






一、为什么要进行模型评估?
模型评估在机器学习和人工智能领域扮演着至关重要的角色。模型评估是确保机器学习模型在实际应用中有效、可靠且符合预期的关键步骤。它不仅帮助开发者理解和改进模型,还为最终用户提供了信心和保证。在模型开发的整个生命周期中,持续和全面的评估对于实现高质量的AI解决方案至关重要。
二、模型评估常用方法?
分类模型常用评估方法:
| 指标 | 描述 |
|---|---|
| Accuracy | 准确率 |
| Precision | 精准度/查准率 |
| Recall | 召回率/查全率 |
| P-R曲线 | 查准率为纵轴,查全率为横轴,作图 |
| F1 | F1值 |
| Confusion Matrix | 混淆矩阵 |
| ROC | ROC曲线 |
| AUC | ROC曲线下的面积 |
回归模型常用评估方法:
| 指标 | 描述 |
|---|---|
| Mean Square Error (MSE, RMSE) | 平均方差 |
| Absolute Error (MAE, RAE) | 绝对误差 |
| R-Squared | R平方值 |
三、 案例应用
以k-NN算法为例,当k取不同值时,分别绘制P-R曲线和ROC曲线,观察曲线变化,以下是具体的代码和结果实现:
(1)P-R曲线
-
import numpy as np -
import matplotlib.pyplot as plt -
from sklearn.datasets import make_classification -
from sklearn.model_selection import train_test_split -
from sklearn.neighbors import KNeighborsClassifier -
from sklearn.metrics import precision_recall_curve, auc -
from sklearn.preprocessing import StandardScaler -
# 生成一些样本数据 -
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42) -
# 数据标准化 -
scaler = StandardScaler() -
X = scaler.fit_transform(X) -
# 划分训练集和测试集 -
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) -
# 不同k值下的PR曲线 -
k_values = [1, 3, 5, 7, 9] -
plt.figure(figsize=(8, 6)) -
for k in k_values: -
knn = KNeighborsClassifier(n_neighbors=k) -
knn.fit(X_train, y_train) -
y_score = knn.predict_proba(X_test)[:, 1] -
precision, recall, _ = precision_recall_curve(y_test, y_score) -
pr_auc = auc(recall, precision) -
plt.plot(recall, precision, label=f'k={k}, AUC={pr_auc:.2f}') -
plt.xlabel('Recall') -
plt.ylabel('Precision') -
plt.title('PR Curve for KNN with Different k Values') -
plt.legend() -
plt.show() -
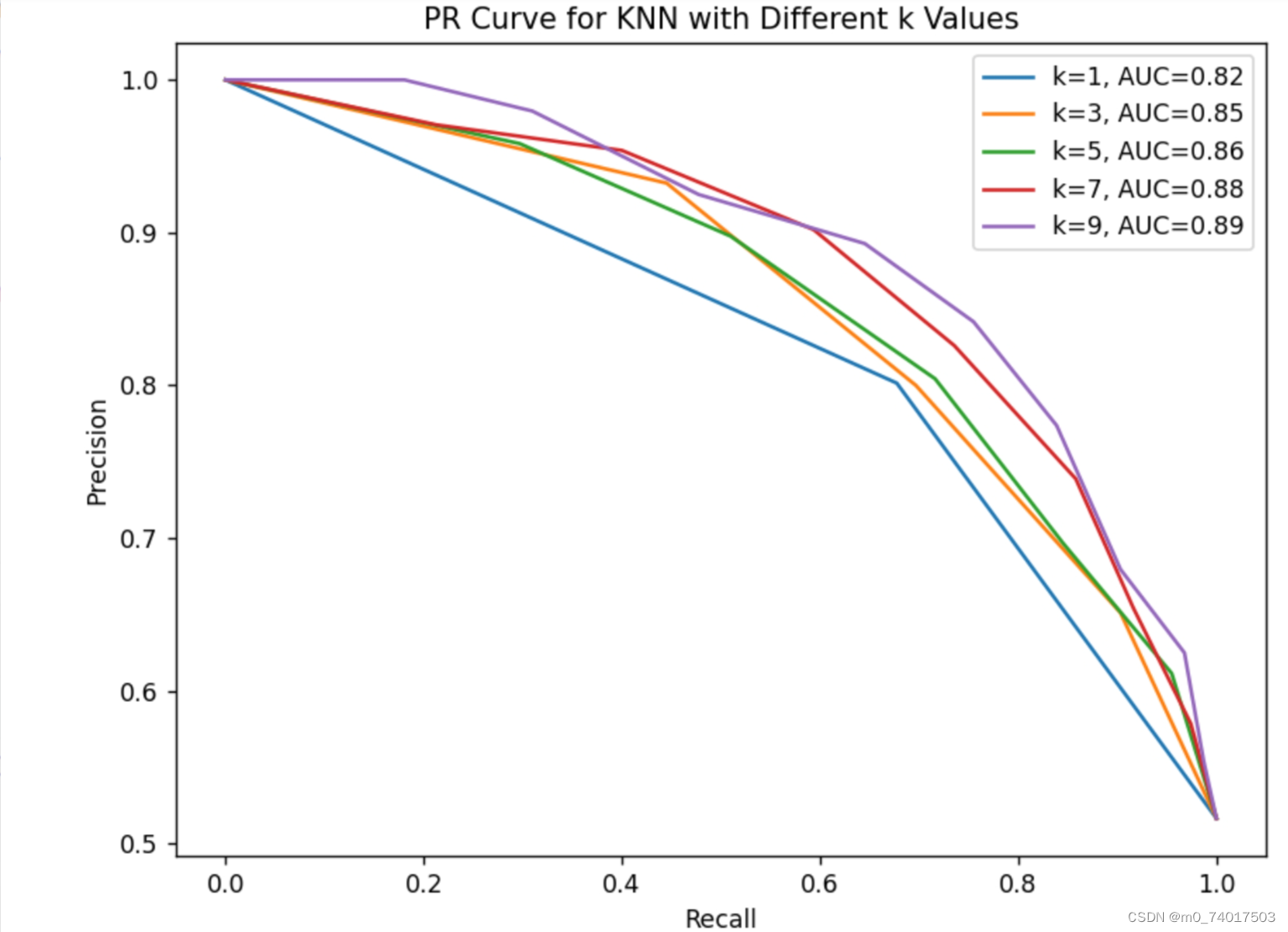
(2)ROC曲线
-
import numpy as np -
import matplotlib.pyplot as plt -
from sklearn.datasets import make_classification -
from sklearn.model_selection import train_test_split -
from sklearn.neighbors import KNeighborsClassifier -
from sklearn.metrics import roc_curve, auc -
from sklearn.preprocessing import StandardScaler -
# 生成一些样本数据 -
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42) -
# 数据标准化 -
scaler = StandardScaler() -
X = scaler.fit_transform(X) -
# 划分训练集和测试集 -
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) -
# 不同k值下的ROC曲线 -
k_values = [1, 3, 5, 7, 9] -
plt.figure(figsize=(8, 6)) -
for k in k_values: -
knn = KNeighborsClassifier(n_neighbors=k) -
knn.fit(X_train, y_train) -
y_score = knn.predict_proba(X_test)[:, 1] -
fpr, tpr, _ = roc_curve(y_test, y_score) -
roc_auc = auc(fpr, tpr) -
plt.plot(fpr, tpr, label=f'k={k}, AUC={roc_auc:.2f}') -
plt.plot([0, 1], [0, 1], linestyle='--', color='grey', label='Random Guess') -
plt.xlabel('False Positive Rate') -
plt.ylabel('True Positive Rate') -
plt.title('ROC Curve for KNN with Different k Values') -
plt.legend() -
plt.show()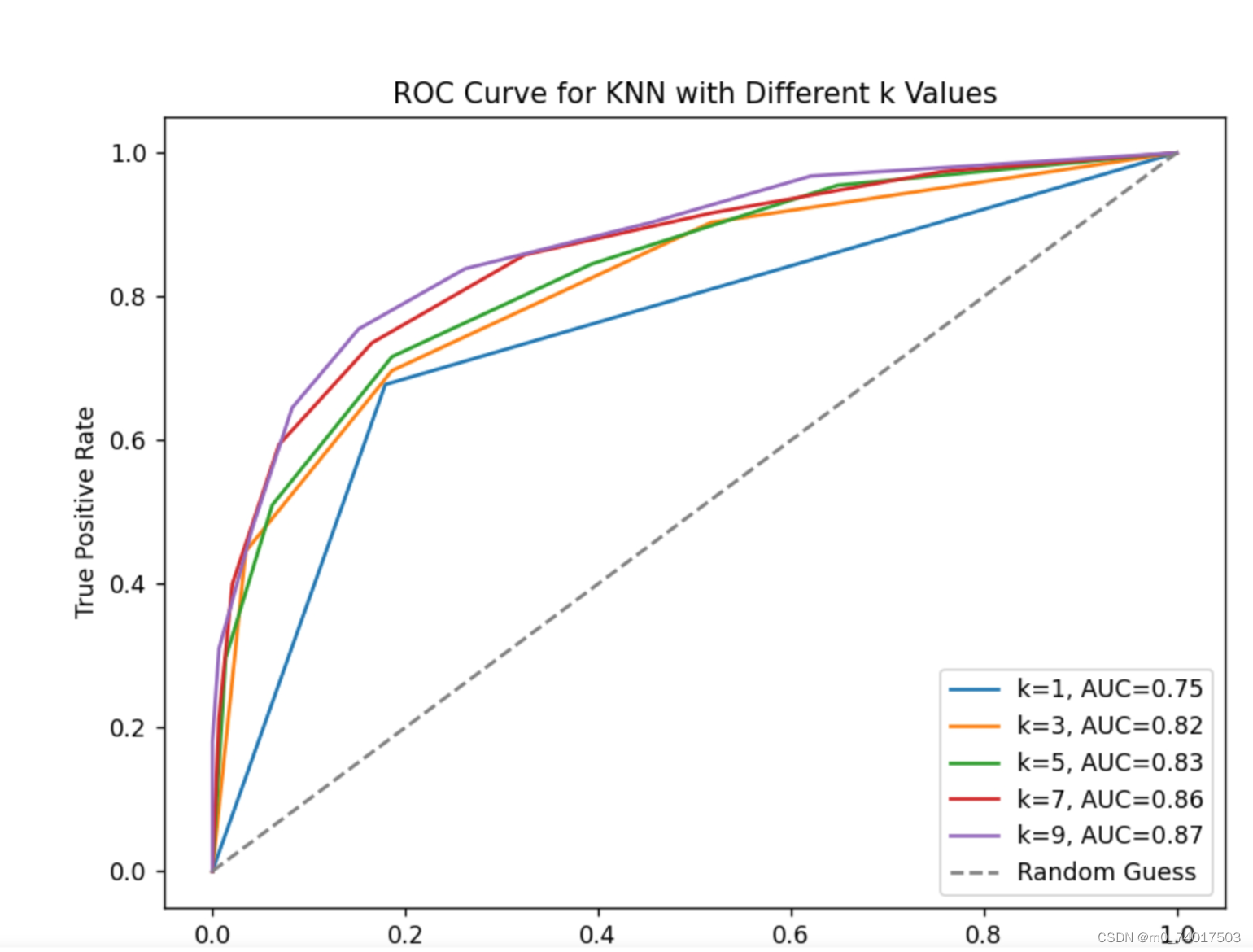
四、实验总结
通过模型评估,我们可以确定模型的准确性、泛化能力和稳定性,以及是否存在过拟合或欠拟合等问题,常用的评估指标包括准确率、精确率、召回率等。另外,对于不同类型的问题,还可以采用不同的评估方法,如P-R曲线、ROC曲线、混淆矩阵等。综上所述,模型评估在机器学习中是至关重要的,可以帮助我们提高模型的性能和效果。















 3434
3434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









