







一.基本信息
八个作者,名字后带✳,表示相同贡献。代码一般放在introduction最后一句话。
二.Abstract,Introduction,Background
提出一种新的模型:transformer;基于(attention)注意力的,而非recurrent(循环)或convolutional(卷积)的。
当输入输出结构化信息比较多的时候,会使用编码器-解码器的有关架构。
RNN是时序进行的,导致其无法并行,性能较差
多头注意力机制(multi-head attention):模拟卷积神经网络的多通道输出
自注意力机制:transformer只利用自注意力机制来做依赖于encoder,decoder架构的模型。
三.model Architecture
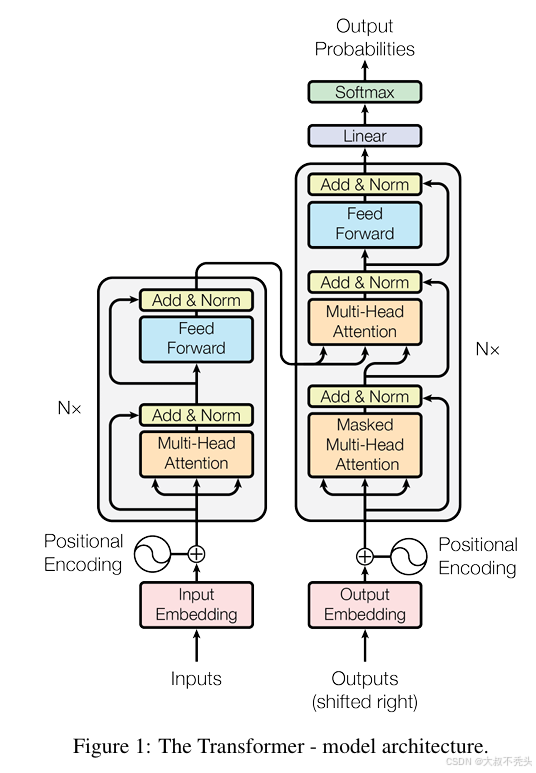
1.encoder-decoder
encoder:将原始输入变成机器可以理解的数据,可能是一批一批生成。
“encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers.”
6个相同的层堆叠(即图里的N=6),每层有俩个子层:一个多头注意力层,一个MLP(多层感知机),每个子层残差连接。输出维度是d=512
decoder:将隐藏层输出变成真正需要的输出,一个一个生成。多了一个masked-多头注意力机制,加了掩码,保证模型在预测下一个词时只能依赖于当前词及之前的词的信息,而不能看到未来的词。
在decoder里,masked-attention层输出作为下一层的query,K和V则从encoder获取。
2.Attention
在RNN里,序列一个一个传送。transformer里,利用attention进行全局处理。
attention:本文使用的是Scaled Dot—Product Attention,queries和keys都是d维,计算内积作为相似度,除以维度的根号,进行softmax,再乘V(values)。当不除根号维度时,内积出来的值比较极端,做完softmax之后更向俩边靠拢,训练时梯度比较小,跑不动。
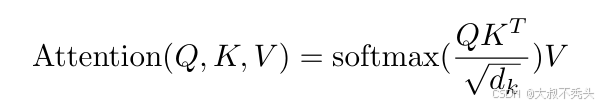
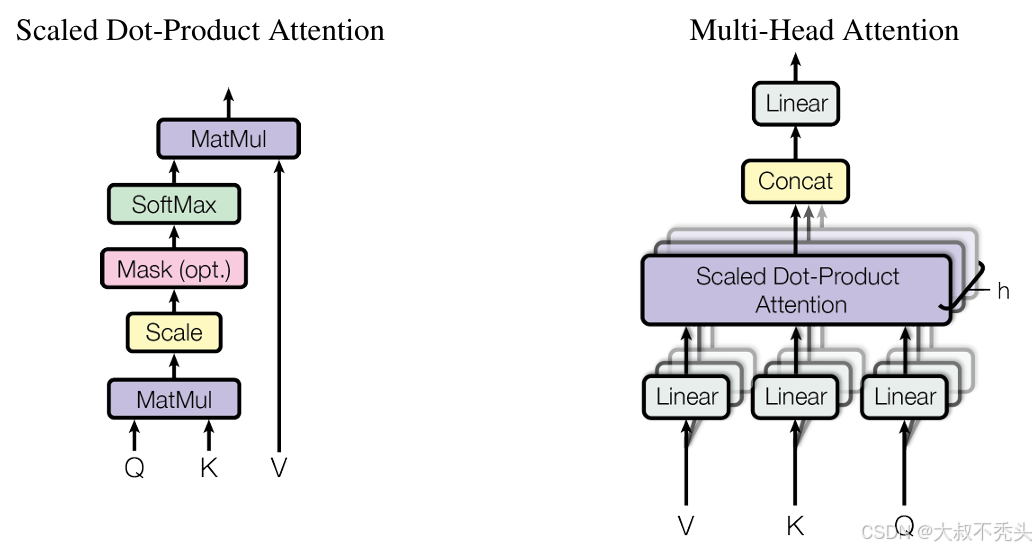
mask(opt.)作用是保证模型在预测下一个词时只能依赖于当前词及之前的词的信息,而不能看到未来的词。具体操作是将未来的数据变成一个极小的复数,使其在经过softmax之后无限趋近于0。
multi-head attention:做多次,之后合并作为输出

自注意力机制:输入同时做Q,K,V。
feed-forward network:

3.Embedding,softmax,Positional encoding.
embedding层:将输入token映射为一个向量(学习一个向量来表示输入),权重乘根号d使得和后面位置信息结合得更好,softmax。
positional :在输入里加入时序信息,因为attention是全局处理,不会关注时序信息。
用一个和输入维度一样的向量表示位置。时序信息和嵌入层相加。

















 3864
3864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









