






一、背景知识
在计算机视觉领域,目标检测一直是一个备受关注的研究方向。随着深度学习技术的不断发展,许多先进的目标检测算法被提出,其中最具代表性和影响力的之一就是YOLO(You Only Look Once)。YOLO以其高效的性能和实时处理能力而闻名,成为了许多计算机视觉项目的首选之一。本文将介绍YOLO目标检测算法的原理、应用以及其在实际项目中的应用场景。
1. YOLO简介
YOLO是一种基于深度学习的目标检测算法,由Joseph Redmon等人于2016年提出。与传统的目标检测算法相比,YOLO在一张图像中只需运行一次网络,就可以直接预测出图像中所有目标的位置和类别,因此被称为“You Only Look Once”。这种实时性的优势使得YOLO在许多实际应用中备受青睐。

2. YOLO原理
YOLO的核心原理是将目标检测任务转化为一个回归问题,通过单个卷积神经网络同时预测图像中多个目标的边界框和类别概率。具体来说,YOLO网络将输入图像分成S×S个网格单元,每个网格单元负责检测图像中的目标。对于每个网格单元,网络会输出B个边界框以及每个边界框对应的类别概率。通过在网络的输出层使用适当的损失函数,可以训练网络使其准确地预测目标的位置和类别。
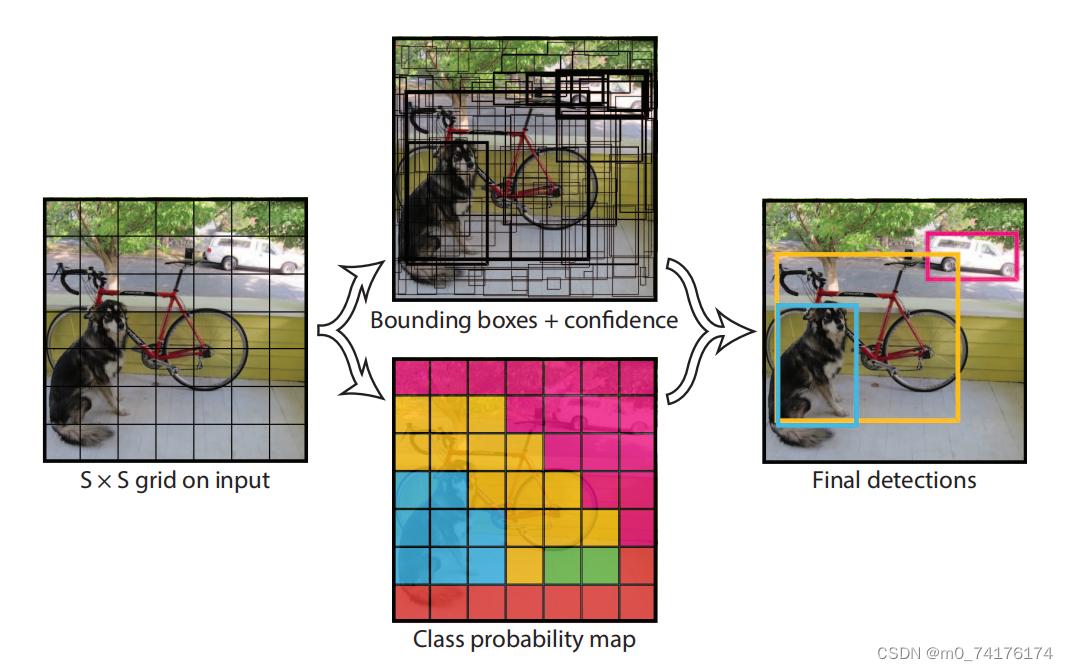
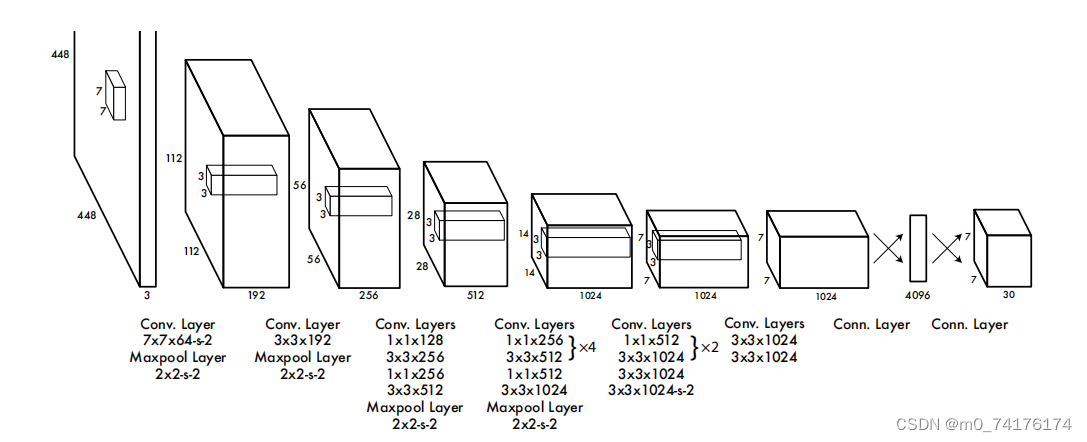
3. YOLO的应用
YOLO在许多领域都有着广泛的应用,包括但不限于物体检测、行人检测、交通监控、无人驾驶、工业质检等。其快速、准确的检测能力使得它成为了许多实时应用的首选算法。
4. YOLO的改进和发展
自YOLO问世以来,研究者们对其进行了许多改进和优化,提出了许多变体和改进版本,如YOLOv2、YOLOv3、YOLOv4等,以进一步提高其检测性能和效率。这些改进使得YOLO算法在不断发展的计算机视觉领域中保持着领先地位。
YOLO目标检测算法以其快速、准确的特性成为了计算机视觉领域的一颗明星。通过将目标检测任务转化为回归问题,YOLO在实时性和准确性上取得了良好的平衡,为许多实际应用提供了强大的支持。随着深度学习技术的不断进步,相信YOLO算法还将在未来的研究和应用中发挥更加重要的作用。
二、实验内容
1. 实验准备
- 准备好Python和Pytorch。
- 下载并准备适当规模的数据集,如VOC。
- 安装CUDA、cuDNN等GPU加速库。
- 安装Darknet框架,并配置相关依赖项。
- 下载YOLOv4的预训练权重,作为实验的初始模型。
2. 训练步骤
a. 训练VOC07+12数据集
训练前需要下载好VOC07+12的数据集,解压后放在根目录;修改voc_annotation.py里面的annotation_mode=2,运行voc_annotation.py生成根目录下的2007_train.txt和2007_val.txt;train.py的默认参数用于训练VOC数据集,直接运行train.py即可开始训练;训练结果预测需要用到两个文件,分别是yolo.py和predict.py。首先需要去yolo.py里面修改model_path以及classes_path,这两个参数必须要修改(model_path指向训练好的权值文件,在logs文件夹里,classes_path指向检测类别所对应的txt)。完成修改后运行predict.py进行检测,运行后输入图片路径即可检测。
b. 训练自己的数据集
标注图像:创建标签
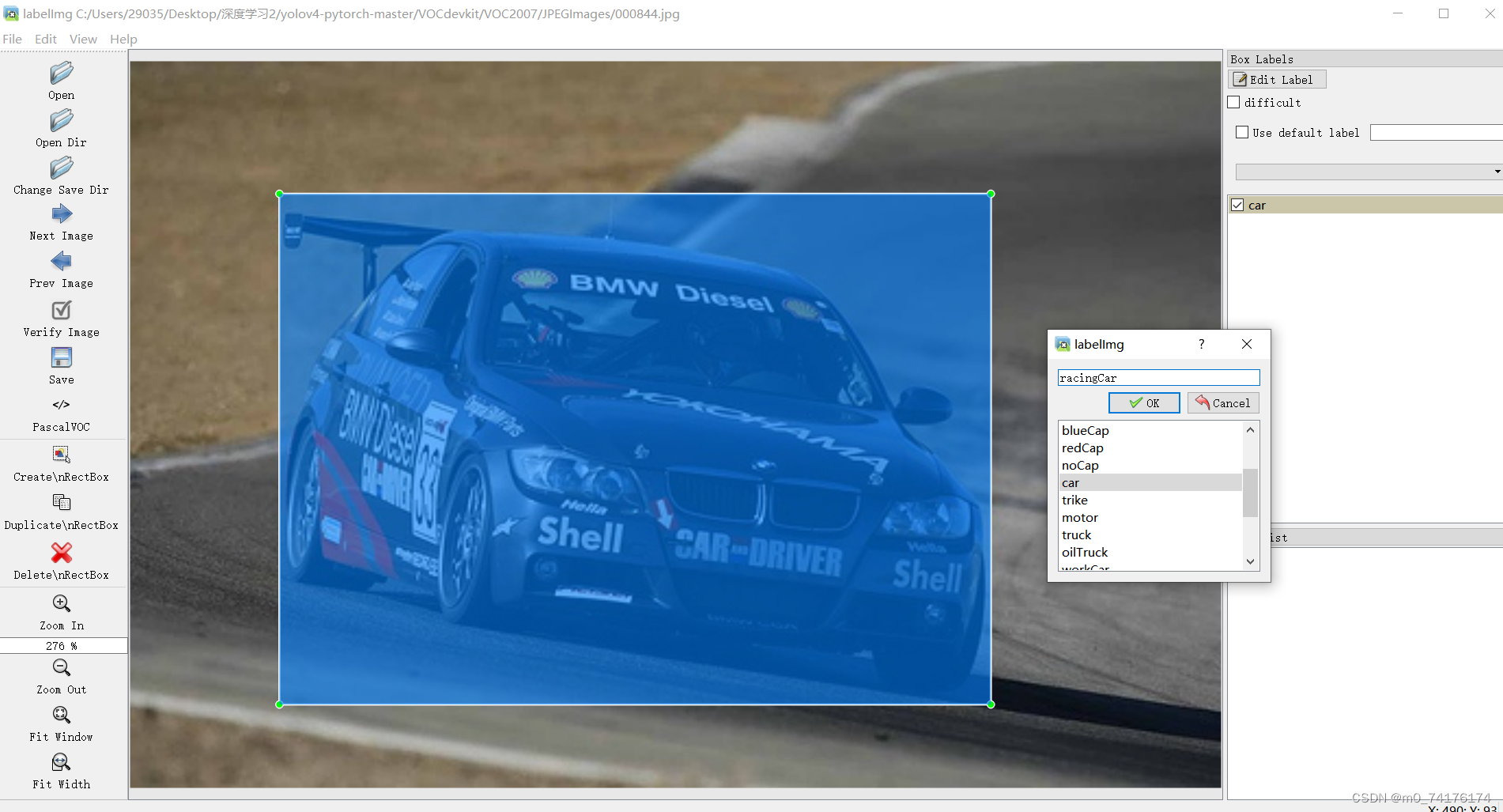
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中,将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中;在完成数据集的摆放之后,需要利用voc_annotation.py获得训练用的2007_train.txt和2007_val.txt;修改voc_annotation.py里面的参数,第一次训练可以仅修改classes_path,classes_path用于指向检测类别所对应的txt;训练自己的数据集时,可以建立一个cls_classes.txt,里面写出所需要区分的类别。
person
car
bicycle
dog
cat
chair
table
bird
book
cup
laptop
cell phone
keyboard
mouse
...修改voc_annotation.py中的classes_path,使其对应cls_classes.txt,并运行voc_annotation.py。
训练自己的数据集必须要修改,修改完classes_path后就可以运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。训练结果预测需要用到两个文件,分别是yolo.py和predict.py,在yolo.py里面修改model_path以及classes_path(model_path指向训练好的权值文件,在logs文件夹里,classes_path指向检测类别所对应的txt)。完成修改后运行predict.py进行检测,运行后输入图片路径即可检测。
3. 结果预测
a. 使用预训练权重
将yolo_weights.pth放入model_data,运行predict.py,输入
img/street.jpgb. 使用自己训练权重
在yolo.py文件里面,在如下部分修改model_path和classes_path使其对应训练好的文件
_defaults = {
#--------------------------------------------------------------------------#
# 使用自己训练好的模型进行预测一定要修改model_path和classes_path!
# model_path指向logs文件夹下的权值文件,classes_path指向model_data下的txt
# 如果出现shape不匹配,同时要注意训练时的model_path和classes_path参数的修改
#--------------------------------------------------------------------------#
"model_path" : 'model_data/yolo_weights.pth',
"classes_path" : 'model_data/coco_classes.txt',
#---------------------------------------------------------------------#
# anchors_path代表先验框对应的txt文件,一般不修改。
# anchors_mask用于帮助代码找到对应的先验框,一般不修改。
#---------------------------------------------------------------------#
"anchors_path" : 'model_data/yolo_anchors.txt',
"anchors_mask" : [[6, 7, 8], [3, 4, 5], [0, 1, 2]],
#---------------------------------------------------------------------#
# 输入图片的大小,必须为32的倍数。
#---------------------------------------------------------------------#
"input_shape" : [416, 416],
#---------------------------------------------------------------------#
# 只有得分大于置信度的预测框会被保留下来
#---------------------------------------------------------------------#
"confidence" : 0.5,
#---------------------------------------------------------------------#
# 非极大抑制所用到的nms_iou大小
#---------------------------------------------------------------------#
"nms_iou" : 0.3,
#---------------------------------------------------------------------#
# 该变量用于控制是否使用letterbox_image对输入图像进行不失真的resize,
# 在多次测试后,发现关闭letterbox_image直接resize的效果更好
#---------------------------------------------------------------------#
"letterbox_image" : False,
#-------------------------------#
# 是否使用Cuda
# 没有GPU可以设置成False
#-------------------------------#
"cuda" : True,
}运行predict.py,输入
img/street.jpg
4. 输入图片

得出YOLO目标检测结果。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









