






机器学习入门知识
一、机器学习概述
1.1机器学习介绍
1.1.1机器学习的特点
(1)机器学习和传统编程
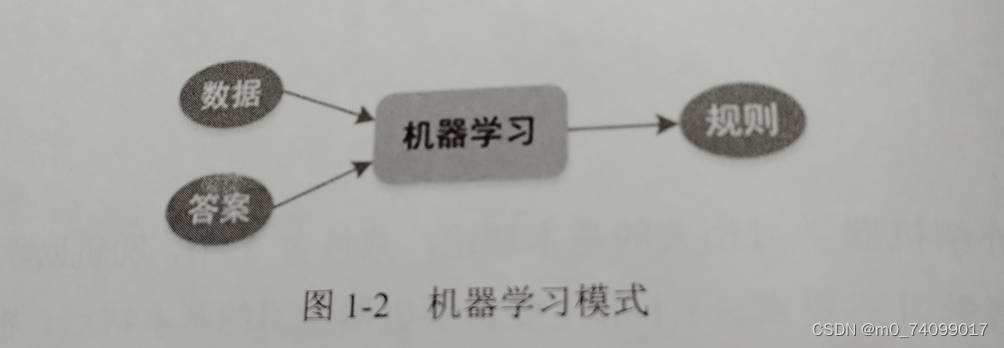
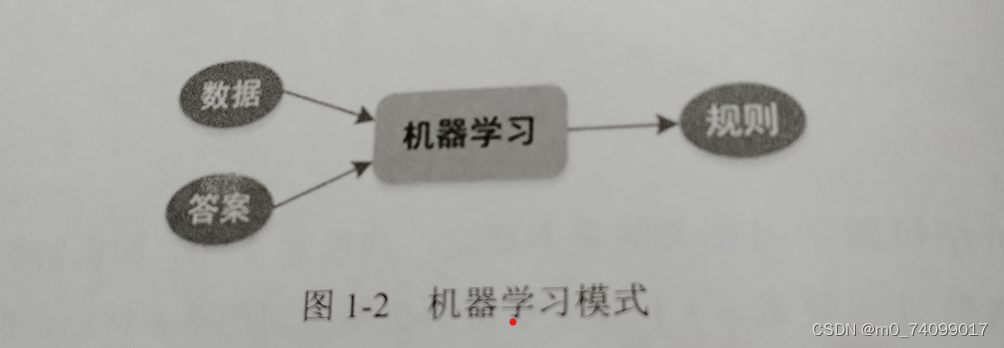
传统编程其实是基于规则和数据的,目的是快速得到一个答案;
机机器学习其实是从已知的数据和答案中寻找出来某种规则。
!](https://img-blog.csdnimg.cn/aa169ca3b5ee47099489a4e8fe223d96.jpeg)
总结:以计算机为工具平台,以数据研究为对象,以学习方法为中心,是概率论、线性代数、信息论、最优化理论和计算机科学等多个领域的交叉学科。
(2)研究的三个应用方面
- 机器学习方法:只在开发新的方法
- 机器学习理论:旨在探求机器学习方法的有效性和效率
- 机器学习应用:考虑将机器学习模型应用到实际问题中去,解决实际业务问题
1.1.2机器学习的对象
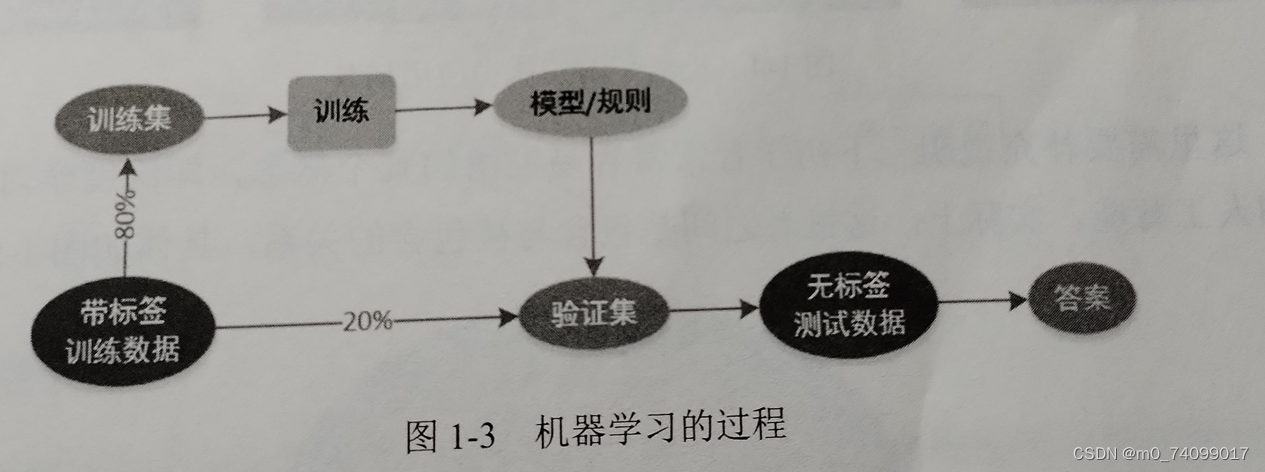
机器学习对象是数据,即从数据出发,提取数据的特征,抽象出数据模型,发现数据中的规律,再回到对新的数据的分析和预测中去。
1.1.3机器学习的应用
(1)应用前景广泛

(2)机器学习的人工智能、深度学习的关系

1.2机器学习分类
1.2.1按任务类型分类
1
- 回归问题
利用数理统计中的回归分析技术 ,确定两种变量间的依赖关系 - 分类问题
常见的一类任务|将不同形式的数据分开 - 聚类问题
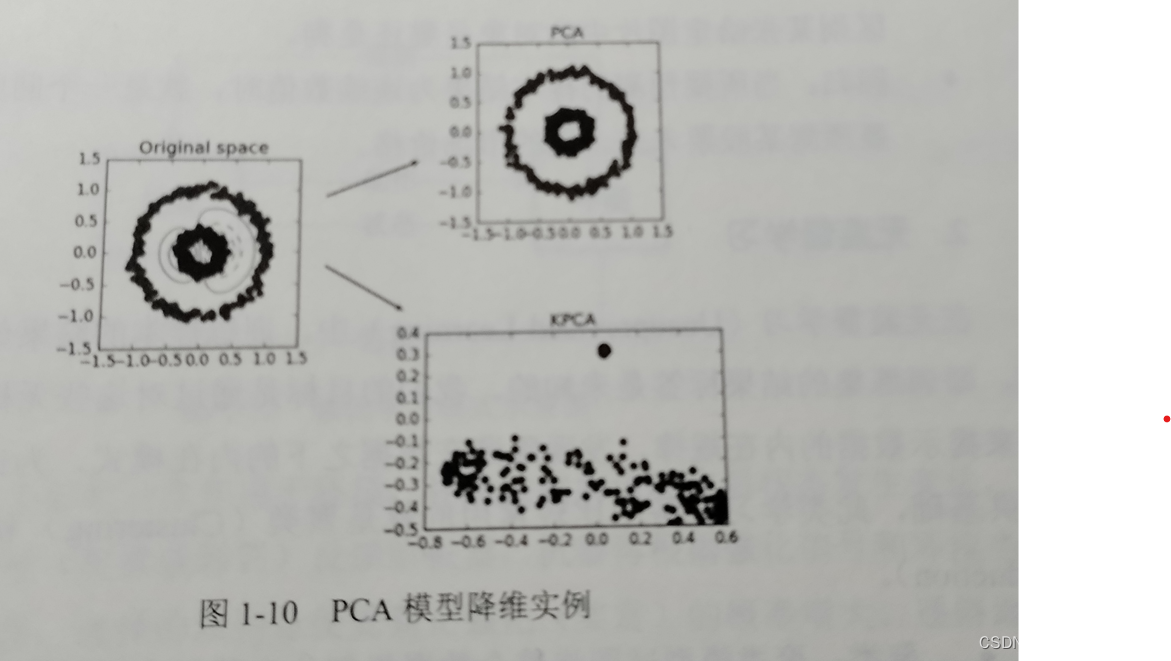
聚类问题又称群分析,目标将样本划分为紧密关系的子集或簇 - 降维分析
采用某种映射的方法,将原高维空间中的数据点映射到低维空间
降维模型有组成分析(PCA)和线性判断分析(LDA)等
通过模型来达到消除冗余信息、降噪和减少特征量的目的
1.2.2按学习方法分类
- 有监督学习
基于一组带有结果标注的样本训练模型,然后用该模型对新的未知结果的样本做出预测。
常见的学习任务是分类和回归。 - 无监督学习
训练样本结果是没有被标记注的,即训练的结果标签是未知的。
常见的是聚类和降维。 - 强化学习
又称再励学习、评价学习,是从动物学习、参数扰动自适应控制等理论发展而来的。它把学习过程看作一种试探评价过程。
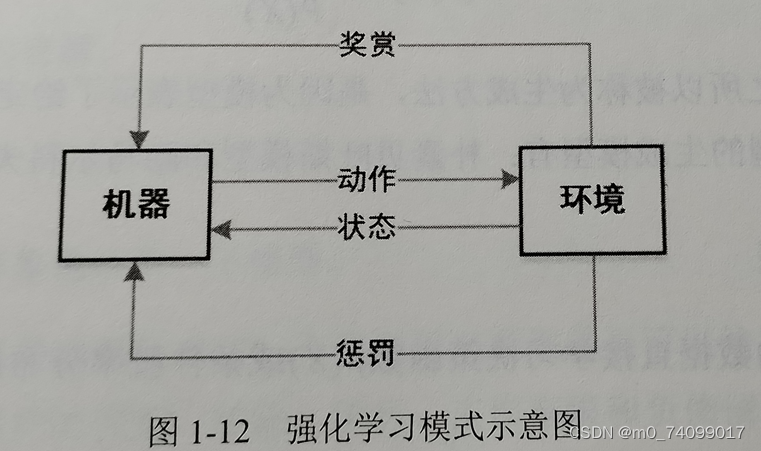
1.2.3生成模型与判别模型
(1)生成模型



(2)判别模型
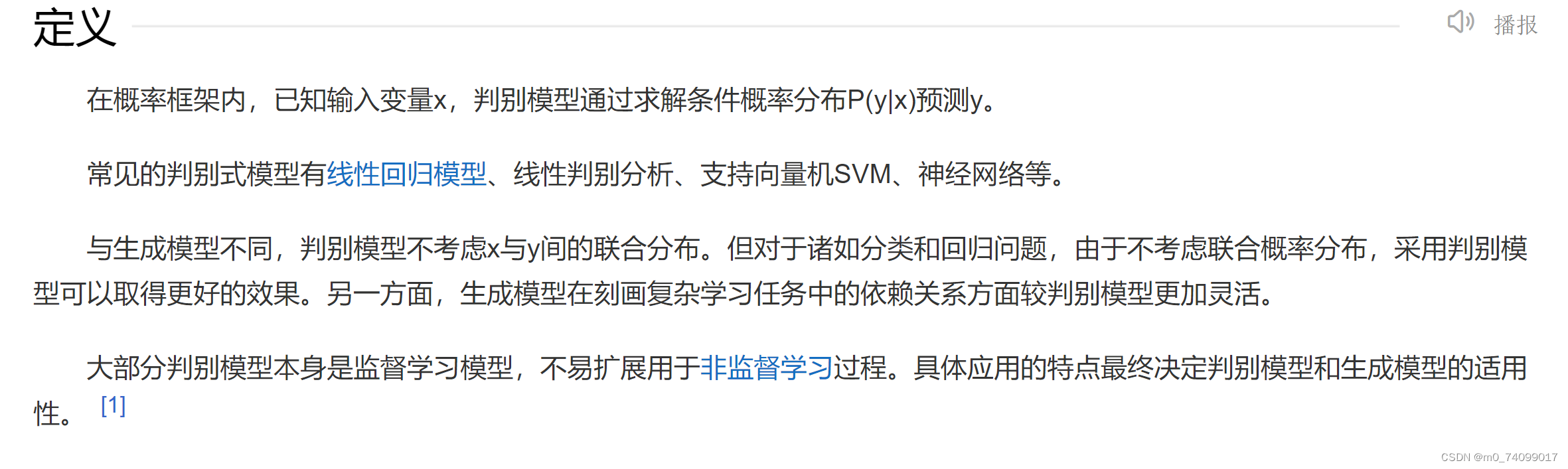
1.3机器学习方法三要素

1.3.1模型

1.3.2策略


1.2.3算法

- 梯度下降法
- 牛顿法
- 拟牛顿法
二、机器学习工程实践
2.1模型评估指标
2.1.1回归模型的评估指标
- 绝对误差
绝对误差即预测点与真实点之间距离之差的绝对平均值 - 均方误差
均方误差即预测点与实际点之间距离之差平方和的均值
2.1.2分类模型的评估指标
-
准确率(accuracy)

-
精度(precision)

-
召回率(recall)

-
F1值
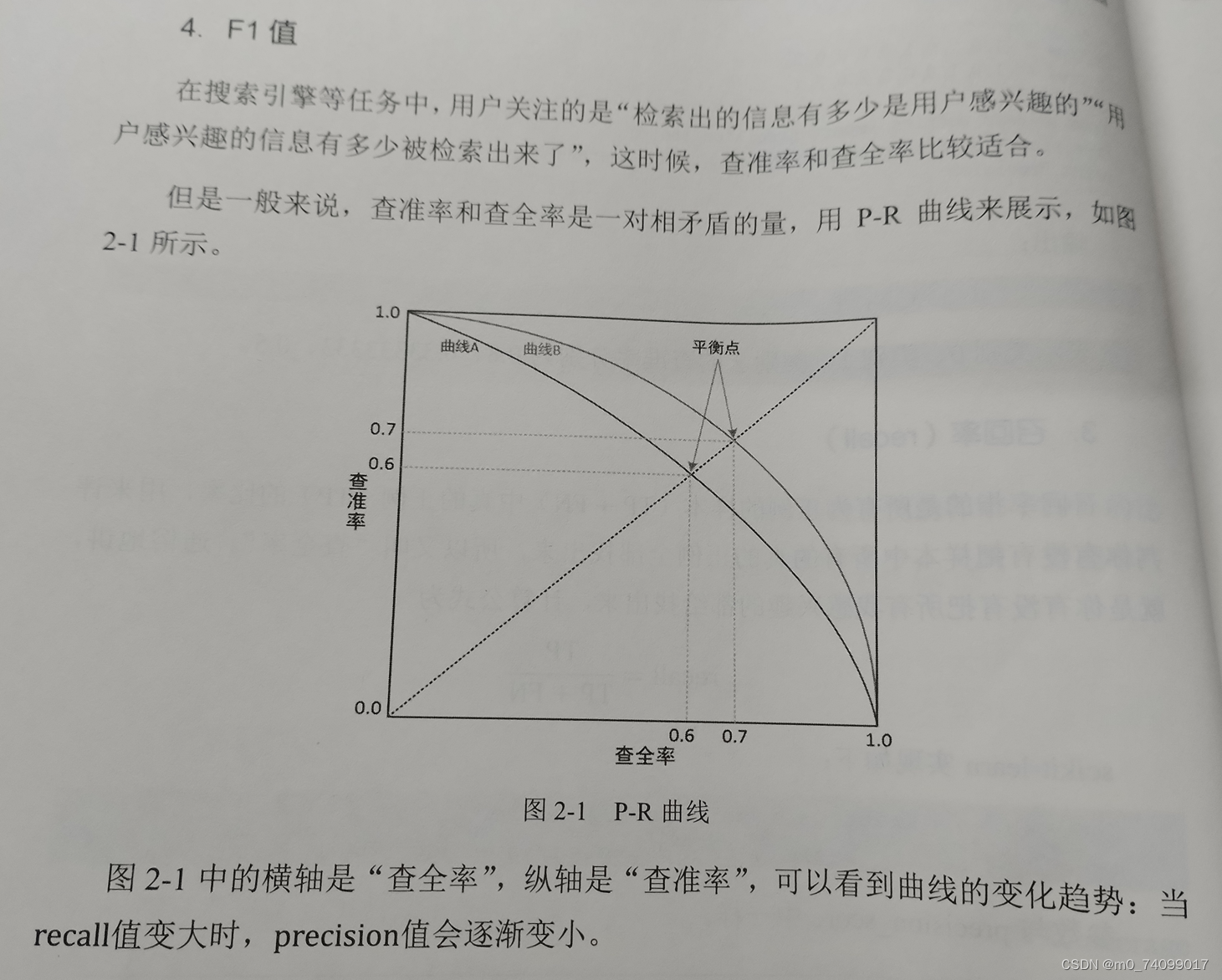
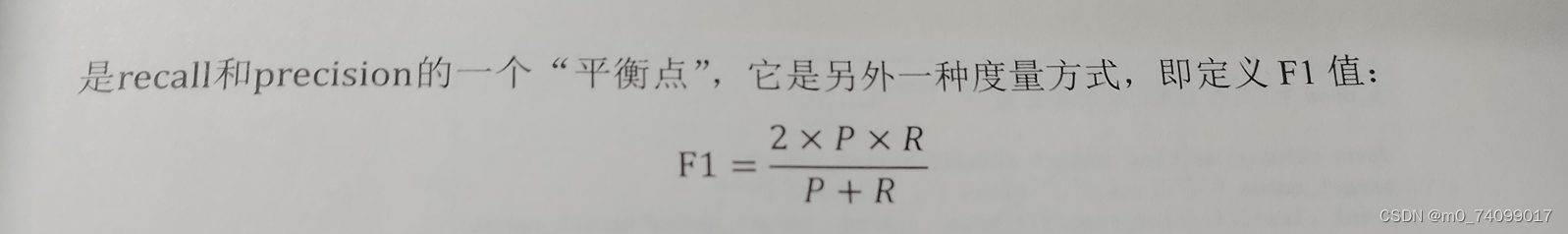
-
ROC曲线

6.AUC

7.混淆矩阵

2.1.3聚类模型的评估指标
1**. 外部指标**(External Index)
(1)Jaccard系数
(2)FM系数
(3)Rand系数
(4)标准化互信息
2.内部指标 (Internal Index)
(1)DB系数
(2)Dunn系数
3.轮廓系数
2.1.4常用的距离公式
- 曼哈顿距离
- 欧式距离
- 闵可夫斯基距离
- 夹角余弦
- 汉明距离
- 杰卡德森相似系数
- 杰卡德距离
2.2模型复杂度度量
2.2.1偏差与方差
一般来说,偏差和方差是有冲突的,偏差随着模型的复杂度增加而降低,而方差随着模型的复杂度增加而增加。方差和偏差加起来最优的点就是模型错误率最小的点,对应的位置就是最佳模型复杂度。
2.2.2过拟合与正则化
1.过拟合:指对已知数据预测的很好,但对未知数据预测的很差。
2.欠拟合:对未知数据预测范围扩大,比如树叶绿色只是其必要不充分条件,欠拟合误将绿色的都识别成树叶。
3.经验风险与结构风险
奥卡姆剃须刀:再能够较好的匹配已知数据得前提下,模型越简单越好
4.正则化
2.3特征工程与模型调优
2.3.1数据挖掘项目流程
- 业务理解
- 数据分析
- 特征工程
- 模型选择
- 模型评估
- 项目落地
2.3.2特征工程
1.数据清洗
直接删除缺失数据
固定值填充
均值/中位数填充
相邻值填充
模型填充
2.特征处理
归一化
标准化
离散化
one~hot编码
3.特征交互
4.特征映射
2.3.3模型选择与模型调优
1.模型选择
数据分析
交叉验证
2模型调优
网格搜索寻优
随机搜索寻优















 1518
1518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









