







 本文介绍了目标检测在计算机视觉中的重要性,详细阐述了目标检测的流程,包括输入图像获取、候选区域生成、特征提取、分类和边界框回归、非极大值抑制以及输出结果。还讨论了目标检测的数据集、Ground Truth的重要性和获取方式,以及评估指标如准确率、召回率和F1分数。最后,文章探讨了深度学习在目标检测中的应用,包括anchor box、two-stage和one-stage算法的工作原理。
本文介绍了目标检测在计算机视觉中的重要性,详细阐述了目标检测的流程,包括输入图像获取、候选区域生成、特征提取、分类和边界框回归、非极大值抑制以及输出结果。还讨论了目标检测的数据集、Ground Truth的重要性和获取方式,以及评估指标如准确率、召回率和F1分数。最后,文章探讨了深度学习在目标检测中的应用,包括anchor box、two-stage和one-stage算法的工作原理。
一.目标检测
目标检测是计算机视觉领域中的一个重要任务,它旨在识别和定位图像或视频中的特定目标物体。与图像分类任务不同,目标检测不仅要求识别出目标的类别,还需要确定目标在图像中的位置,通常通过边界框(bounding box)的方式进行表示。
目标检测的一般流程如下:
1. 输入图像获取:从图像或视频中获取原始图像作为输入。
2. 候选区域生成:使用候选区域生成算法(如选择性搜索、区域提议网络等)生成一组可能包含目标的候选区域。
3. 特征提取:对每个候选区域应用特征提取算法(如卷积神经网络)以获得固定长度的特征向量。
4. 目标分类和边界框回归:使用分类器来判断每个候选区域内是否包含目标,并通过回归算法精确定位目标的边界框。
5. 非极大值抑制:如果存在多个重叠的候选框,则使用非极大值抑制算法来选择具有最高置信度的目标框。
6. 输出结果:输出识别出的目标类别和其位置。
二.目标检测数据集
1. COCO :
COCO 数据集是一个广泛使用的大规模目标检测数据集,包含超过33万张图像和超过200万个标记的物体实例。该数据集涵盖了80个不同的类别,包括人、动物、交通工具、家具等。
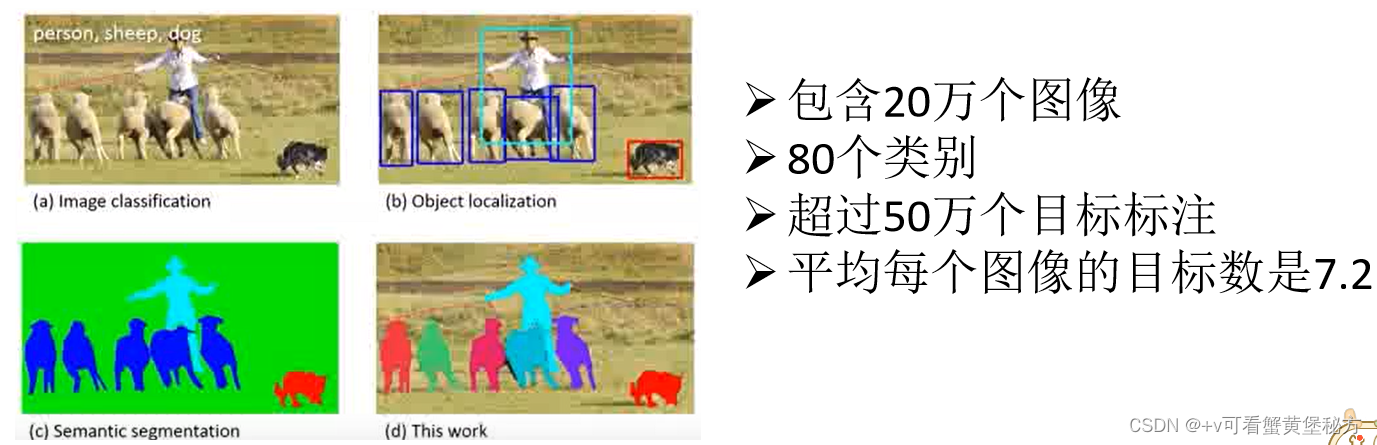
2. PASCAL VOC :
PASCAL VOC 数据集是另一个常用的目标检测数据集,包含了20个类别的物体,如人、狗、猫、飞机等。它包含了大约17,000张图像&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7937
7937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









