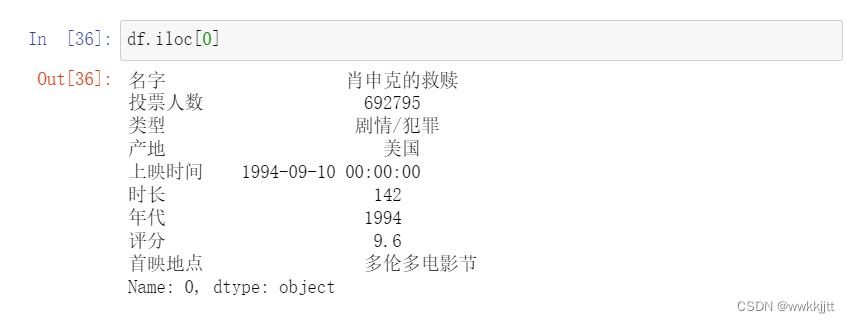
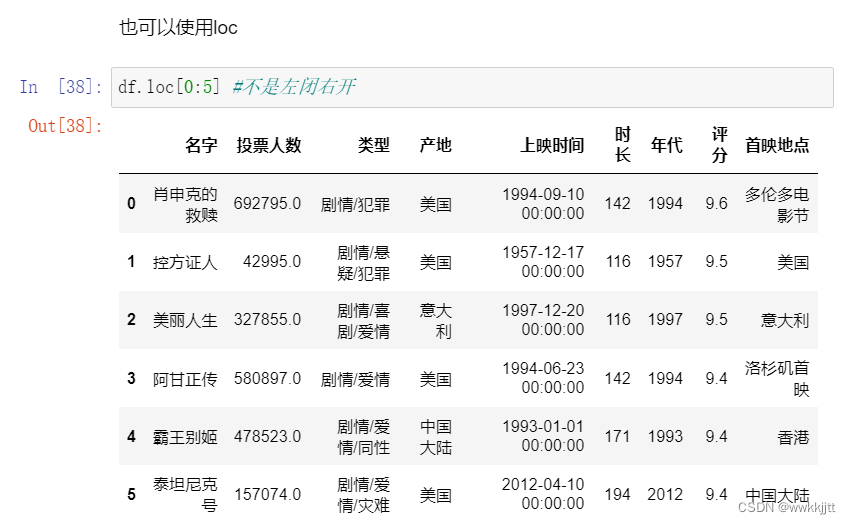
- 使用iloc()函数或者loc()函数,获取某几行的数据。
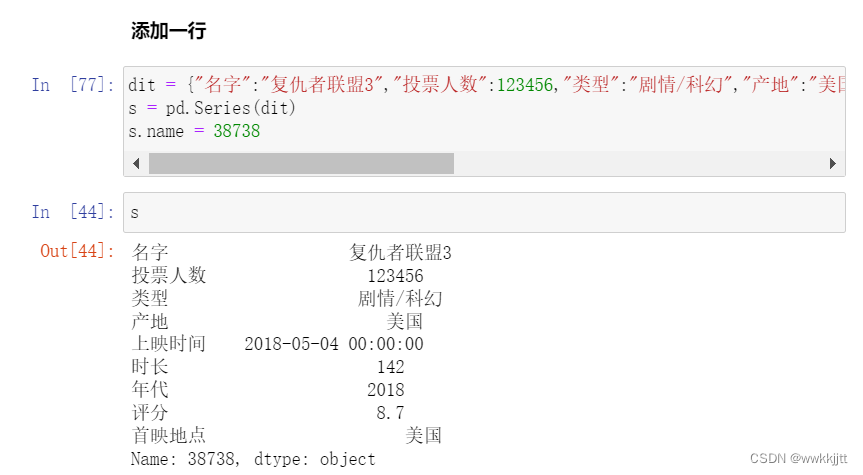
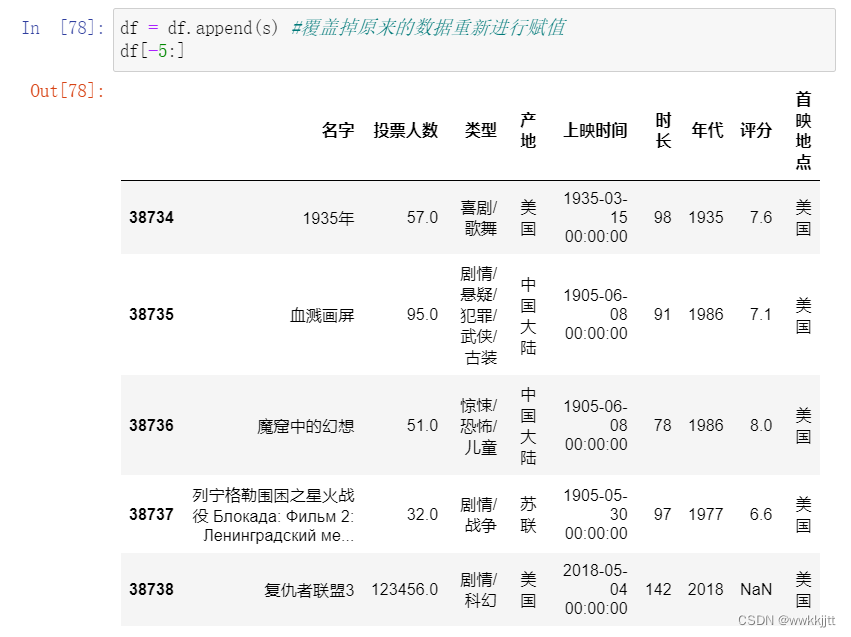
- 添加一行:使用字典传入新添加这一行的数据,再转成一维数组。再使用append()函数将这一行添加到原二维数组。
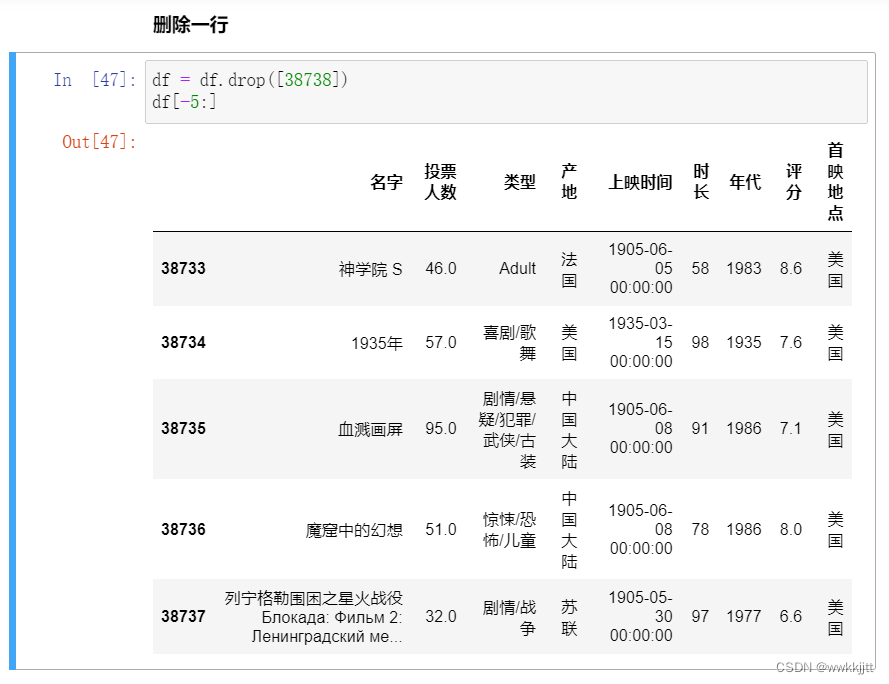
- 删除一行:使用drop()函数,将刚添加的那一行删去。
- 使用iloc()函数或者loc()函数,获取某几行的数据。
- 列操作:
-
使用df.columns显示df数组的所有列字段。用df[‘列名称’]查看莫一列的数据。

-
增加一列:新增一列,可以用df[‘新一列的名称’]的方式。

-
删除一列:使用drop()函数,将列名称作为参数。axis参数用于指定删除的方向,默认值为0,表示删除行;指定为1时,表示删除列。
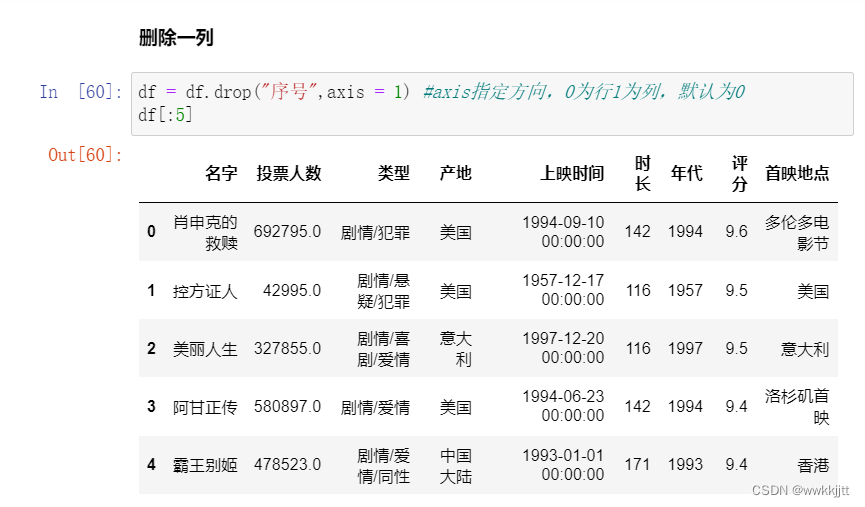
-
通过标签选择数据:指定行,指定列即可。

-
- 条件选择:
- 使用字段的判断来选取,
df['产地']=="美国"的返回值为bool类型。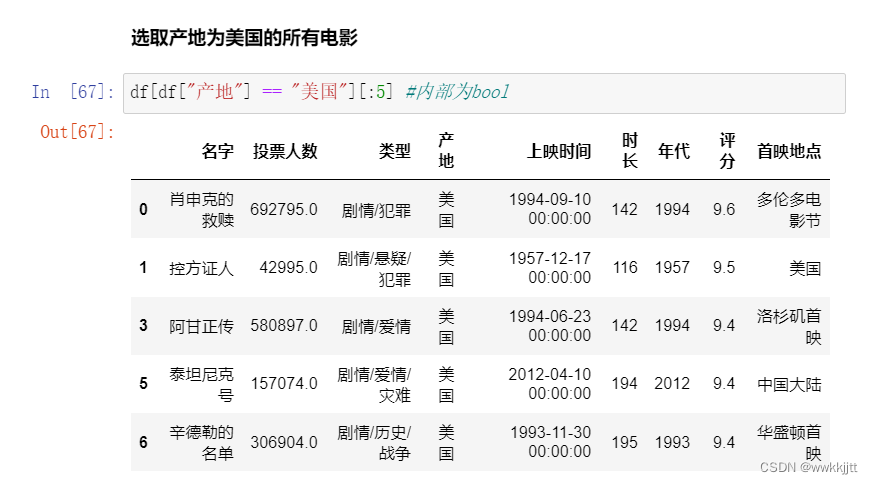
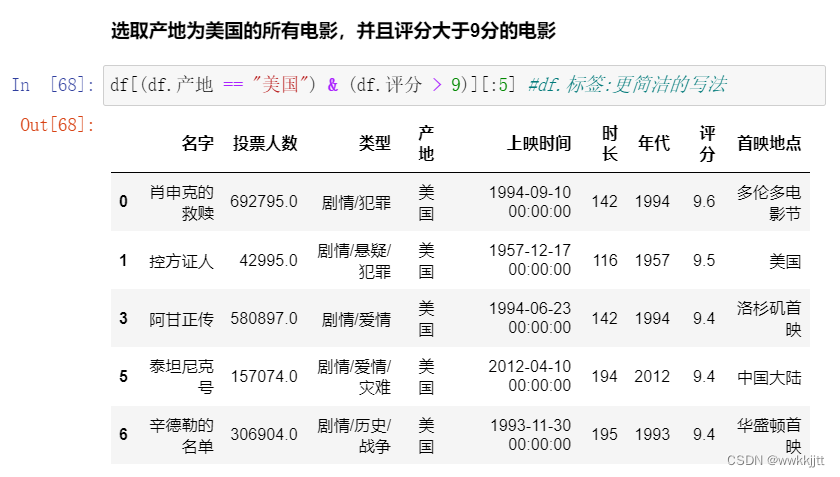
- 使用字段的判断来选取,
缺失值及异常处理
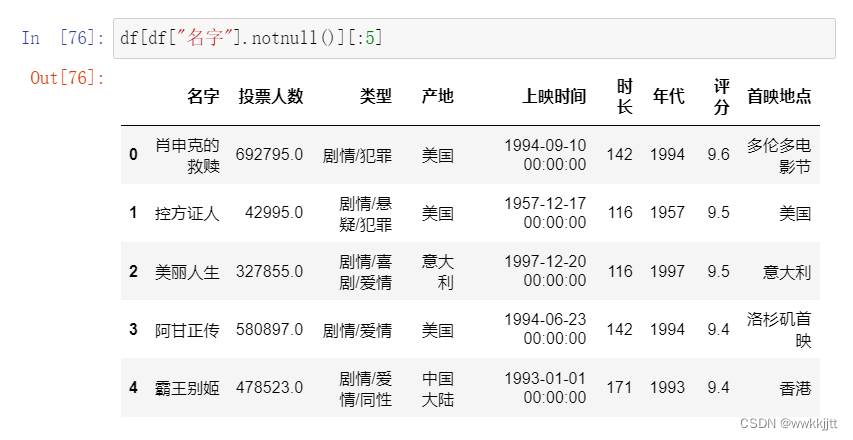
- 缺失值的处理方法

- 判断确实值
- 填充缺失值
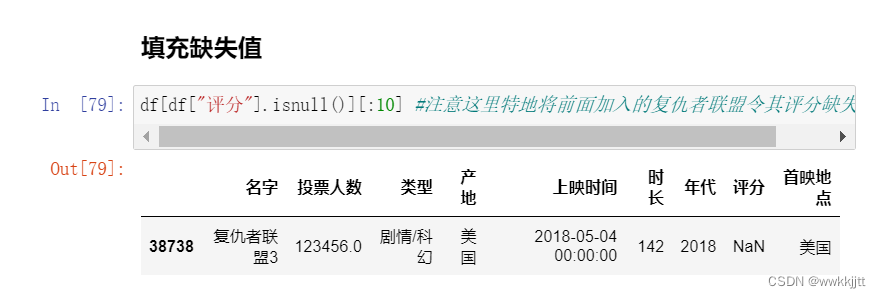


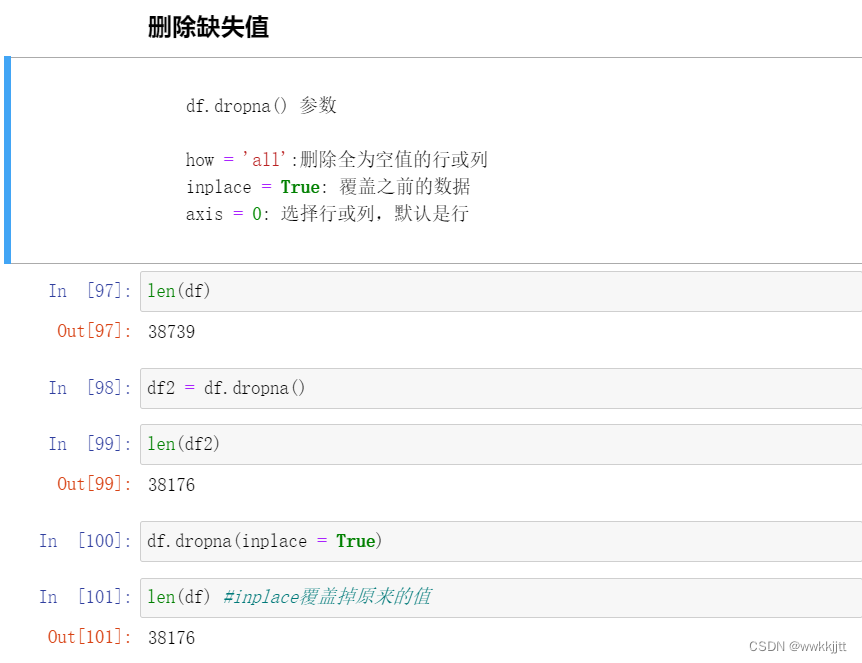
- 删掉缺失值:使用dropna()函数
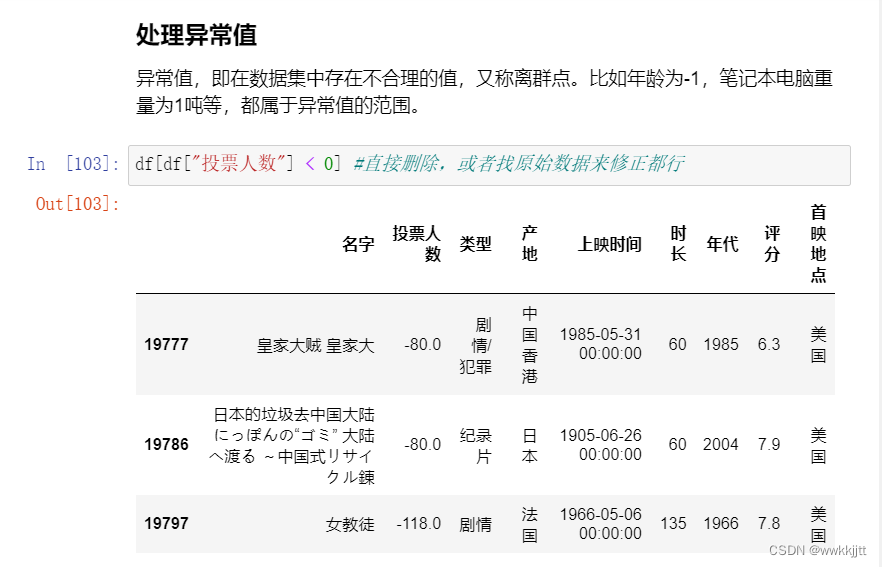
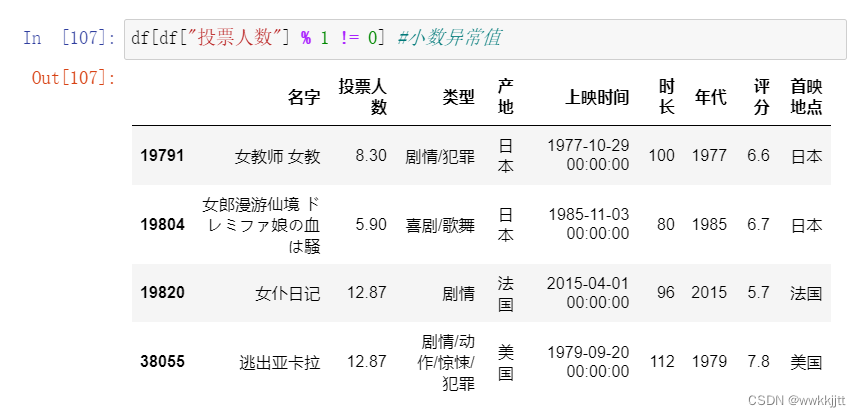
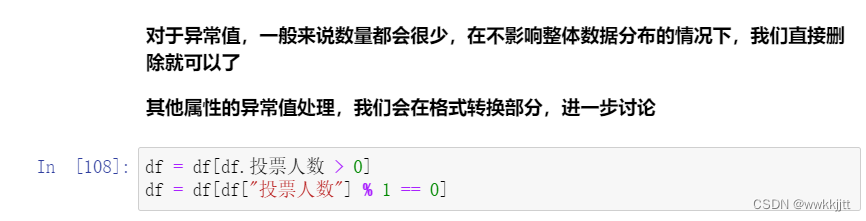
- 处理异常值
数据保存

以上就是本文的全部内容,感谢各位的阅读与支持!














 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









