






训练部分
数据集的划分
必须要按照如下格式: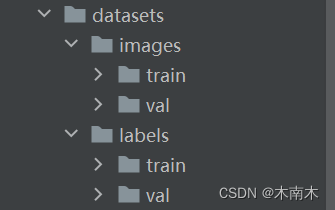
yolo查找标签时会自动在“训练集”和“验证集”的上一级目录的labels下对应目录下的对应标签文件
总之这样划分就行了
修改data配置文件

随便选一个.yaml文件,都不影响

把不必要的部分删掉(下载数据的部分),把数据集的路径填进去,标注类别填进去。这里可以不要test数据,不填就行了。
修改model配置文件

将nc改为你的类别数
下载权重文件
去官网下载,为.pt文件,有的权重还比较大
在releases下的assets(资源)中

修改train

在此我们主要设置如下参数
weight:将下载好的权重路径放入,也可以空,表示不用预训练的权重
cft:模型路径
data:数据集路径
根据自己的配置修改相应的batchsize、epochs
这些参数做一个简单说明:
-
--weights: 初始权重的路径。
-
--cfg: 模型配置文件的路径。
-
--data: 数据集配置文件的路径。
-
--hyp: 超参数文件的路径。
-
--epochs: 训练的总轮数。
-
--batch-size: 所有 GPU 上的总批量大小。
-
--img-size: 训练和测试图像的大小。默认为 [640, 640]。
-
--rect: 如果设置,表示使用矩形训练。
-
--resume: 如果设置,表示继续最近的训练。
-
--nosave: 如果设置,表示只保存最终的检查点。
-
--notest: 如果设置,表示只测试最终的轮次。
-
--noautoanchor: 如果设置,表示禁用自动anchor检查。
-
--evolve: 如果设置,表示演化超参数。
-
--bucket: gsutil bucket。
-
--cache-images: 如果设置,表示缓存图像以加快训练速度。
-
--image-weights: 如果设置,表示使用加权图像选择进行训练。
-
--device: 训练设备,可以是 cuda 设备(例如,'0' 或 '0,1,2,3')或者 'cpu'。
-
--multi-scale: 如果设置,表示变化 img-size +/- 50%。
-
--single-cls: 如果设置,表示将多类数据训练为单类。
-
--adam: 如果设置,表示使用 torch.optim.Adam() 优化器。
-
--sync-bn: 如果设置,表示使用 SyncBatchNorm,只在 DDP 模式下可用。
-
--local_rank: DDP 参数,不要修改。
-
--workers: 数据加载器工作线程的最大数量。默认为 8。
-
--project: 保存结果的项目路径。默认为 'runs/train'。
-
--entity: W&B 实体。
-
--name: 保存结果的项目名称。默认为 'exp'。
-
--exist-ok: 如果设置,表示存在的项目/名称是允许的,不会自动递增编号。
-
--quad: 如果设置,表示使用 quad 数据加载器。
-
--linear-lr: 如果设置,表示使用线性学习率。
-
--label-smoothing: 标签平滑的 epsilon 值。默认为 0.0。
-
--upload_dataset: 如果设置,表示将数据集上传为 W&B artifact 表。
-
--bbox_interval: 设置用于 W&B 的边界框图像记录间隔。
-
--save_period: 设置每个 "save_period" 轮后记录模型。
-
--artifact_alias: 用于选择数据集 artifact 版本的别名。默认为 "latest"。
好!开始炼丹(训练)
接下来所遇到的问题
wandb.errors.UsageError: api_key not configured (no-tty). call wandb.login(key=[your_api_
具体原因:未设置api-key值
RuntimeError: result type Float can‘t be cast to the desired output type long int
找到utils下的loss.py
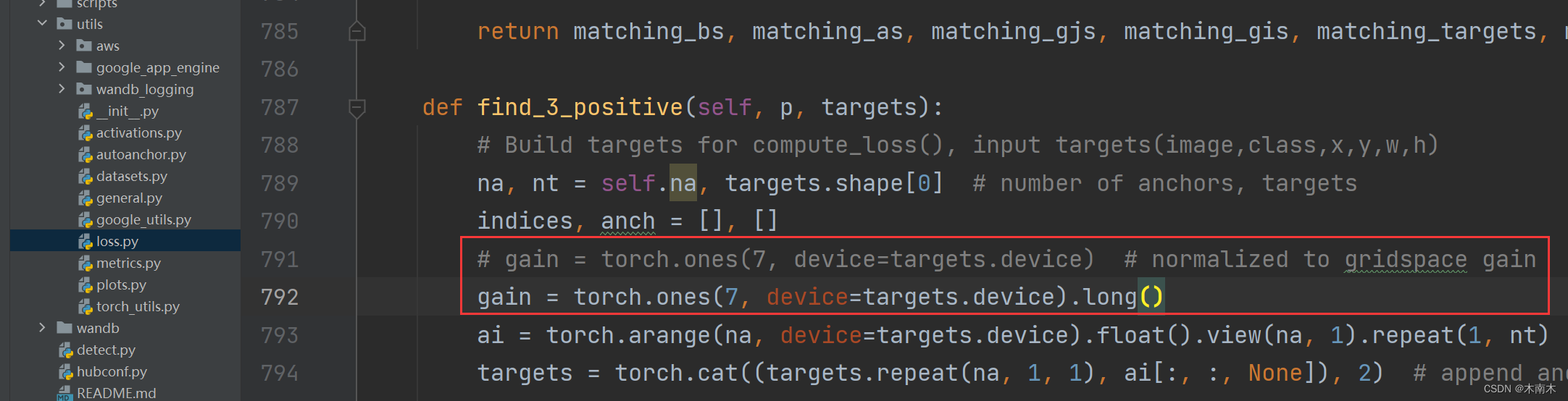
# gain = torch.ones(7, device=targets.device) # 注释此行
gain = torch.ones(7, device=targets.device).long() # 修改为此行具体原因:新版本的torch无法自动执行此转换,旧版本torch可以
Images sizes do not match. This will causes images to be display incorrectly in the UI
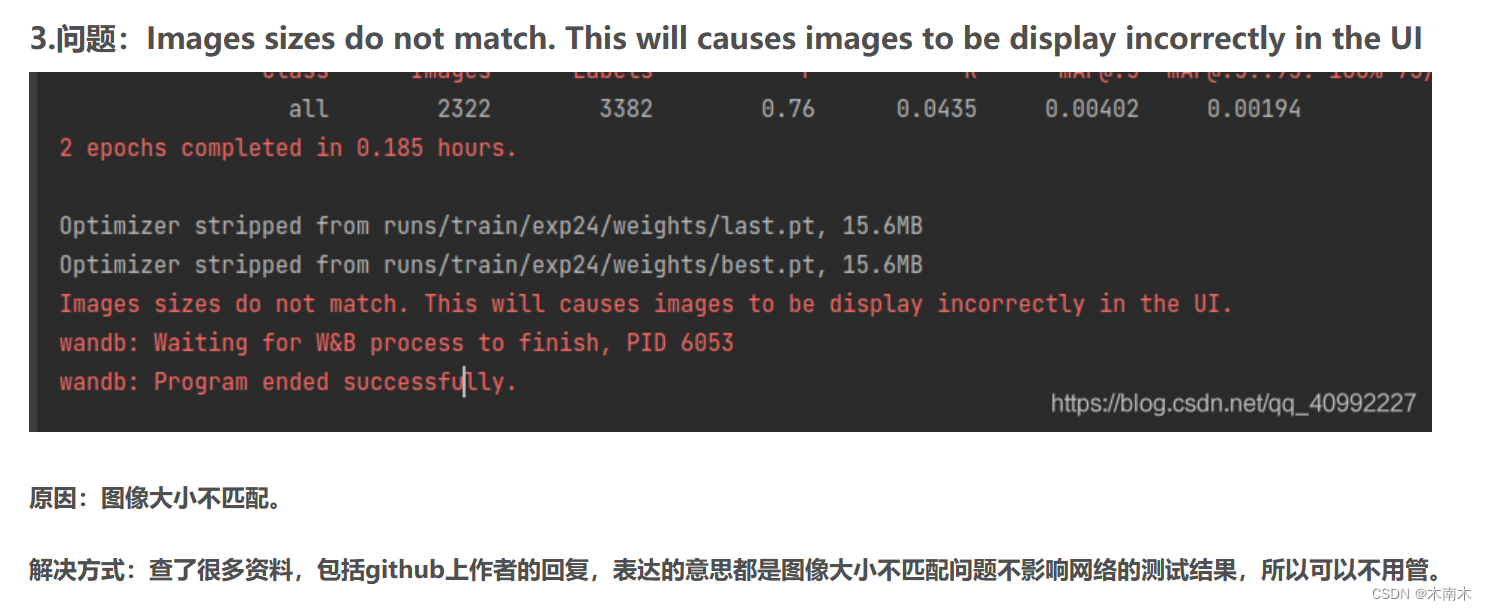
未解决,但不影响使用
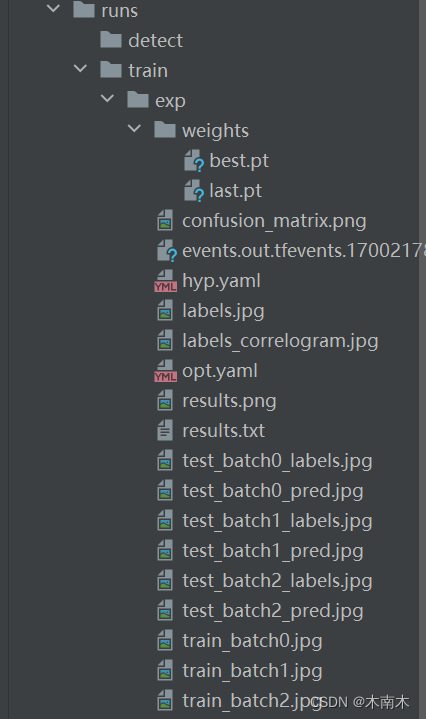
训练完后会在run/train下保存有.pt的训练权重模型和一些结果图片
推理模式

-
--weights: 模型权重的路径,可以指定一个或多个权重文件。
-
--source: 推理的输入源,可以是文件路径、文件夹路径,或者使用摄像头时为 0。
-
--img-size: 推理时的图像大小(像素)。默认值为 640。
-
--conf-thres: 目标置信度阈值,低于此阈值的目标将被过滤。
-
--iou-thres: 非极大值抑制(NMS)的 IoU 阈值,用于去除重叠较大的边界框。默认值为 0.45。
-
--device: 推理设备,可以是 cuda 设备(例如,'0' 或 '0,1,2,3')或者 'cpu'。默认为空字符串,表示使用默认设备。
-
--view-img: 如果设置,将显示推理结果。
-
--save-txt: 如果设置,将结果保存为文本文件(*.txt)。
-
--save-conf: 如果设置,将置信度信息保存到 --save-txt 指定的标签文件中。
-
--nosave: 如果设置,将不保存推理结果的图像或视频。
-
--classes: 指定要过滤的目标类别。可以指定一个或多个类别的索引,例如,--classes 0 或 --classes 0 2 3。
-
--agnostic-nms: 如果设置,使用类别无关的 NMS。
-
--augment: 如果设置,进行推理时使用数据增强。
-
--update: 如果设置,将更新所有模型。
-
--project: 保存结果的项目路径。默认为 'runs/detect'。
-
--name: 保存结果的项目名称。默认为 'exp'。
-
--exist-ok: 如果设置,表示存在的项目/名称是允许的,不会自动递增编号。
设置一个好的置信度和iou还挺重要的














 3870
3870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









