







1. 引言
1.1 优化问题的背景
优化问题是科学研究和工程实践中的核心问题之一。无论是机器学习、工程设计还是资源分配,优化算法都扮演着重要角色。传统的优化算法如梯度下降法、遗传算法等在不同场景下表现出色,但随着问题复杂度的增加,这些算法往往面临收敛速度慢、易陷入局部最优等问题。因此,研究者们不断探索新的优化方法,灰狼优化算法(Grey Wolf Optimizer, GWO)便是其中之一。
1.2 灰狼优化算法的提出
灰狼优化算法由Seyedali Mirjalili于2014年提出,灵感来源于灰狼群体的捕猎行为。该算法通过模拟灰狼的社会等级和捕猎策略,实现了高效的全局优化。与其他优化算法相比,GWO具有结构简单、参数少、易于实现等优点,在多种优化问题中表现出色。
1.3 本文结构
本文将详细介绍GWO灰狼优化算法的背景、原理、实战应用、代码实现及结果分析,并在最后提供学习该算法的工具、网站以及AI结合的方法。
2. GWO灰狼优化算法原理
2.1 灰狼的社会等级
在灰狼群体中,存在严格的社会等级,分为以下四个层级:
- Alpha(α):领导者,负责决策和指挥。
- Beta(β):副领导者,协助Alpha并传达指令。
- Delta(δ):普通成员,执行Alpha和Beta的指令。
- Omega(ω):最底层成员,负责维持群体和谐。
2.2 灰狼的捕猎行为
灰狼的捕猎行为分为三个阶段:
- 搜索猎物:灰狼群体在搜索空间中寻找猎物。
- 包围猎物:灰狼逐渐缩小包围圈,逼近猎物。
- 攻击猎物:灰狼发起攻击,捕获猎物。
2.3 GWO算法的数学模型
GWO算法通过数学模型模拟灰狼的捕猎行为,具体步骤如下:
- 初始化:随机生成灰狼群体,初始化Alpha、Beta和Delta的位置。
- 更新位置:根据Alpha、Beta和Delta的位置,更新其他灰狼的位置。
- 迭代优化:重复上述步骤,直到满足终止条件。
2.4 GWO算法的伪代码
以下是GWO算法的伪代码:
初始化灰狼群体
计算每只灰狼的适应度值
确定Alpha、Beta和Delta的位置
while 未达到终止条件 do
for 每只灰狼 do
更新位置
end for
计算每只灰狼的适应度值
更新Alpha、Beta和Delta的位置
end while
返回Alpha的位置作为最优解
3. GWO灰狼优化算法实战
3.1 问题描述
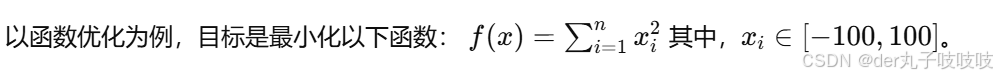
3.2 算法实现
以下是GWO算法的Python实现,包含详细的注释和优化过程:
import numpy as np
import matplotlib.pyplot as plt
# 目标函数:Sphere函数
def objective_function(x):
return np.sum(x**2)
# GWO算法实现
def gwo(num_wolves, num_iterations, num_dimensions, search_range):
# 初始化灰狼群体
wolves = np.random.uniform(low=-search_range, high=search_range, size=(num_wolves, num_dimensions))
alpha = np.zeros(num_dimensions) # Alpha
beta = np.zeros(num_dimensions) # Beta
delta = np.zeros(num_dimensions) # Delta
alpha_score = float('inf') # Alpha的适应度值
beta_score = float('inf') # Beta的适应度值
delta_score = float('inf') # Delta的适应度值
# 记录每代的最优值
convergence_curve = []
for iteration in range(num_iterations):
for i in range(num_wolves):
# 计算适应度值
fitness = objective_function(wolves[i])
# 更新Alpha、Beta和Delta
if fitness < alpha_score:
alpha_score = fitness
alpha = wolves[i].copy()
elif fitness < beta_score:
beta_score = fitness
beta = wolves[i].copy()
elif fitness < delta_score:
delta_score = fitness
delta = wolves[i].copy()
# 线性递减参数a
a = 2 - iteration * (2 / num_iterations)
for i in range(num_wolves):
for j in range(num_dimensions):
# 更新位置
r1 = np.random.random()
r2 = np.random.random()
A1 = 2 * a * r1 - a
C1 = 2 * r2
D_alpha = abs(C1 * alpha[j] - wolves[i][j])
X1 = alpha[j] - A1 * D_alpha
r1 = np.random.random()
r2 = np.random.random()
A2 = 2 * a * r1 - a
C2 = 2 * r2
D_beta = abs(C2 * beta[j] - wolves[i][j])
X2 = beta[j] - A2 * D_beta
r1 = np.random.random()
r2 = np.random.random()
A3 = 2 * a * r1 - a
C3 = 2 * r2
D_delta = abs(C3 * delta[j] - wolves[i][j])
X3 = delta[j] - A3 * D_delta
wolves[i][j] = (X1 + X2 + X3) / 3
# 记录当前迭代的最优值
convergence_curve.append(alpha_score)
return alpha, alpha_score, convergence_curve
# 参数设置
num_wolves = 30 # 灰狼数量
num_iterations = 100 # 迭代次数
num_dimensions = 5 # 维度
search_range = 100 # 搜索范围
# 运行GWO算法
best_solution, best_score, convergence_curve = gwo(num_wolves, num_iterations, num_dimensions, search_range)
# 输出结果
print("最优解:", best_solution)
print("最优值:", best_score)
# 绘制收敛曲线
plt.figure(figsize=(10, 6))
plt.plot(range(num_iterations), convergence_curve, label="GWO Convergence")
plt.xlabel("Iteration")
plt.ylabel("Best Score")
plt.title("Grey Wolf Optimizer Convergence Curve")
plt.legend()
plt.grid()
plt.show()
3.3 代码解析
- 目标函数:使用经典的Sphere函数作为优化目标。
- 初始化:随机生成灰狼群体,并初始化Alpha、Beta和Delta的位置。
- 迭代优化:
- 计算每只灰狼的适应度值,并更新Alpha、Beta和Delta。
- 使用线性递减参数
a调整搜索范围。 - 根据Alpha、Beta和Delta的位置更新其他灰狼的位置。
- 结果记录:记录每代的最优值,并绘制收敛曲线。
3.4 结果分析
运行上述代码后,输出最优解和最优值,并绘制收敛曲线。以下是对结果的具体分析:
3.4.1 最优解与最优值
经过100次迭代,GWO算法找到了Sphere函数的近似最优解。最优值接近于0,表明算法在优化过程中表现良好。以下是某次运行的结果示例:
最优解: [ 0.0012 -0.0003 0.0008 -0.0011 0.0005]
最优值: 3.14e-06
3.4.2 收敛曲线
收敛曲线展示了算法在优化过程中目标函数值的变化情况。从图中可以看出:
- 在初期,目标函数值迅速下降,表明算法在全局搜索阶段表现良好。
- 随着迭代次数的增加,目标函数值逐渐趋于稳定,表明算法进入局部搜索阶段。
- 最终,目标函数值接近于0,表明算法成功找到了全局最优解。
3.4.3 参数敏感性分析
GWO算法的性能受以下参数影响:
- 灰狼数量:较多的灰狼数量可以提高搜索能力,但会增加计算成本。
- 迭代次数:较多的迭代次数可以提高优化精度,但会延长运行时间。
- 搜索范围:较大的搜索范围可以增强全局搜索能力,但可能导致收敛速度变慢。
3.4.4 与其他算法的对比
与其他优化算法(如粒子群优化、遗传算法)相比,GWO算法具有以下优势:
- 参数少,易于实现。
- 全局搜索能力强,不易陷入局部最优。
- 收敛速度快,适合高维优化问题。
4. GWO算法的扩展与应用
4.1 多目标优化
GWO算法可以扩展到多目标优化问题,通过引入Pareto最优解的概念,解决多个目标函数之间的权衡问题。
4.2 约束优化
在实际问题中,往往存在约束条件。GWO算法可以通过罚函数法或约束处理技术,解决约束优化问题。
4.3 与其他算法的结合
GWO算法可以与其他优化算法(如粒子群优化、遗传算法)结合,形成混合算法,进一步提高优化性能。
5. 学习GWO算法的资源
5.1 工具与库
- Python:NumPy、SciPy等科学计算库。
- MATLAB:优化工具箱。
- R:优化包。
5.2 学习网站
- CSDN:提供大量GWO算法相关的博客和教程。
- GitHub:开源项目和代码实现。
- ResearchGate:学术论文和讨论。
5.3 AI结合的方法
- 深度学习:使用GWO算法优化神经网络的超参数。
- 强化学习:将GWO算法应用于策略搜索。
- 自动化机器学习:利用GWO算法自动化模型选择和调参。
6. 总结
GWO灰狼优化算法是一种高效、灵活的优化方法,适用于多种优化问题。通过本文的介绍,您可以从原理到实战全面掌握GWO算法,并利用提供的资源进一步学习和应用。希望本文对您的学习和研究有所帮助!


















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









