







目录
宇宙免责声明
参考b站视频:你的声音,现在是我的了!- 手把手教你用 GPT-SoVITS 克隆声音!_哔哩哔哩_bilibili
做的笔记整理,只做个人记录分享给大家
安装包下载
GPT-SoVITS是github上的一个开源项目,所以需要科学上网。
进入该网址后,下滑,点击:
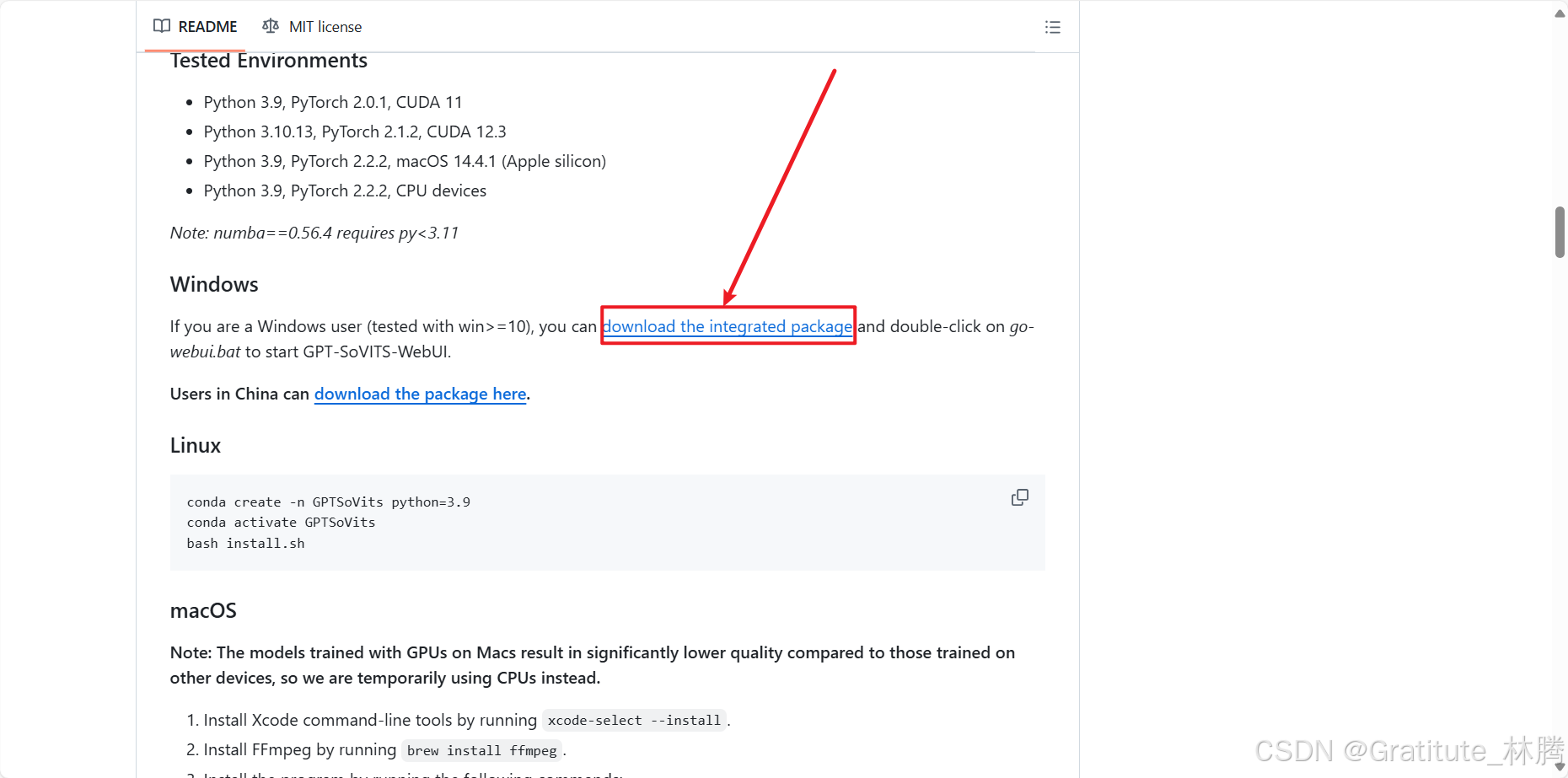
然后就会开始下载。。。
下载完成后,对它进行解压
解压完成后,双击文件夹:
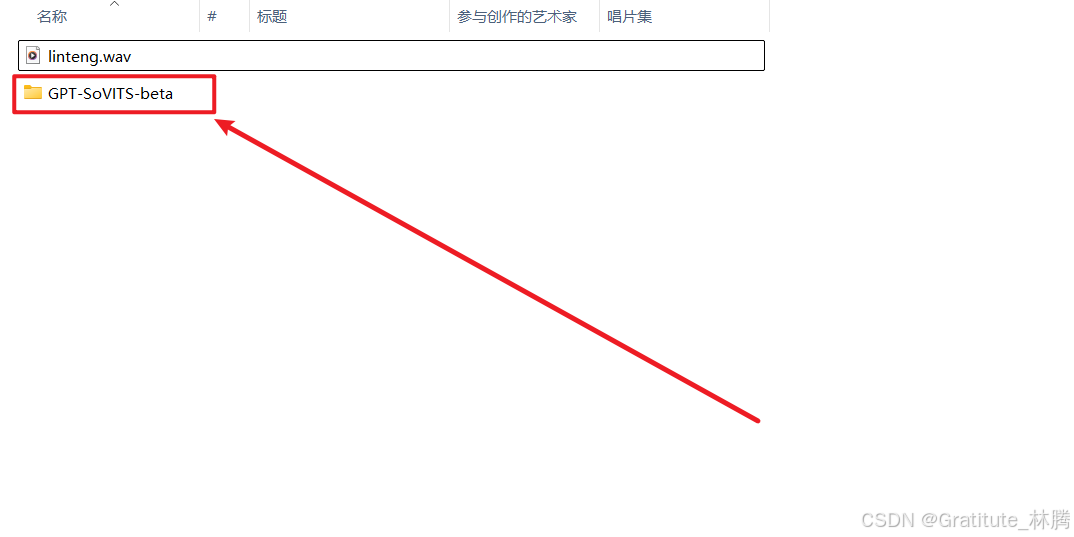
再双击:
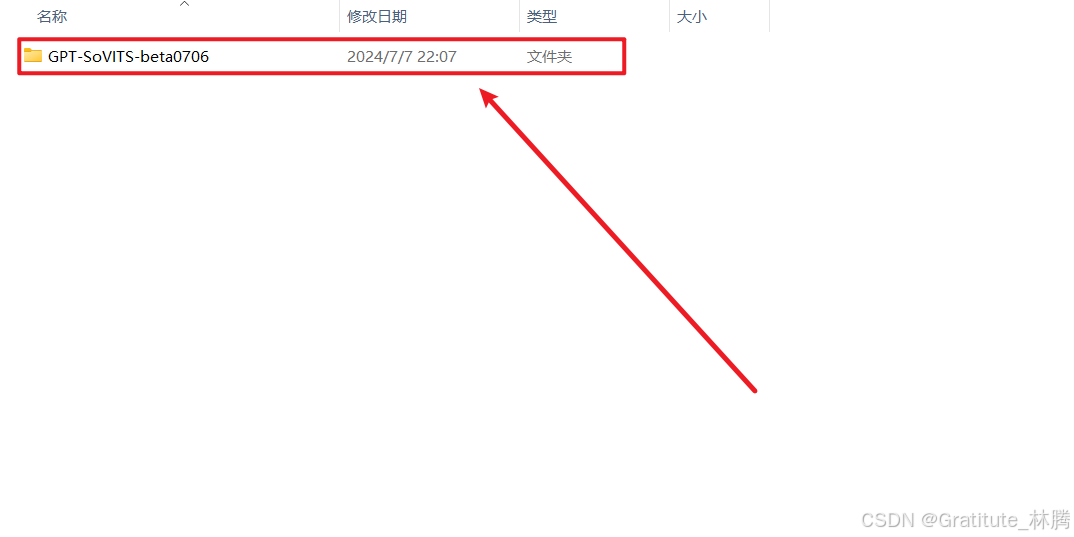
再双击:
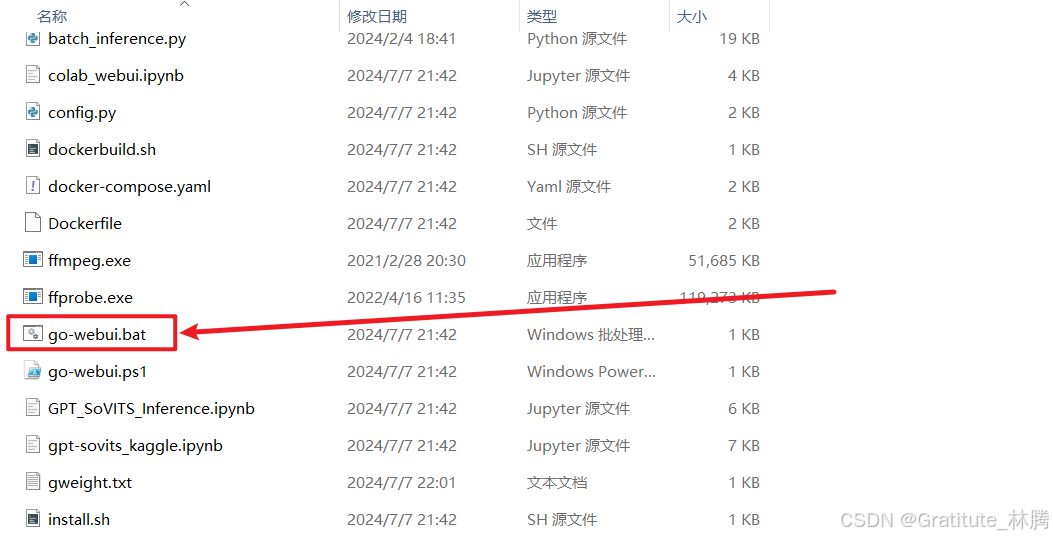
然后就会弹出:
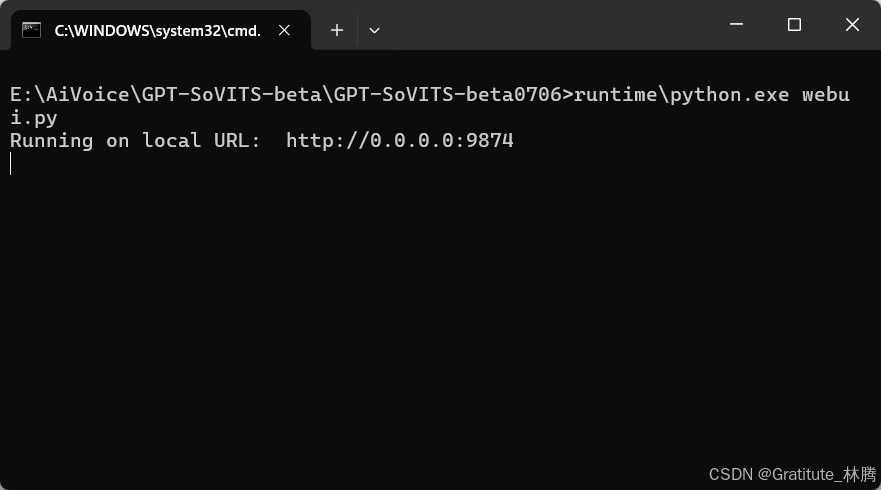
耐心等待一会儿,就会自动跳转到页面:
准备音频
准备一段1到2分钟的音频素材,长一点会更好。如果想克隆自己的声音,直接用手机录制即可,录制好后,发给电脑。音频格式设置为wav,可以获得更好的效果
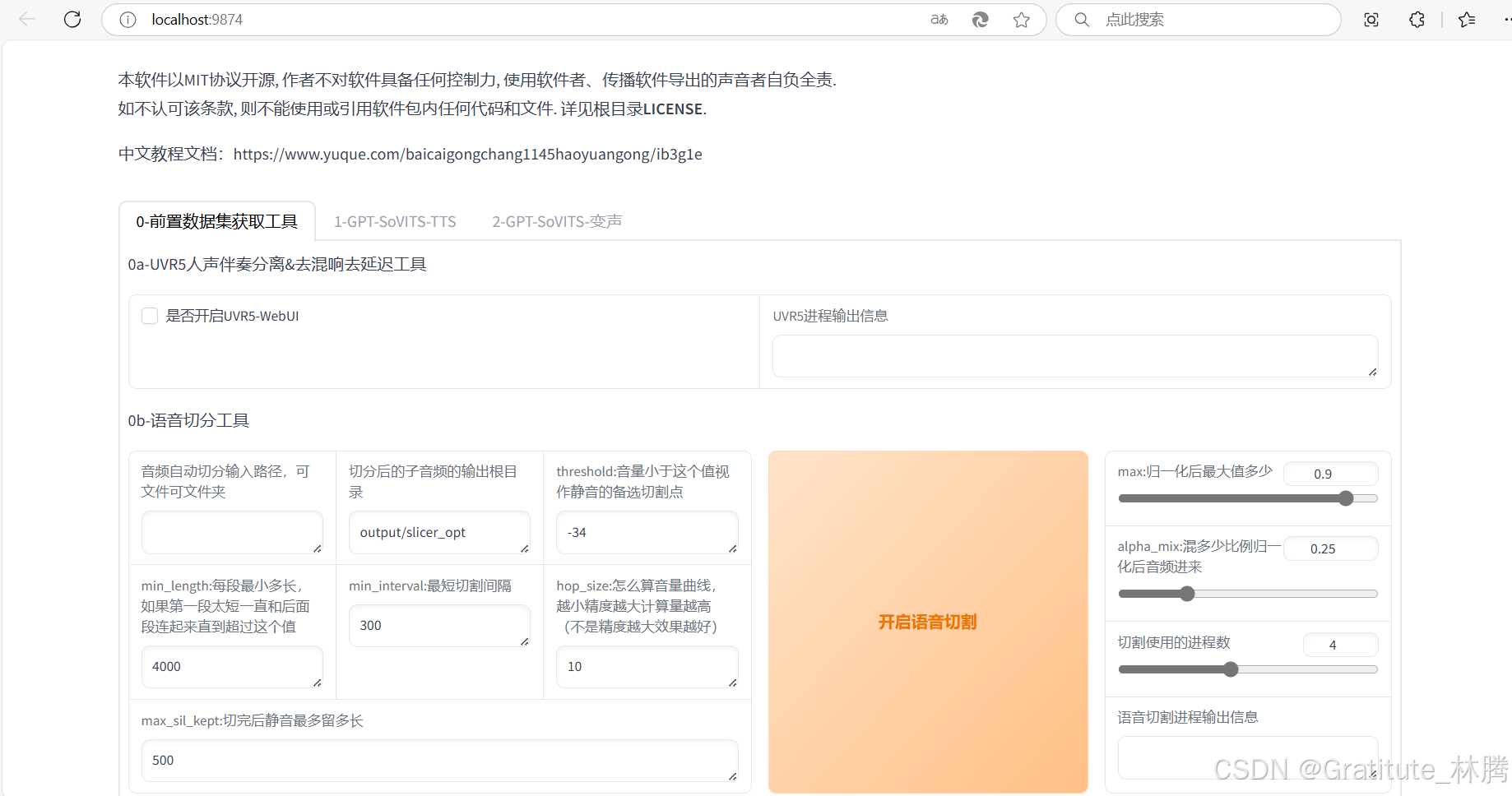
如果有背景音乐等噪音,可以点击UVR5-WebUI处理一下
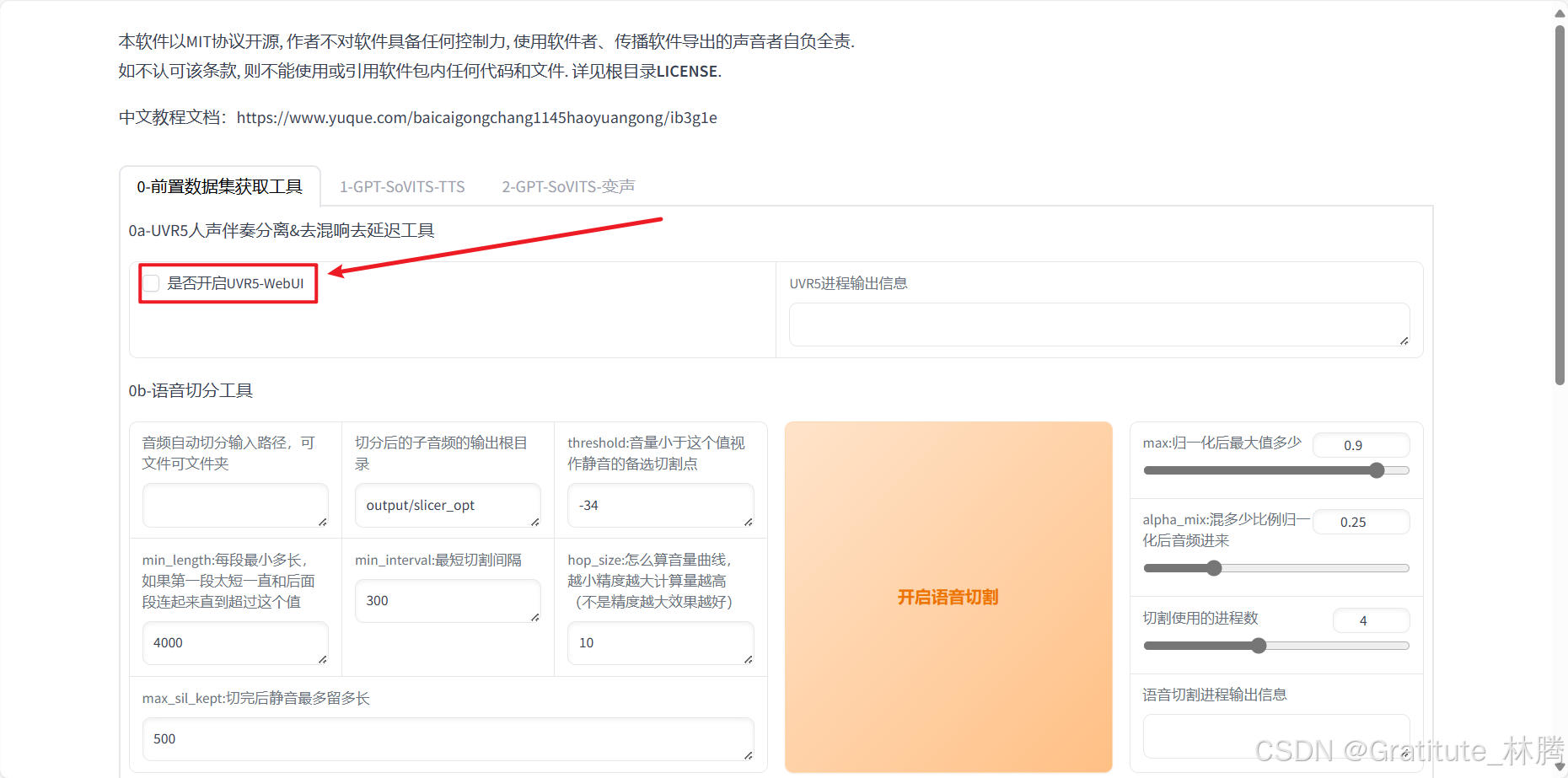
勾选之后,再耐心等待一下,会自动打开一个新的页面(等待时间可能会有点长):
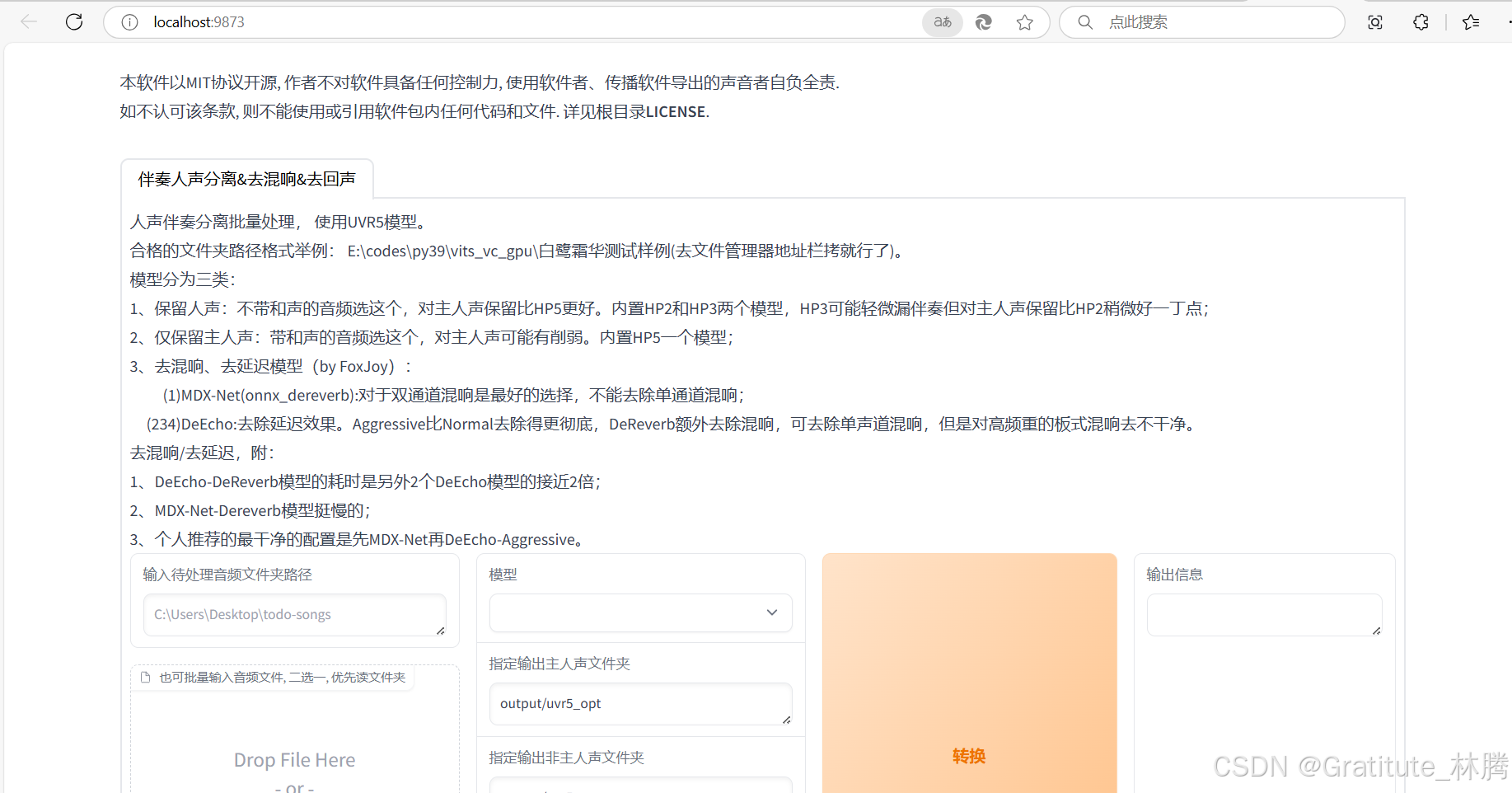
把需要处理的音频素材拖进来:
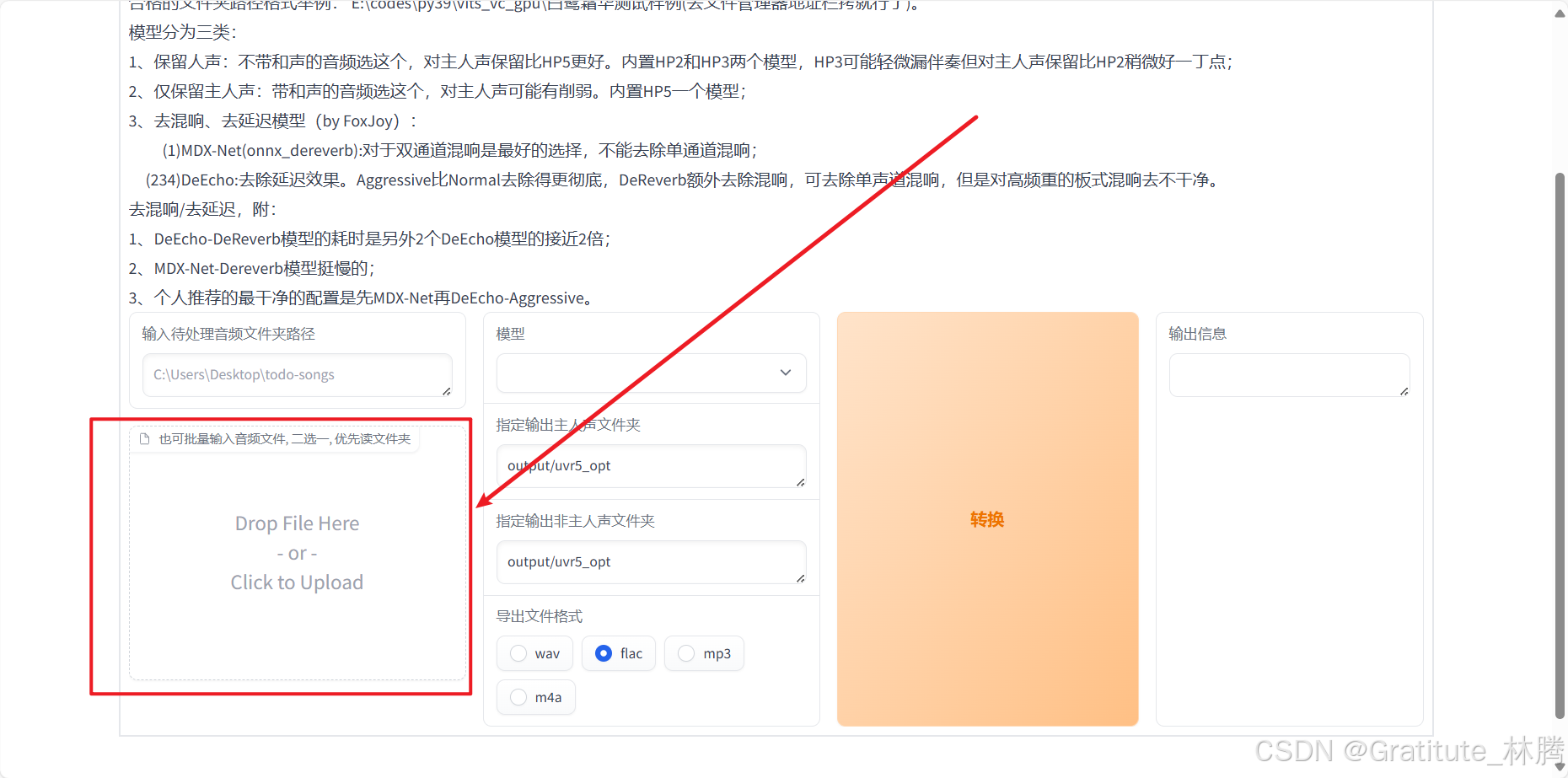
再按照文字提示,选择对应的模型:
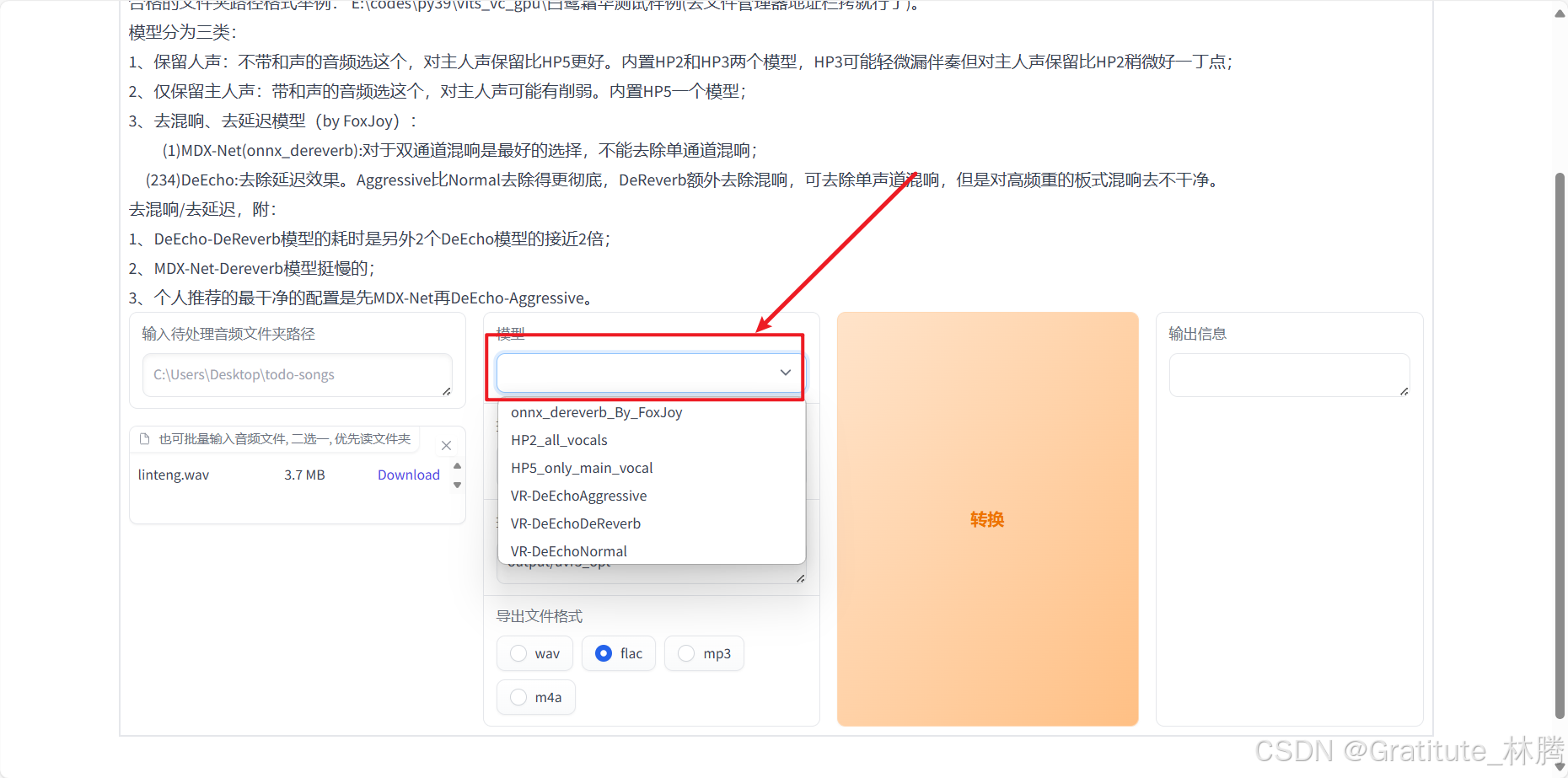
注:一个模型只能去除一种噪声,所以有时需要多次处理
选择好模型后,点击转换即可:
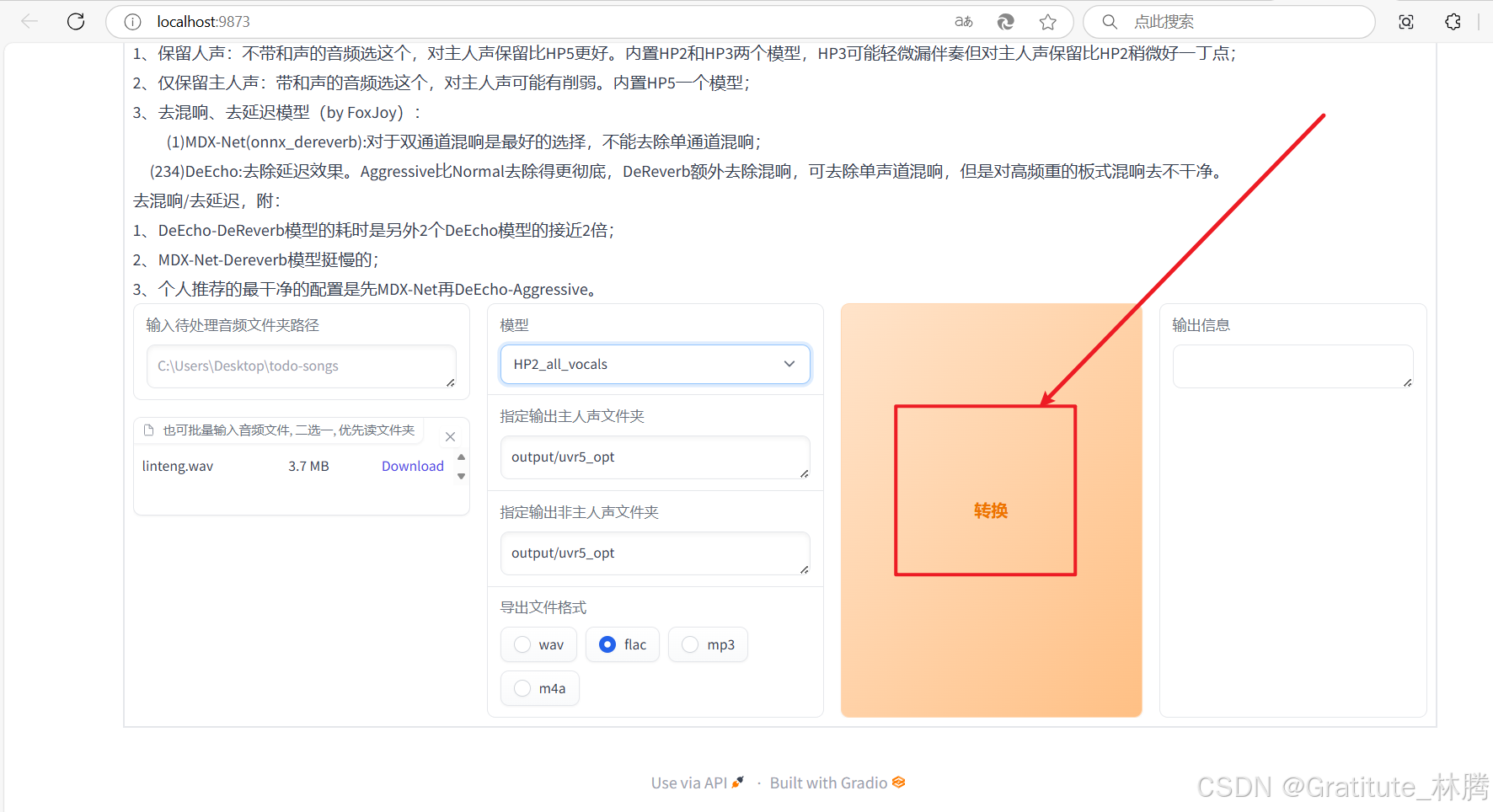
转换后的文件默认会保存在output/uvr5_opt目录下,这里可能会存在一些非人声音频,所以建议把每一条都听一遍,然后把不需要的删除。
当然,也可以手动修改路径:
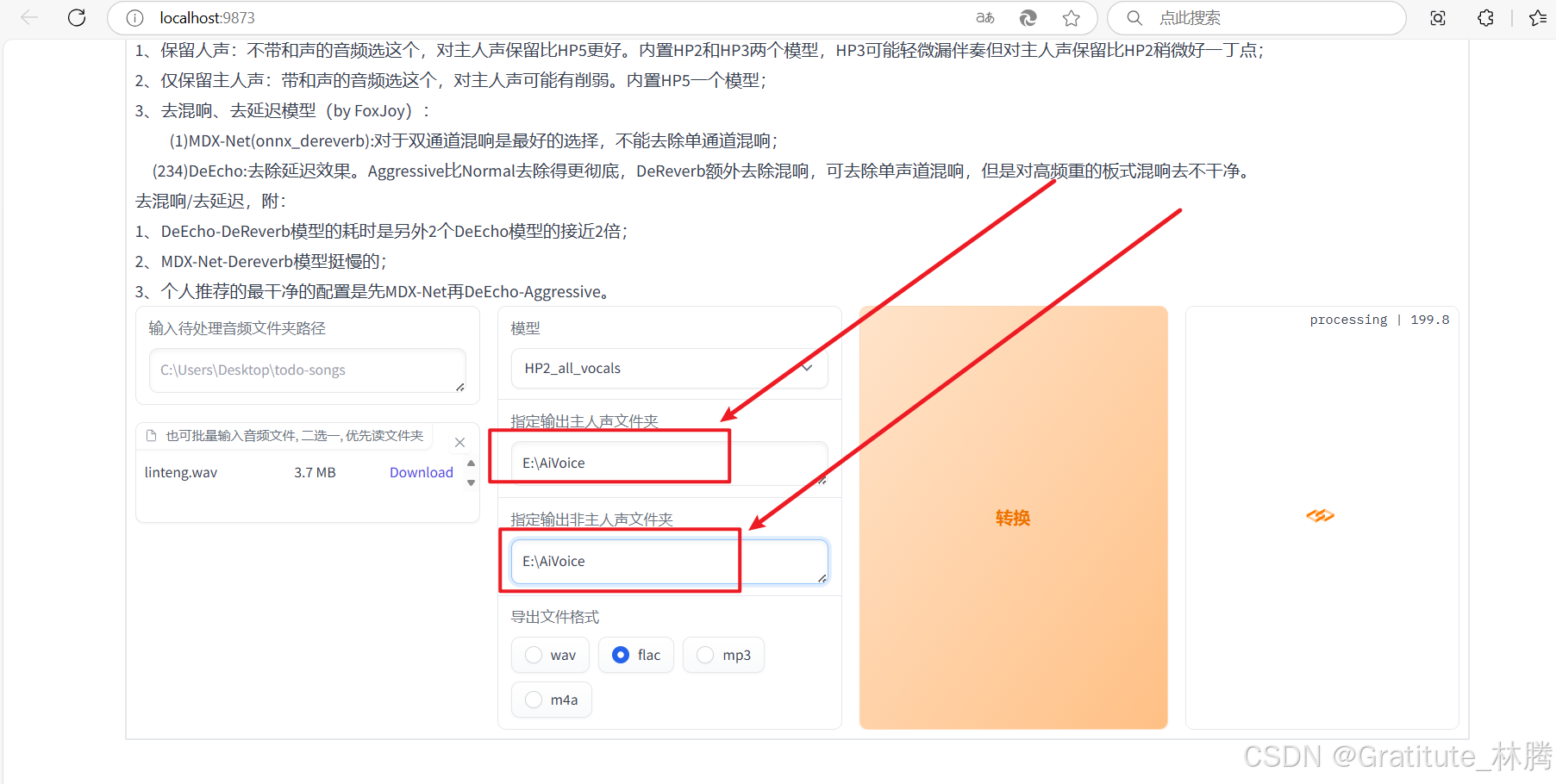
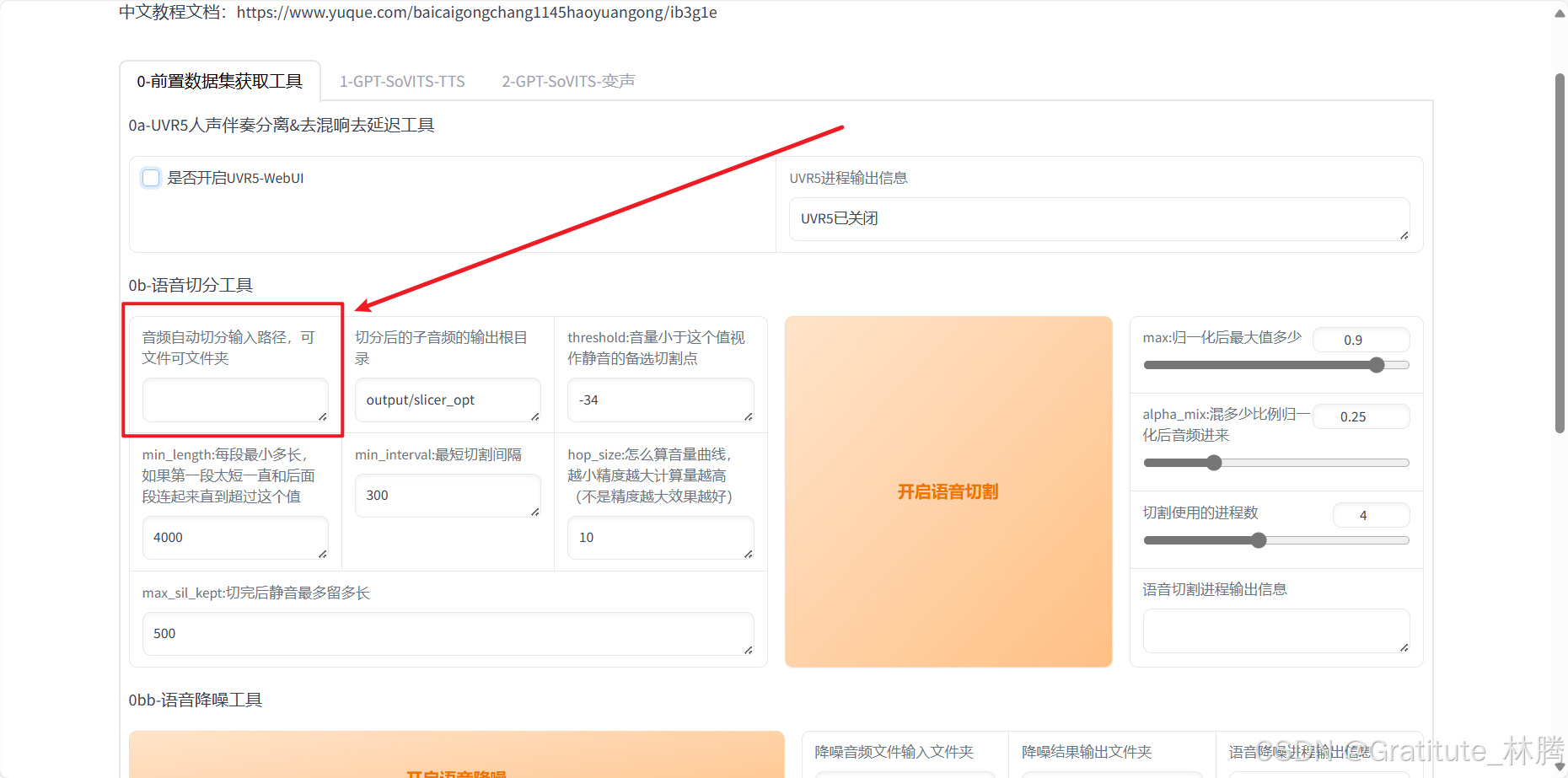
音频处理完后,关闭当前标签页,回到GPT-SoVITS页面,并取消勾选UVR5-WebUI:
切割音频
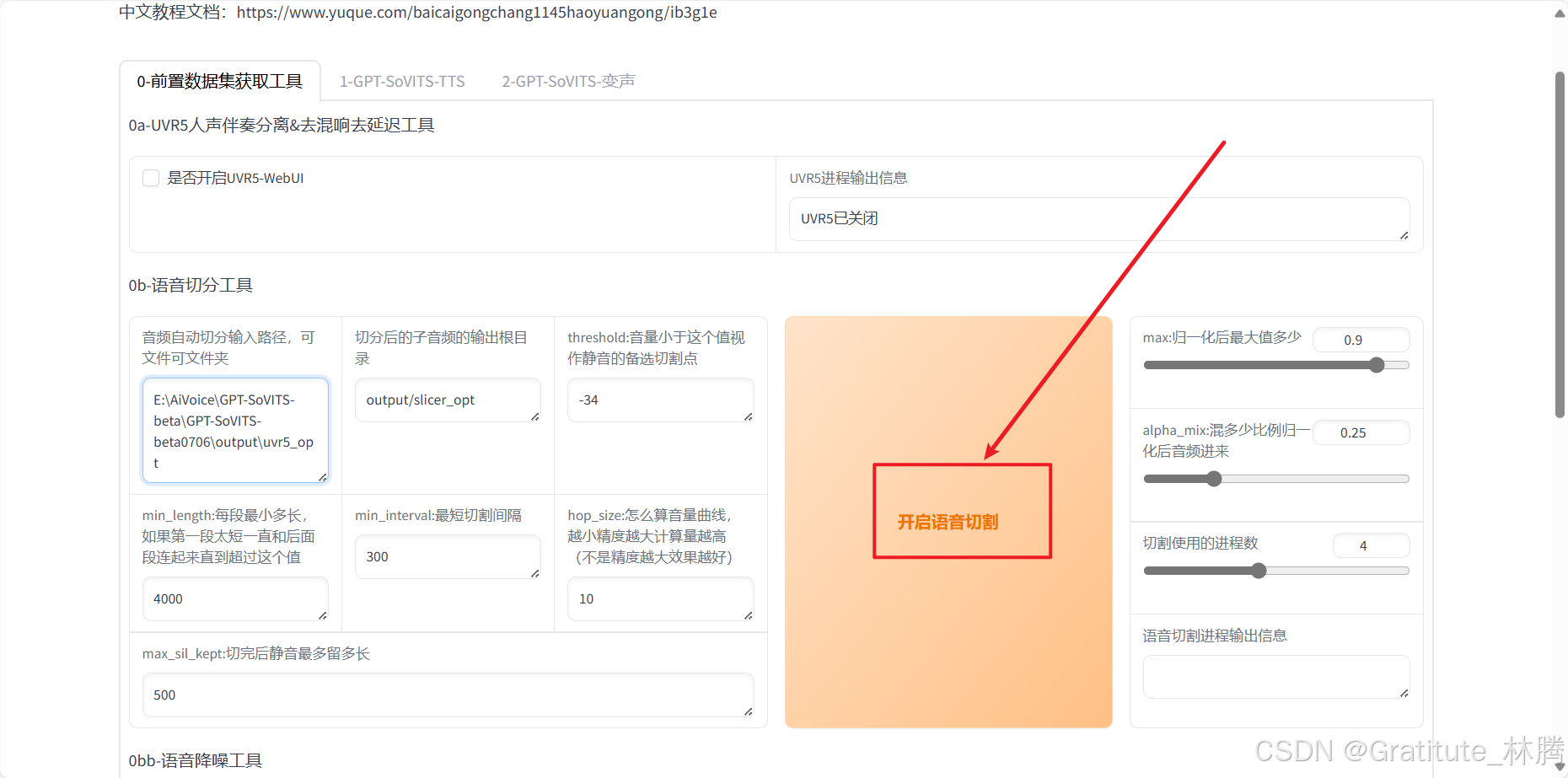
在下图所指位置输入音频所在文件夹路径:
其余参数保持不变,然后点击开启语言切割:
切割后的音频默认会输出在output/slicer_opt目录下,可以简单听一下,如果单个片段超过20秒,就需要清空音频,调整一下参数,重新切割一次。
打标
打标就是把音频对应的文本内容弄出来。
将切割后的音频所在的路径输入到下图所指位置:
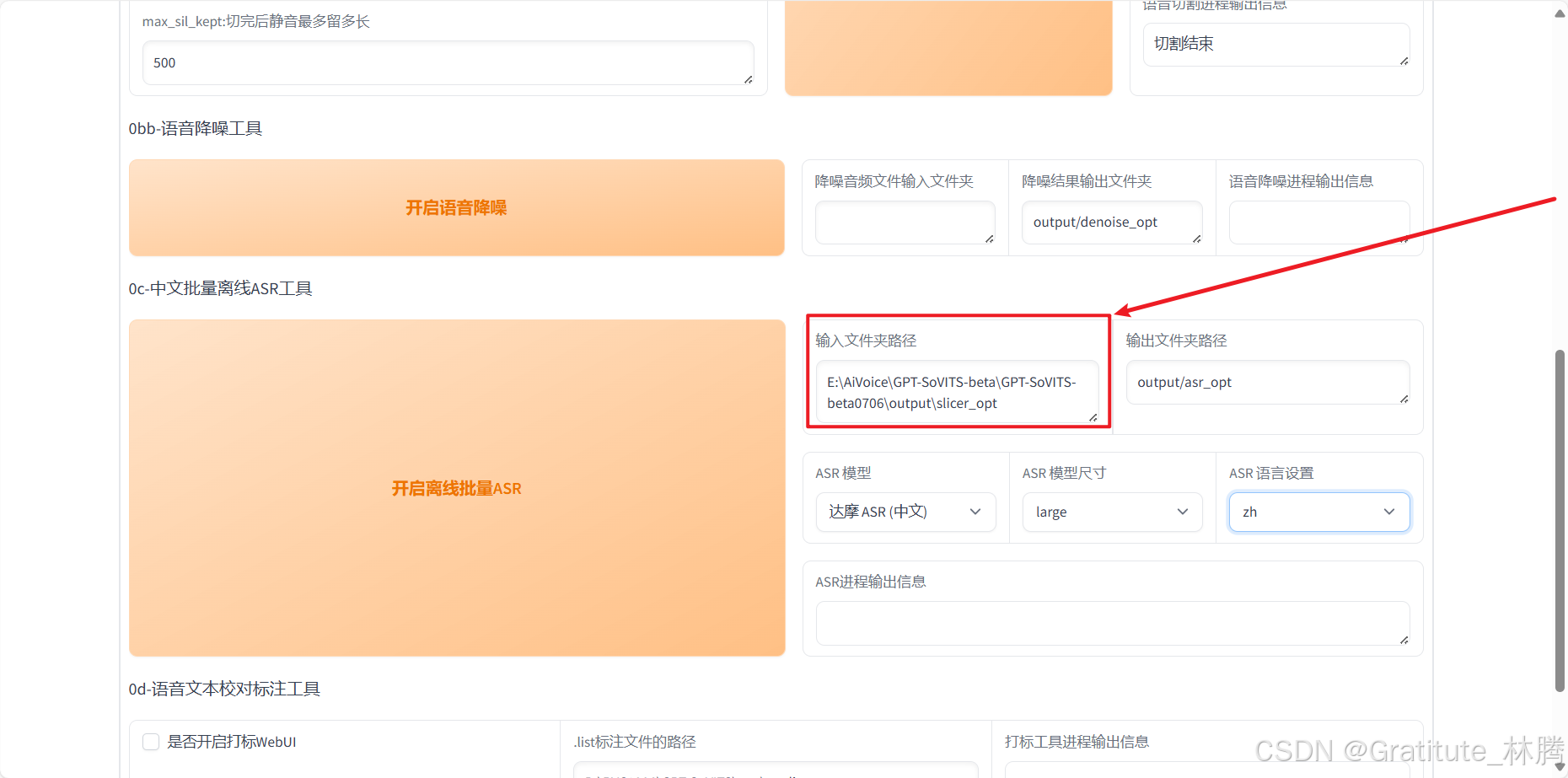
然后点击:
当输出下面的内容,说明打标完成:
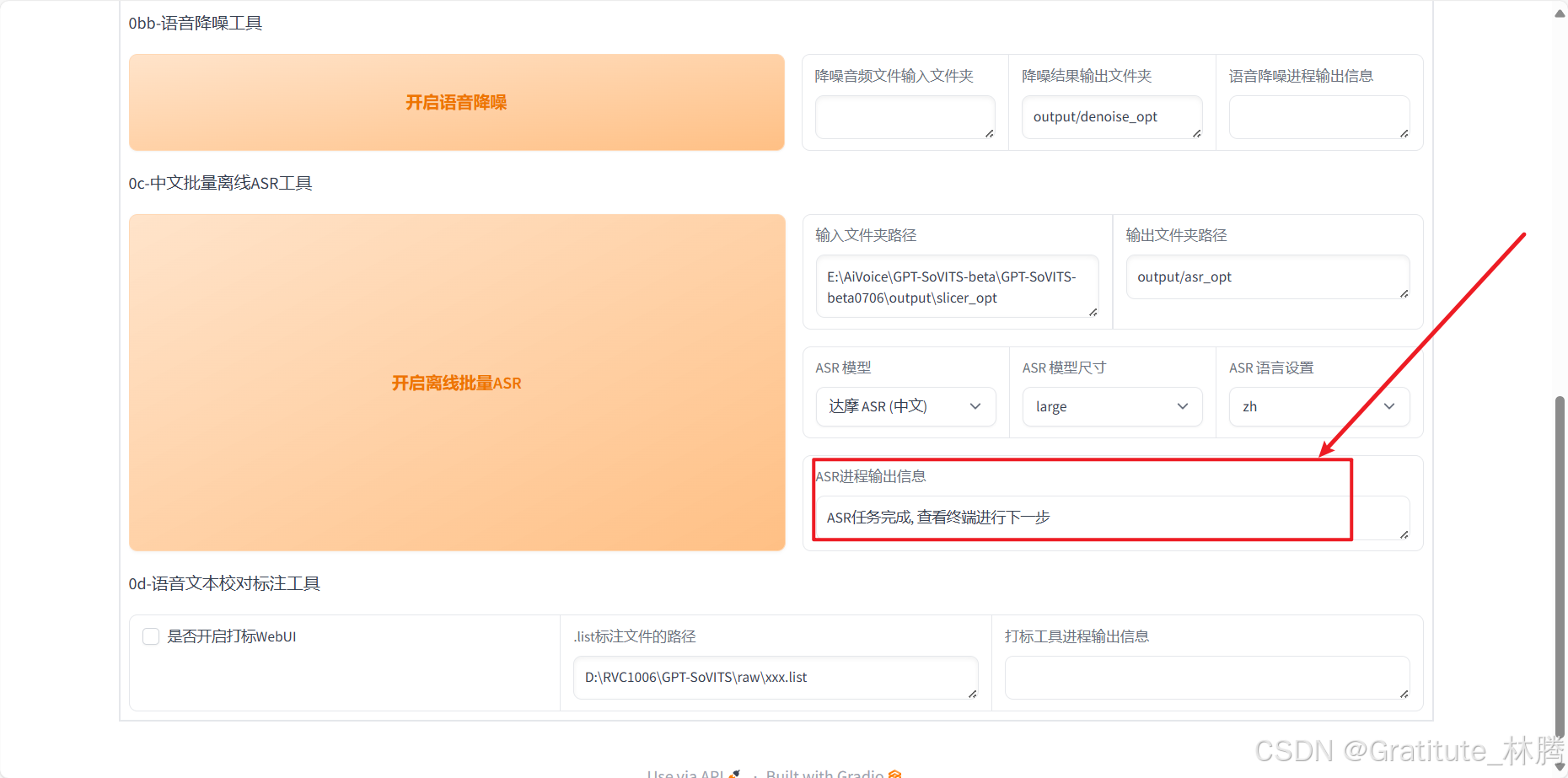
打标的结果默认在output/asr_opt目录下:
为了获得更好的效果,我们需要对打标结果进行校正。
复制文件地址:
粘贴到下图所指位置,并勾选打标WebUI:
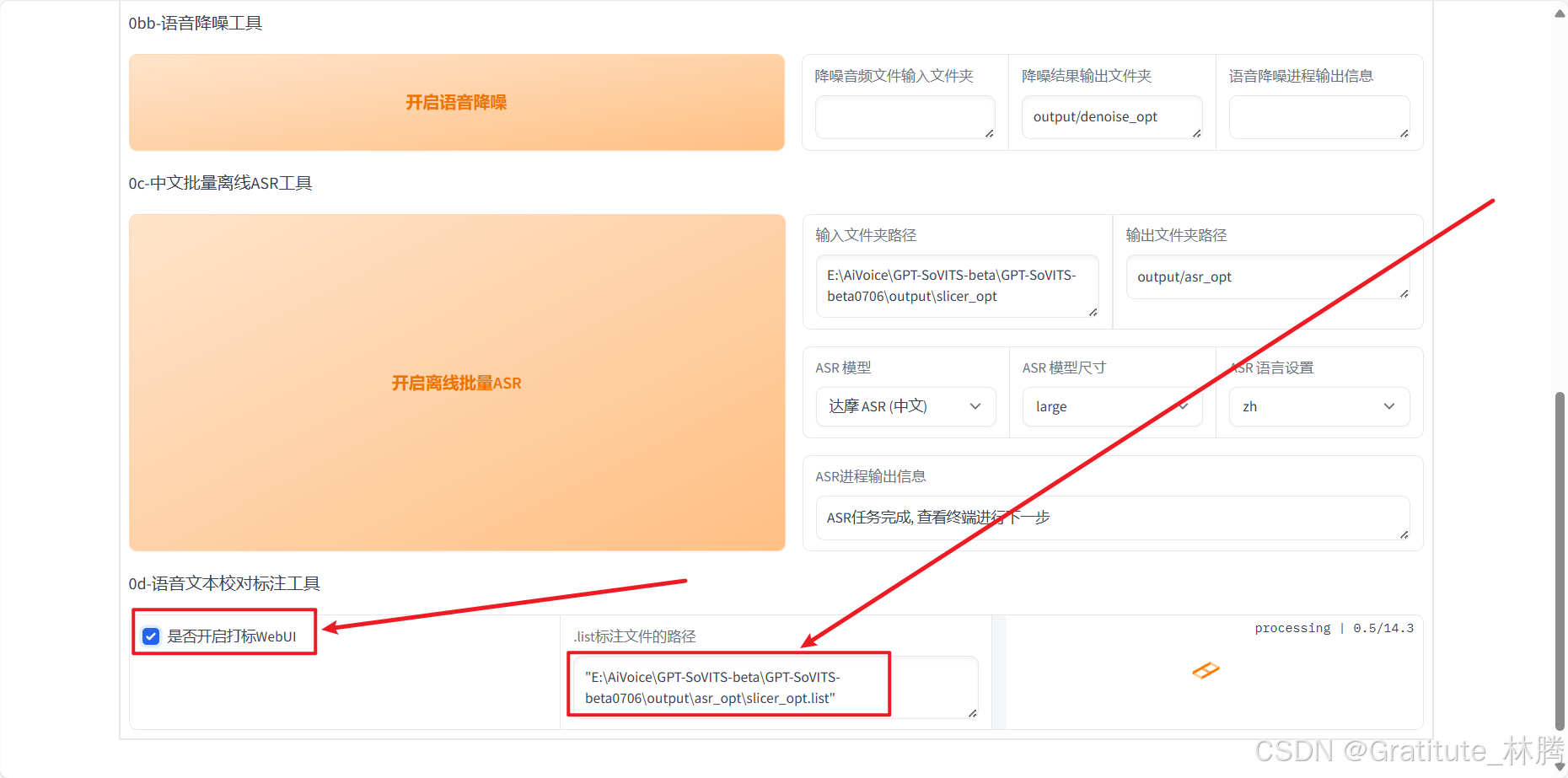
耐心等待,会自动打开:
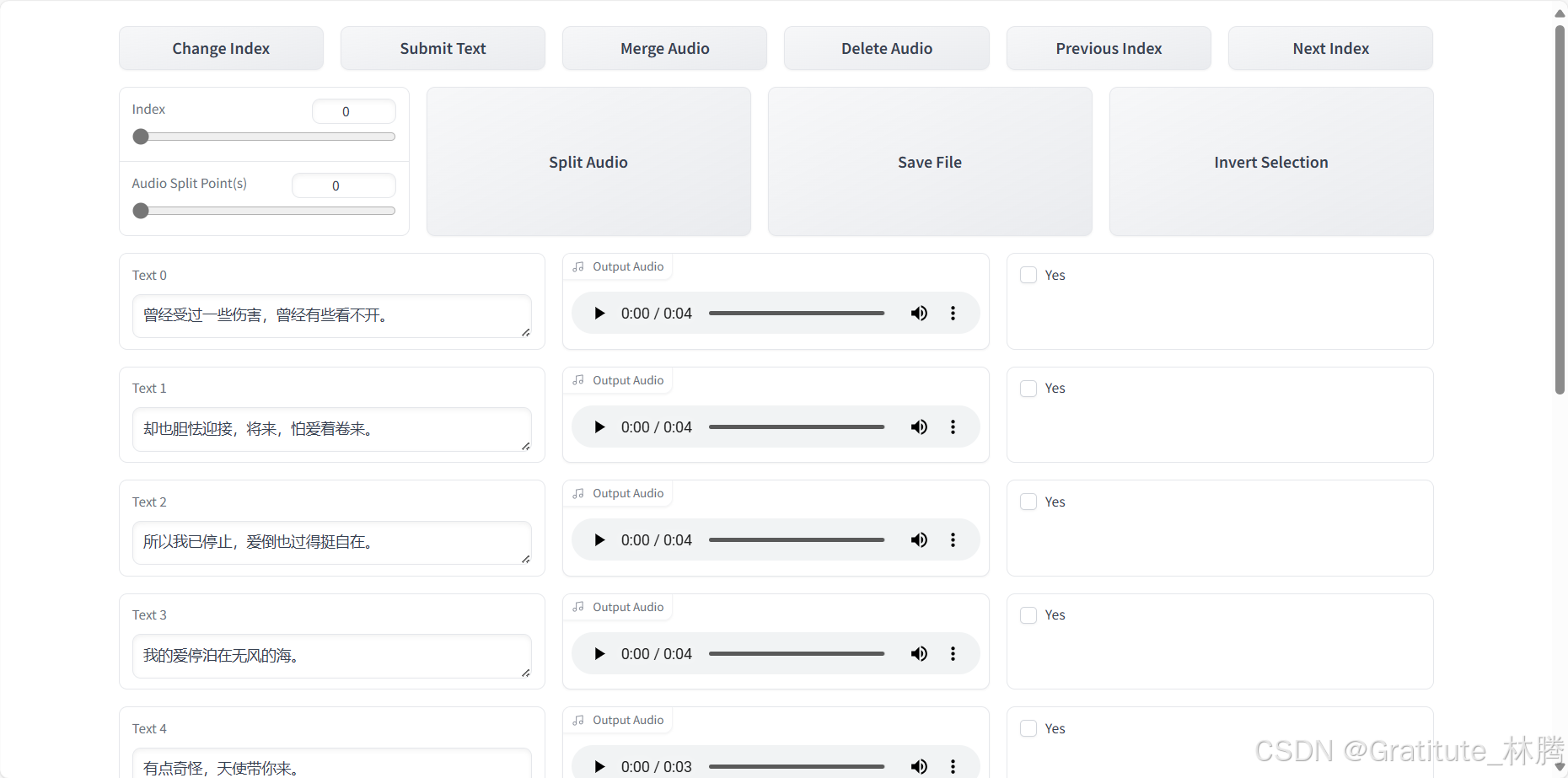
在该页面,可以播放音频,对照着左边的文本,看是否有差错,有的话就进行修改。也要注意停顿和标点是否对应,如果有停顿,而文本连贯,则需要手动插入逗号。
改完当前页后,点击Submit Text保存结果,并点击Next Index进入下一页:
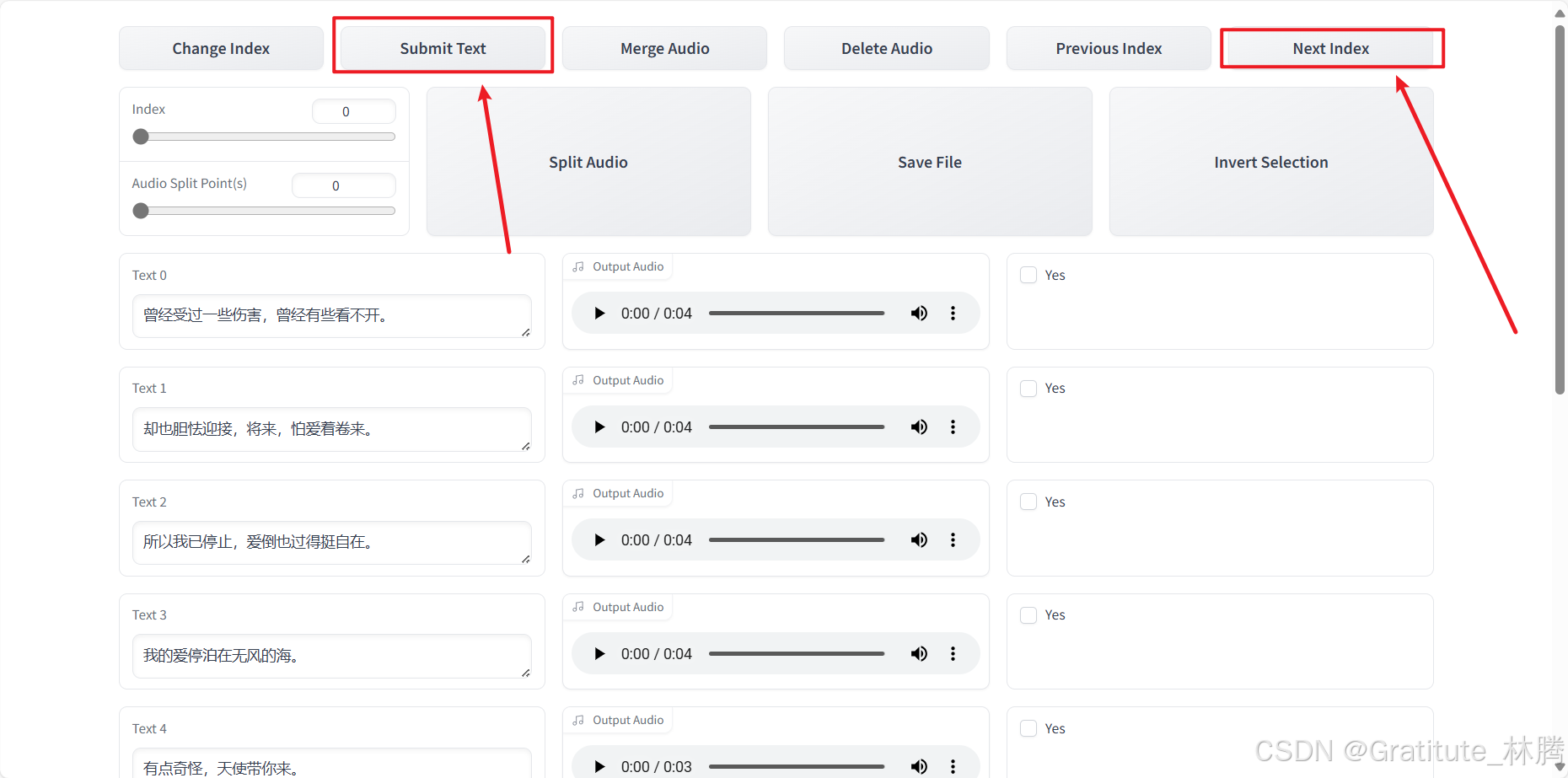
!!!注意,进入下一页前,一定要点击Submit Text保存,否则就白做了。
对于特别短或不想要的音频,可以点击yes,然后再点击Delete Audio:
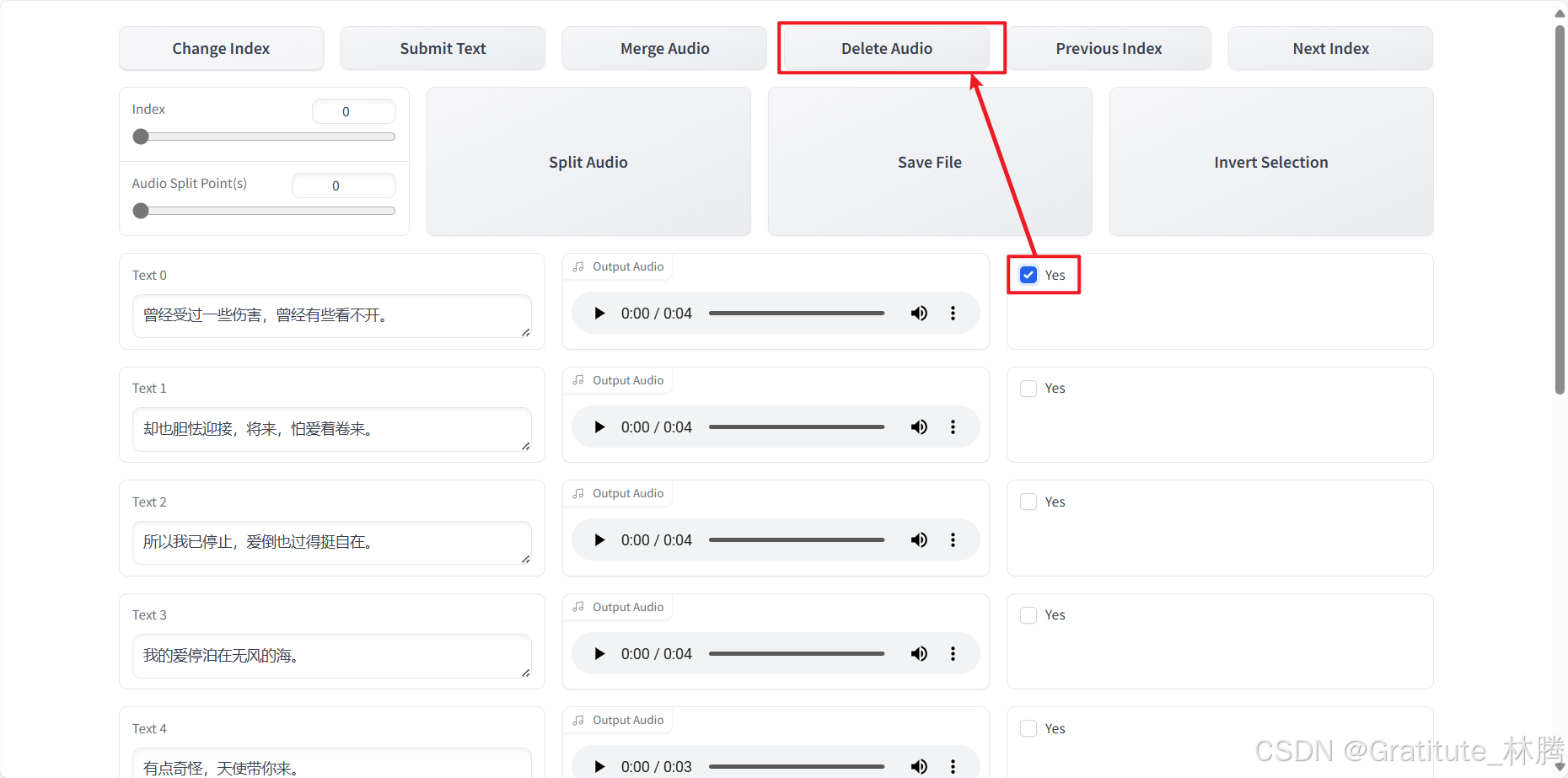
如果想合并音频,可以点击yes,然后点击Merge Audio:
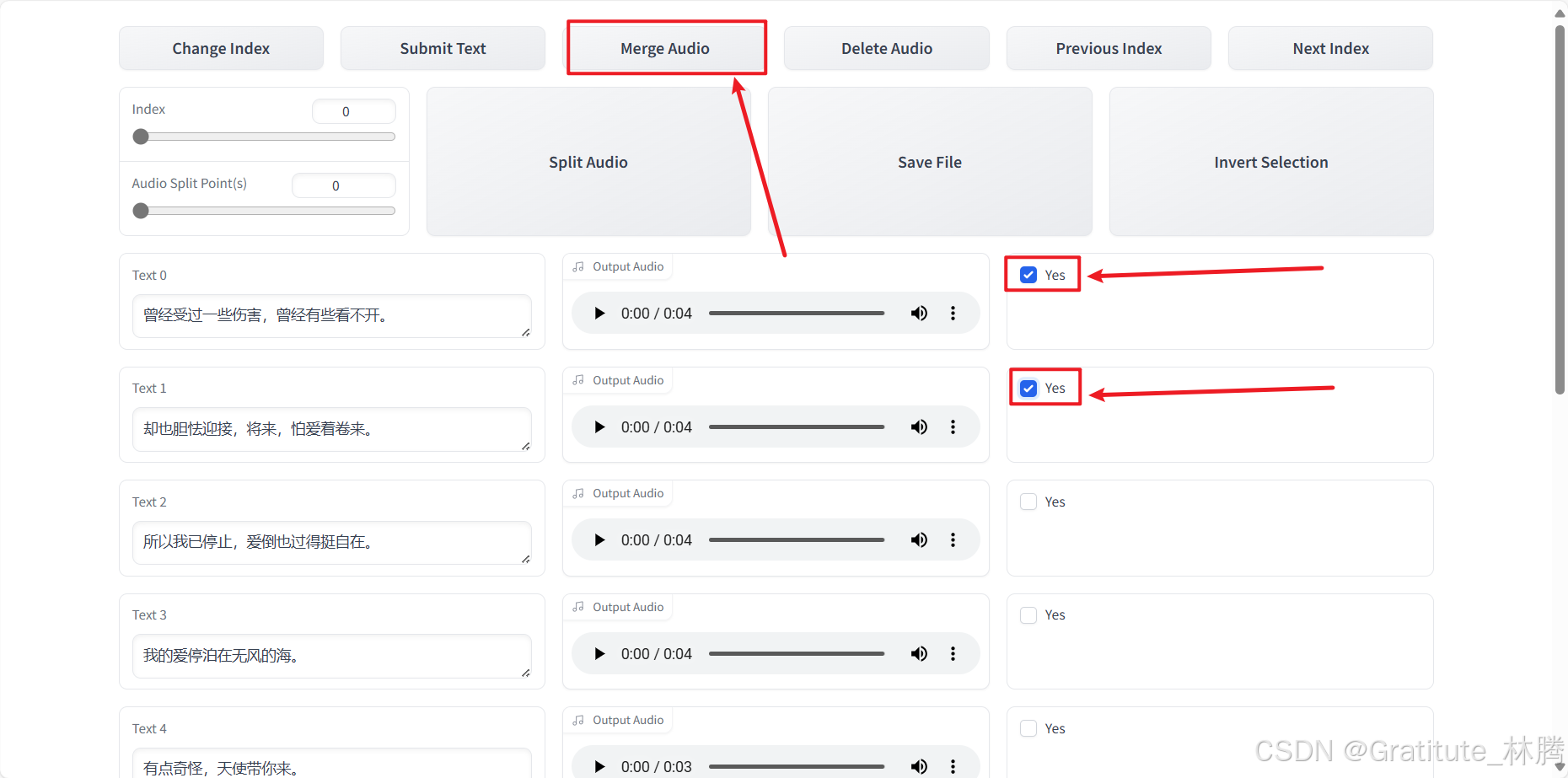
全部完成后,点击Save File,并关闭该页面即可。
然后取消勾选打标WebUI:
训练
切换到1-GPT-SoVITS-TTS:
用英文或数字填写一下名称:
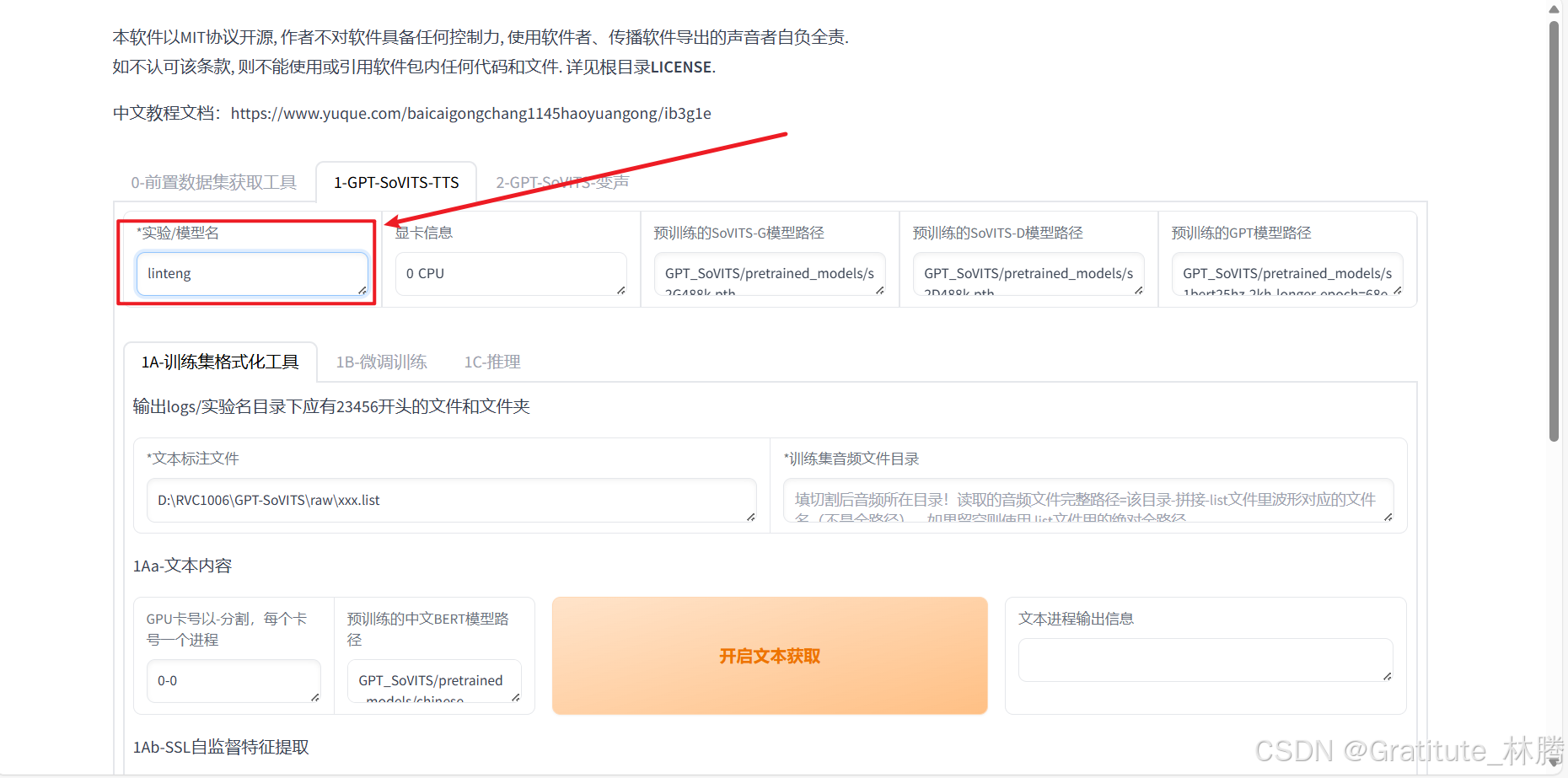
然后输入标注文件的路径和切割好的音频文件的路径:
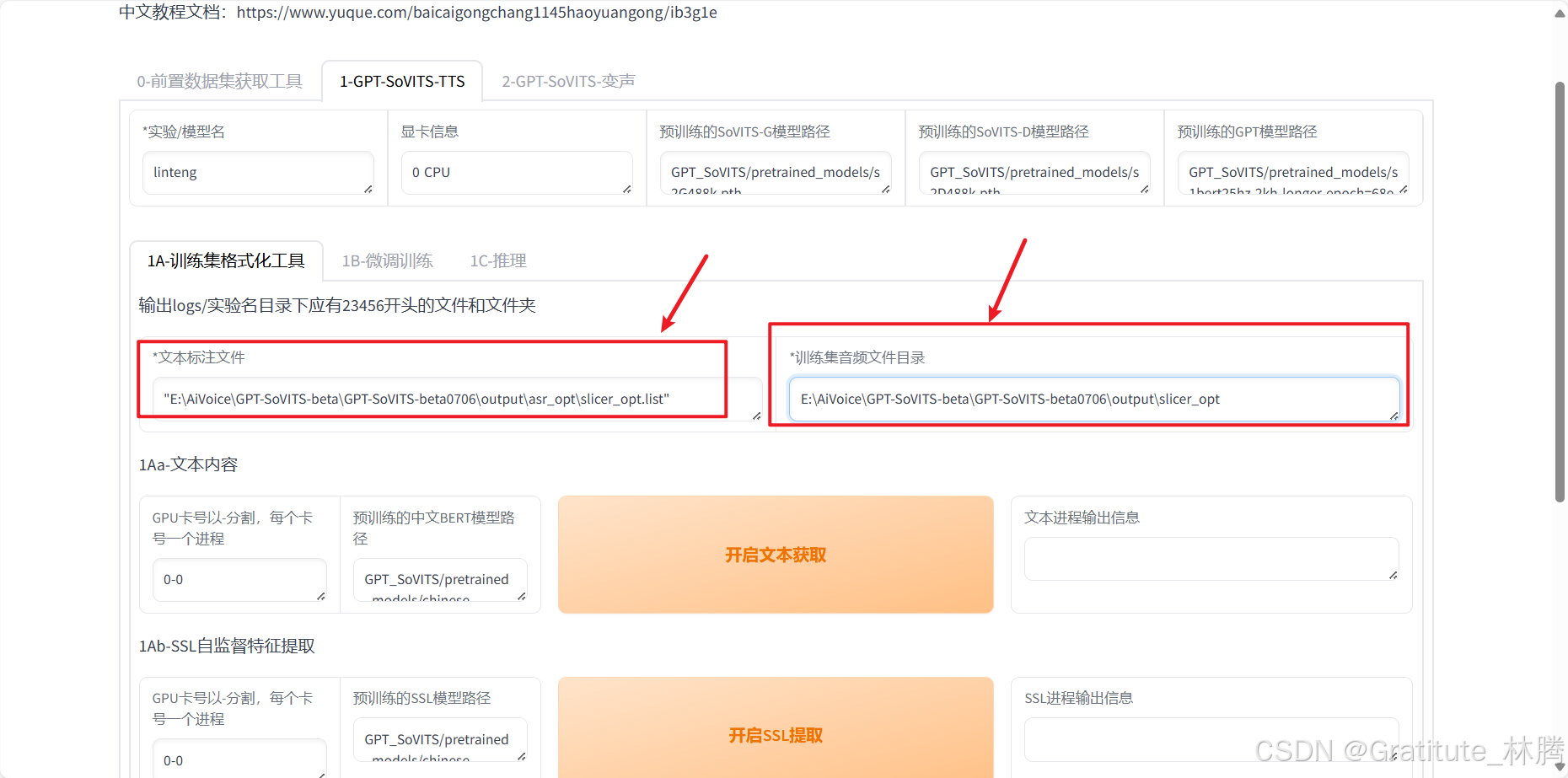
然后直接点击一键三连:
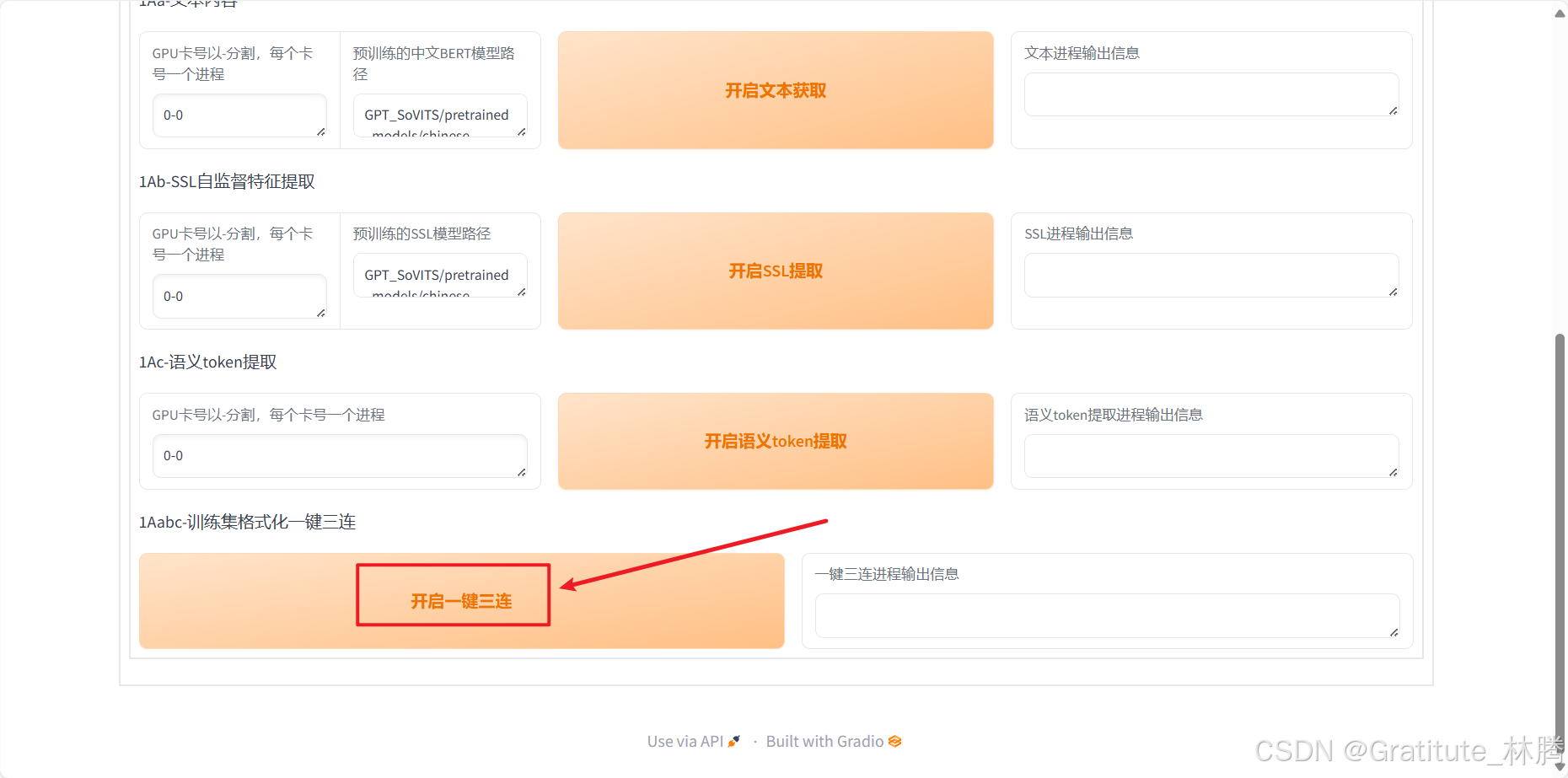
耐心等待后,当输出下面的内容,说明处理完毕
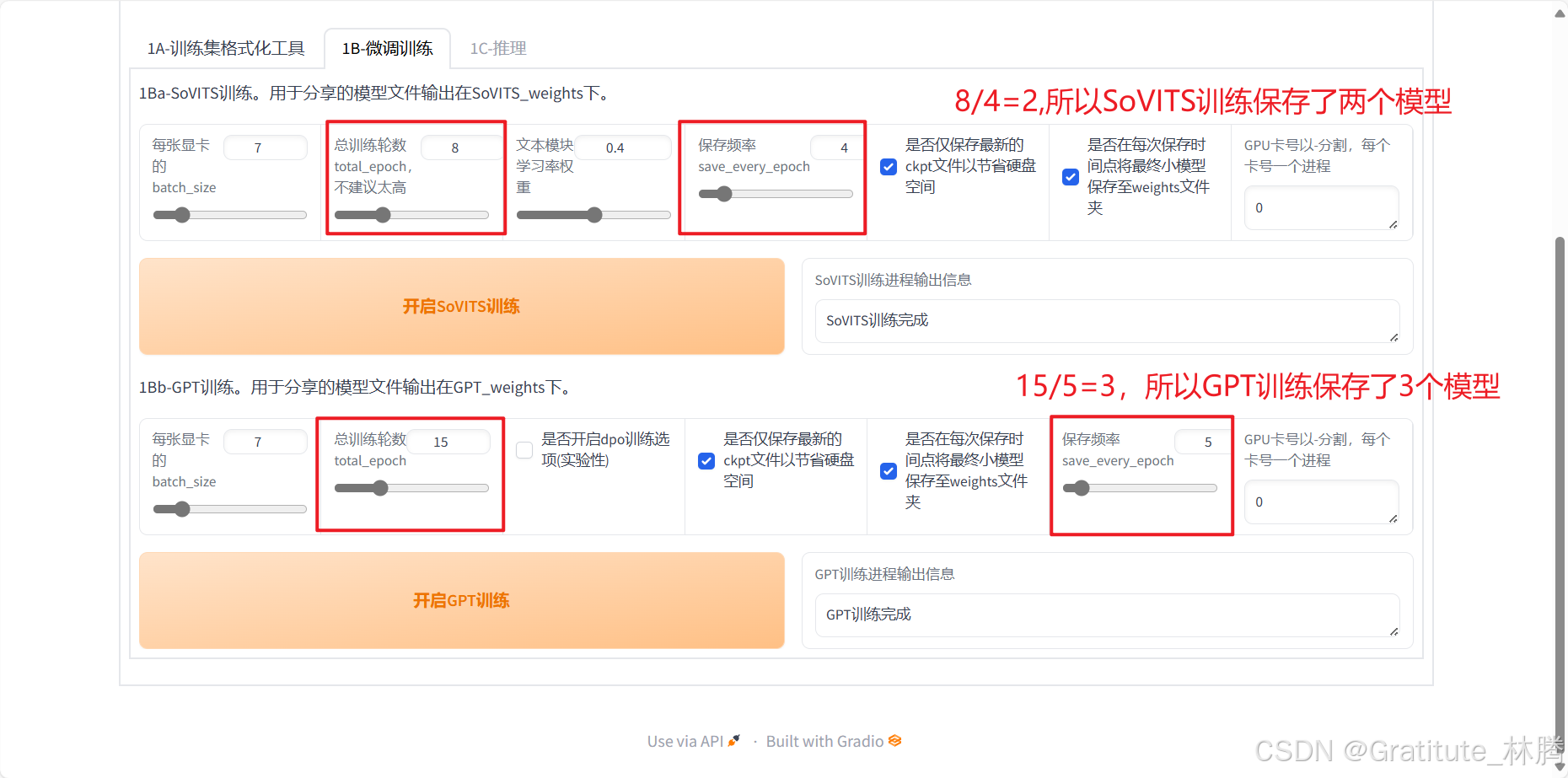
然后切换到1B-微调训练

参数先全部保持默认,依次进行下面两个模型的训练即可
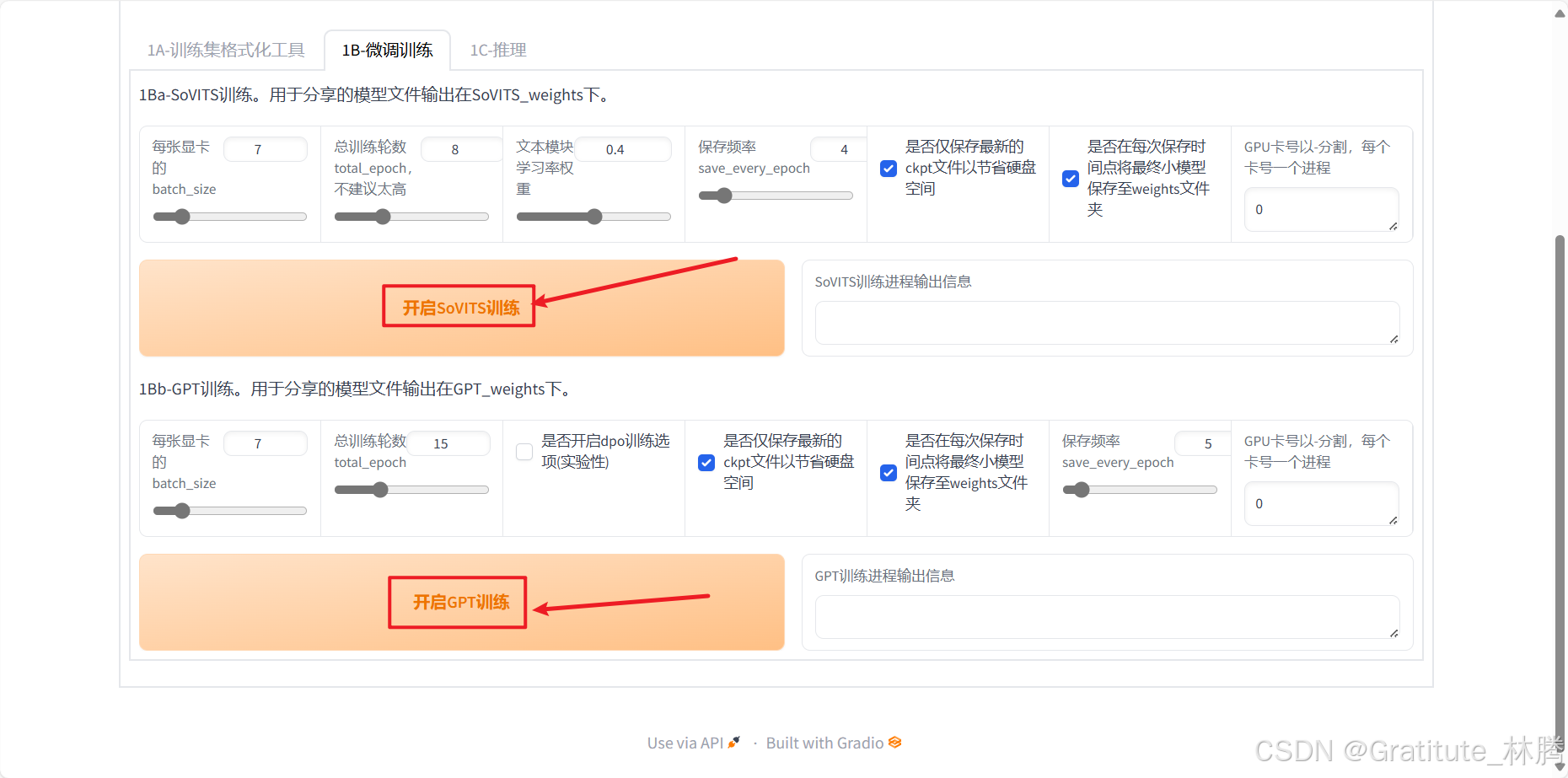
训练完成时,会有提示:
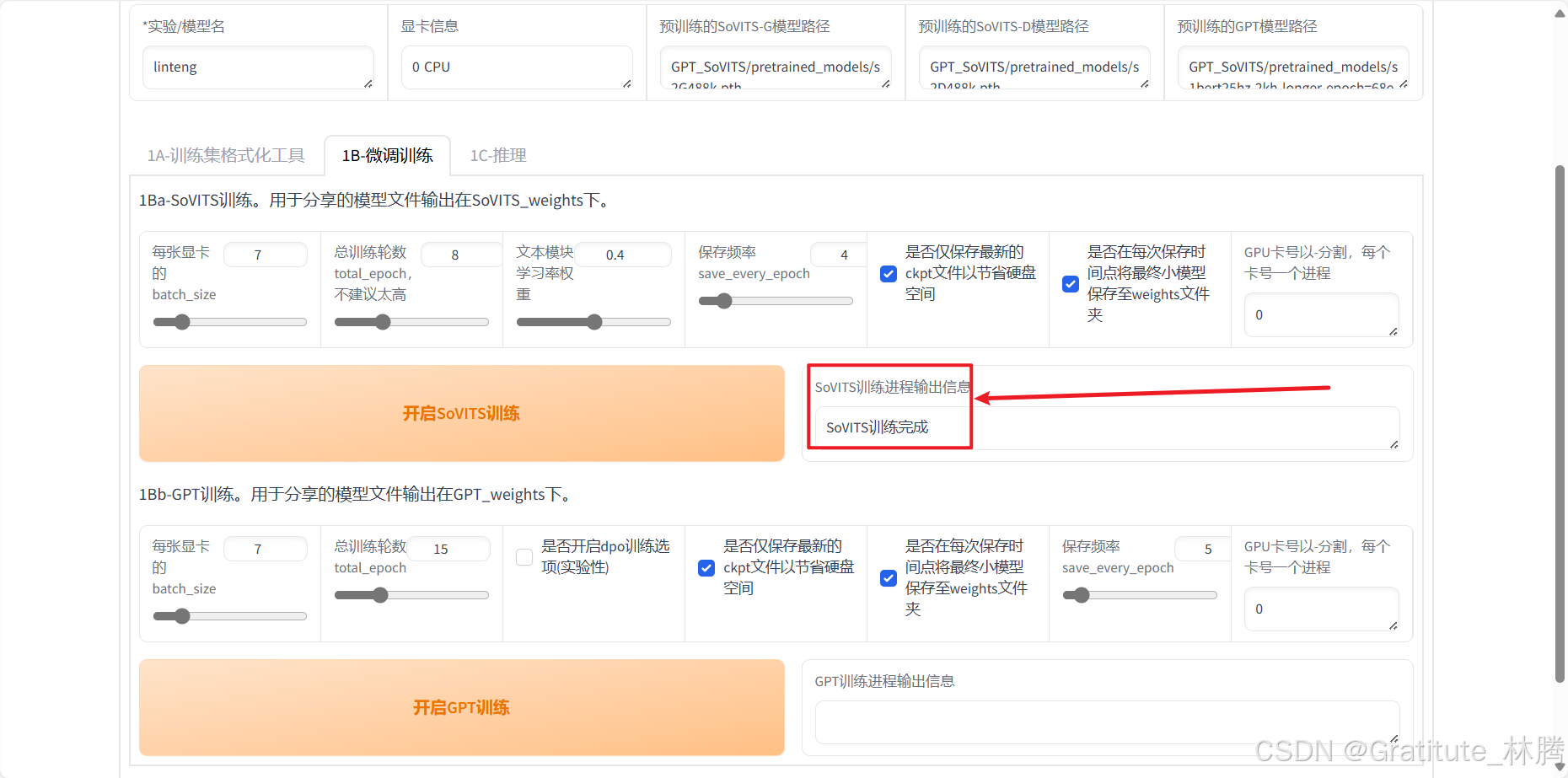
如果在命令行中看到下图的报错:

说明爆显存了,此时需要降低batch_size值,然后再次尝试,每次可以减4,看看能否正常进行。
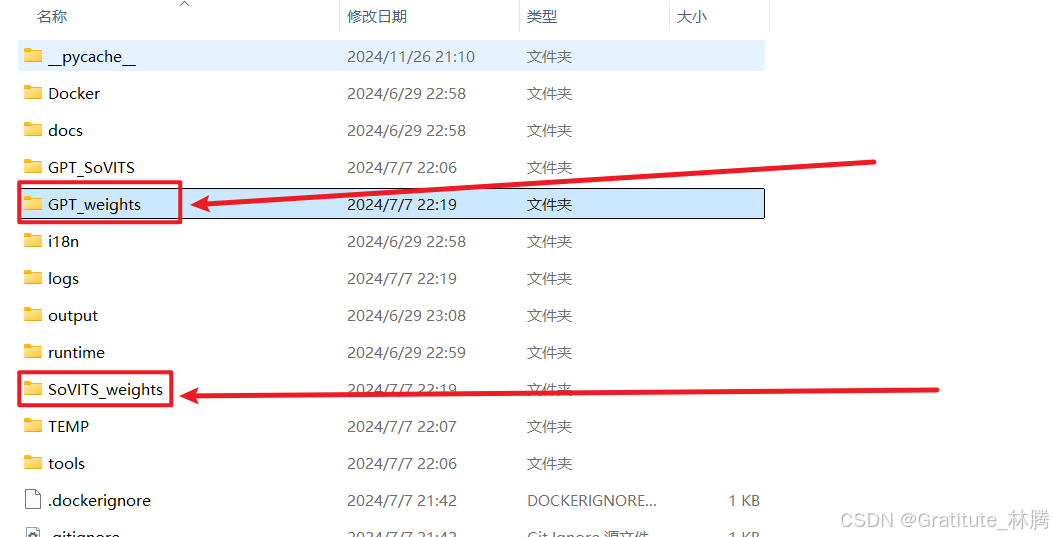
训练完成后,就可以在下面两个文件夹中找到训练出来的模型文件(如果没有,说明没成功):
总训练轮数/保存频率=保存的模型数量:
推理
切换到1C-推理
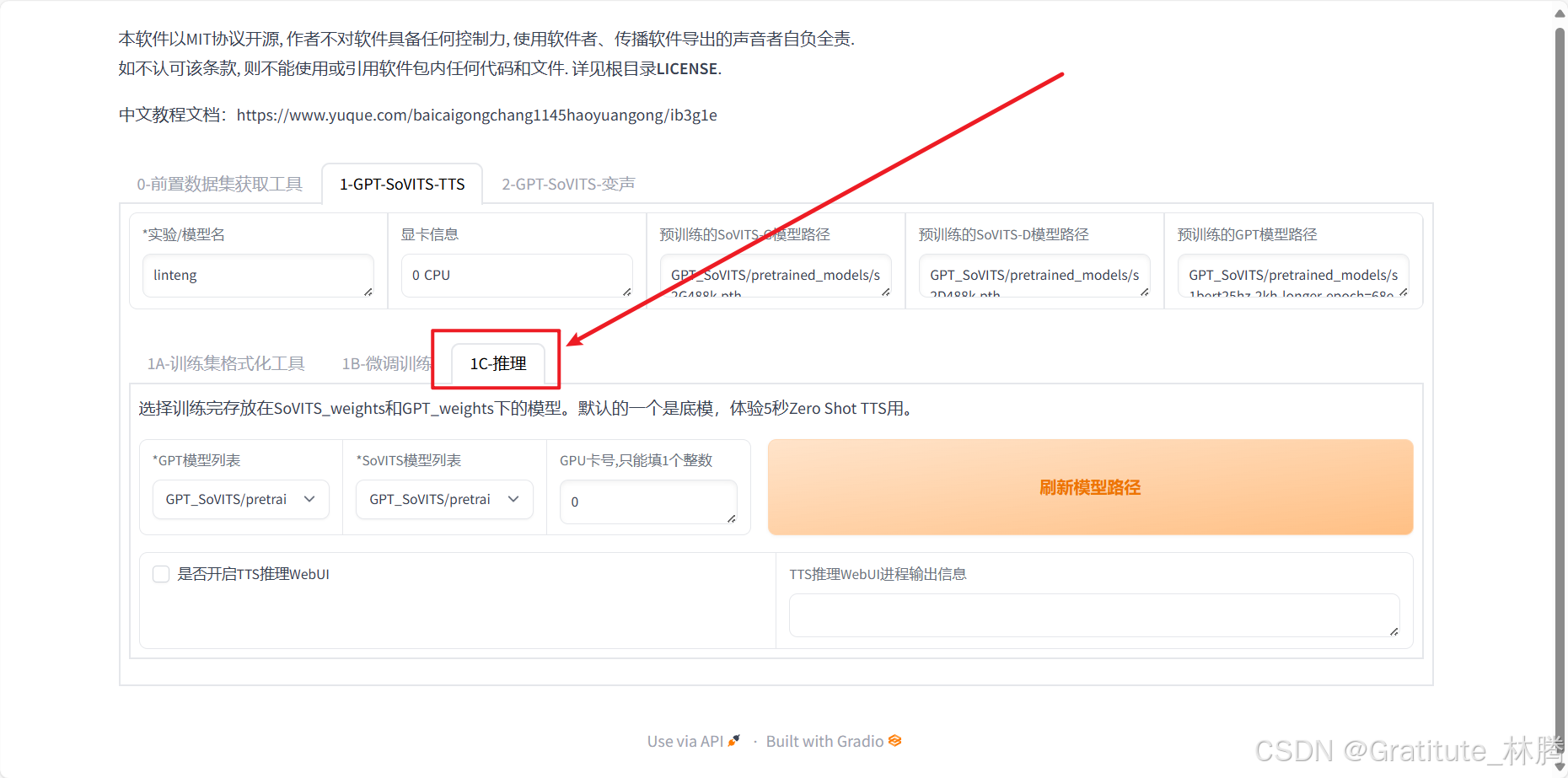
先点击刷新模型路径:
然后再依次选择自己训练的模型:
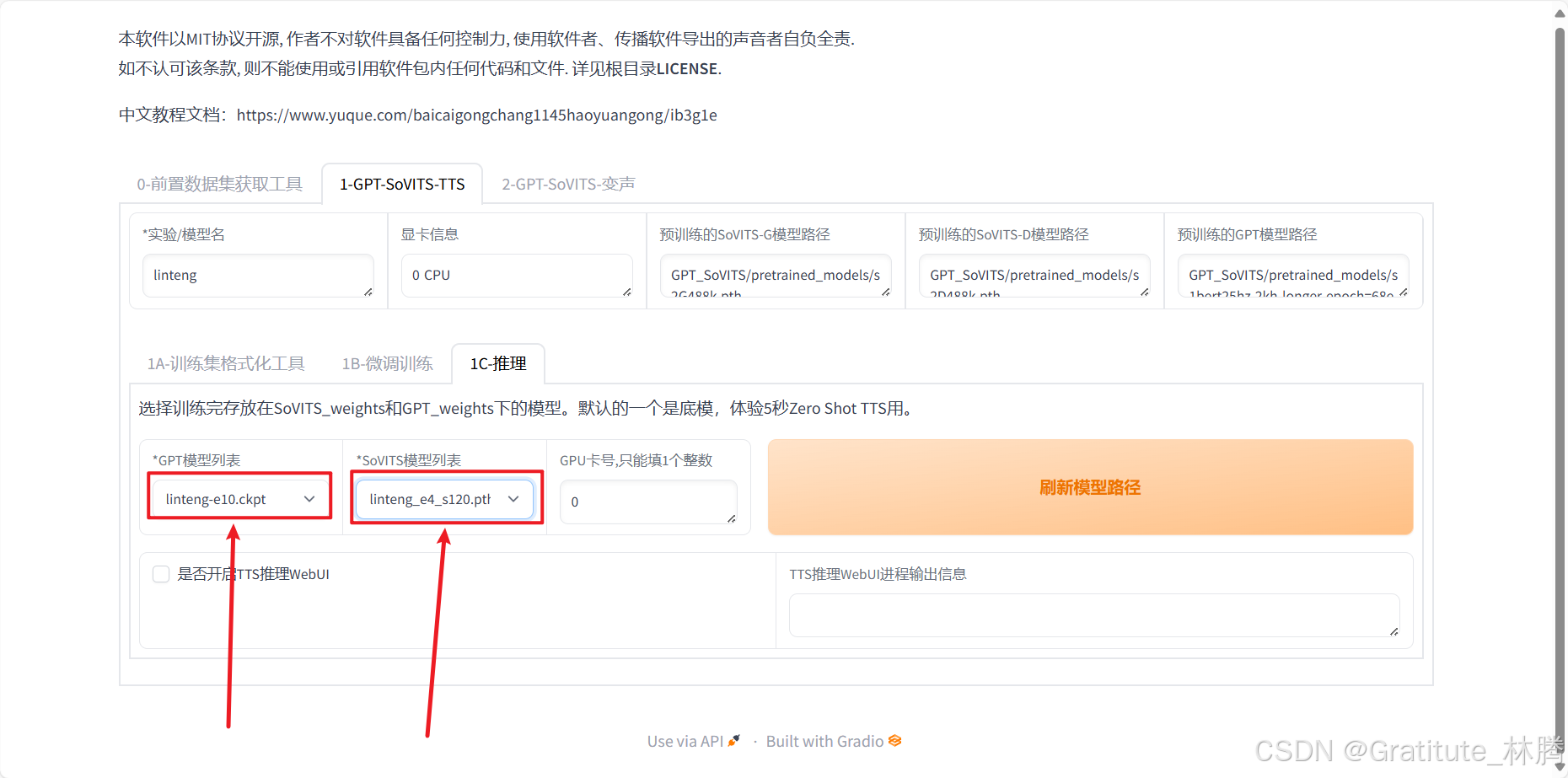
e10表示训练了10轮,s120表示训练的步数
然后再勾选TTS推理WebUI:
耐心等待推理页面的开启。。。。
然后拖入一段参考音频,音频不用太长,可以直接用我们已经切割好的音频。然后输入音频对应的文本、选择参考语种:
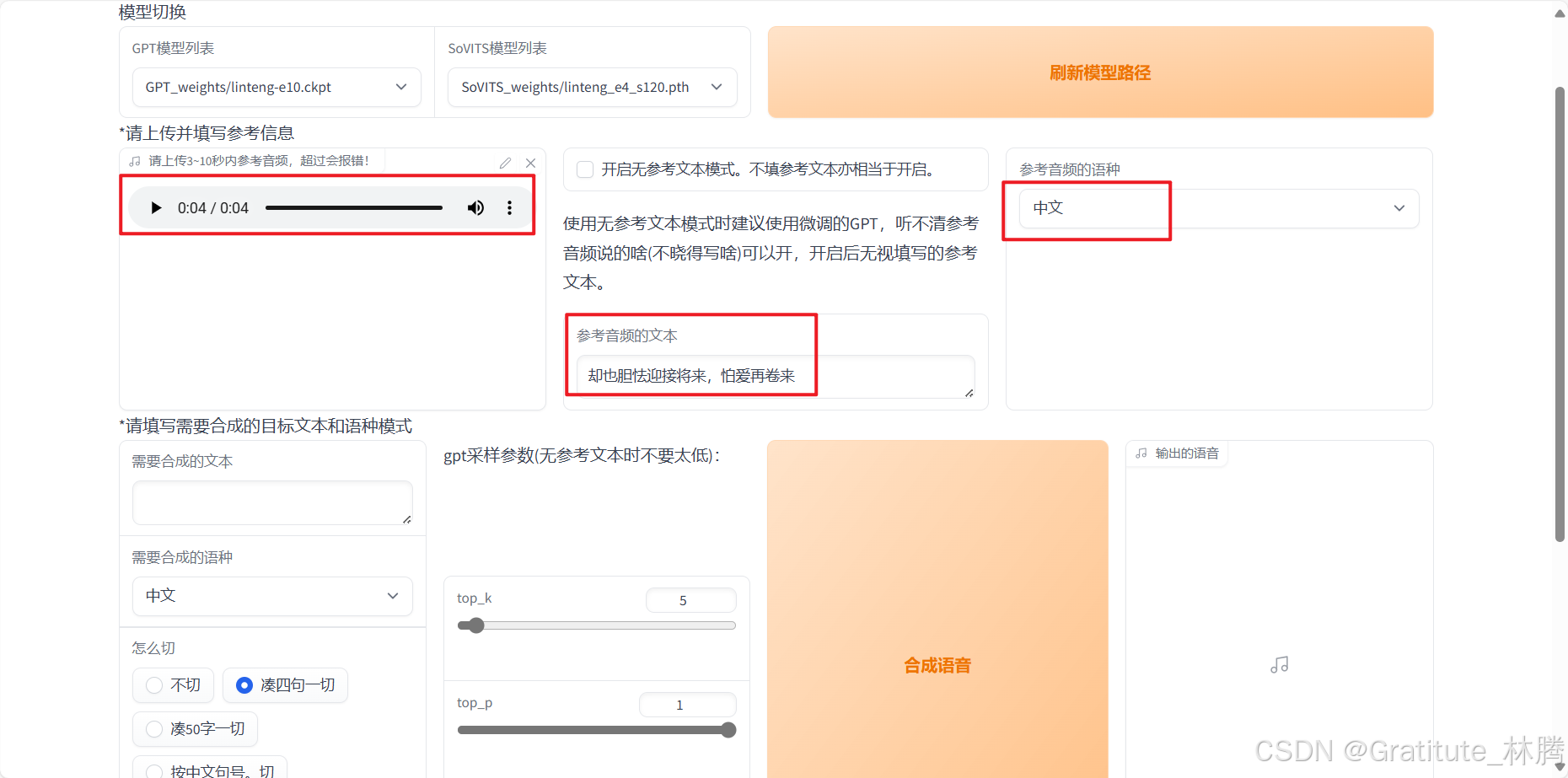
参考音频对最终合成的效果的影响比较大,如果想要获得平静一点的效果,参考音频也需要平静一点。
然后输入想要的文本,并点击合成语音,就可以得到生成的音频了:
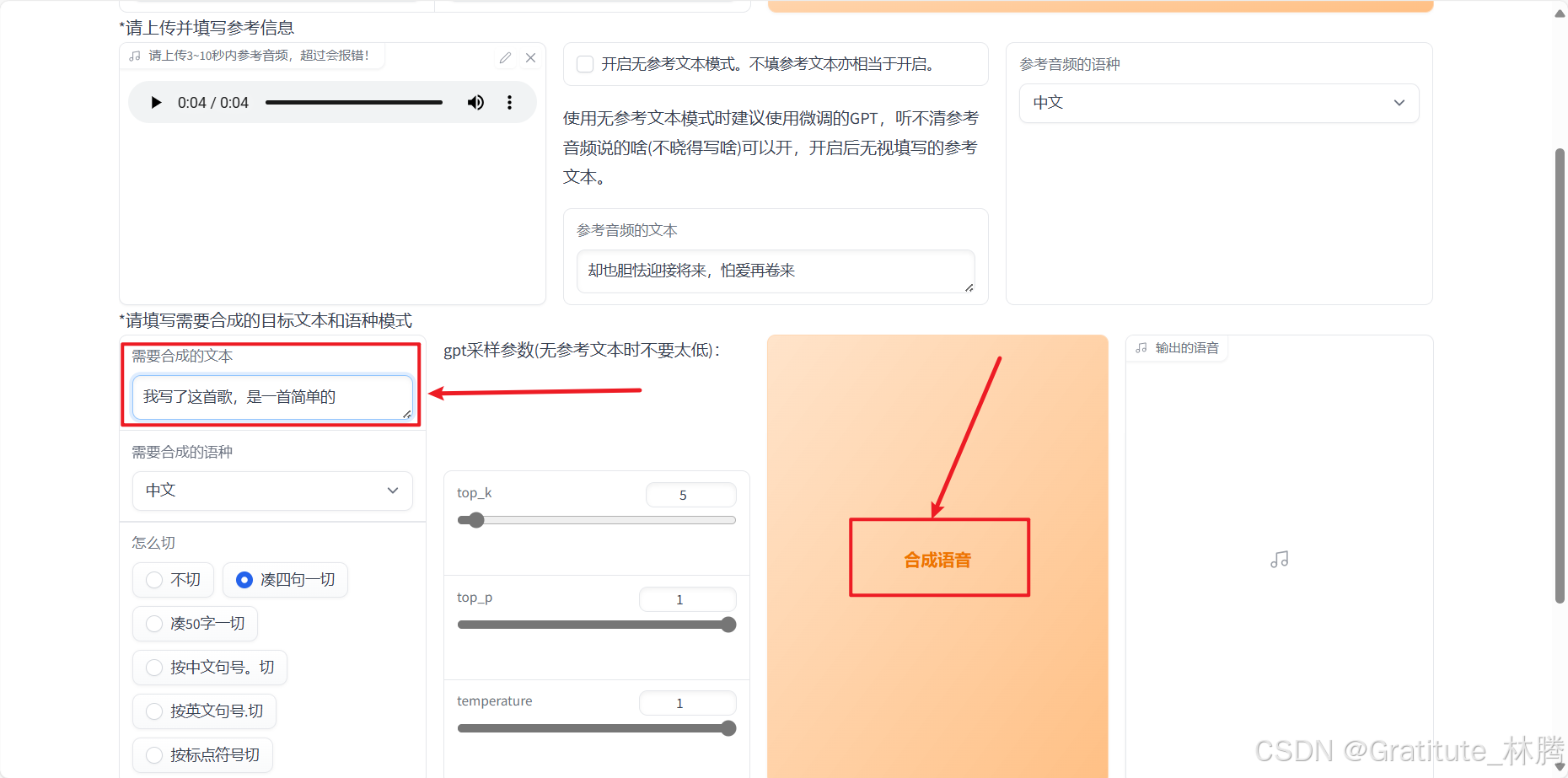
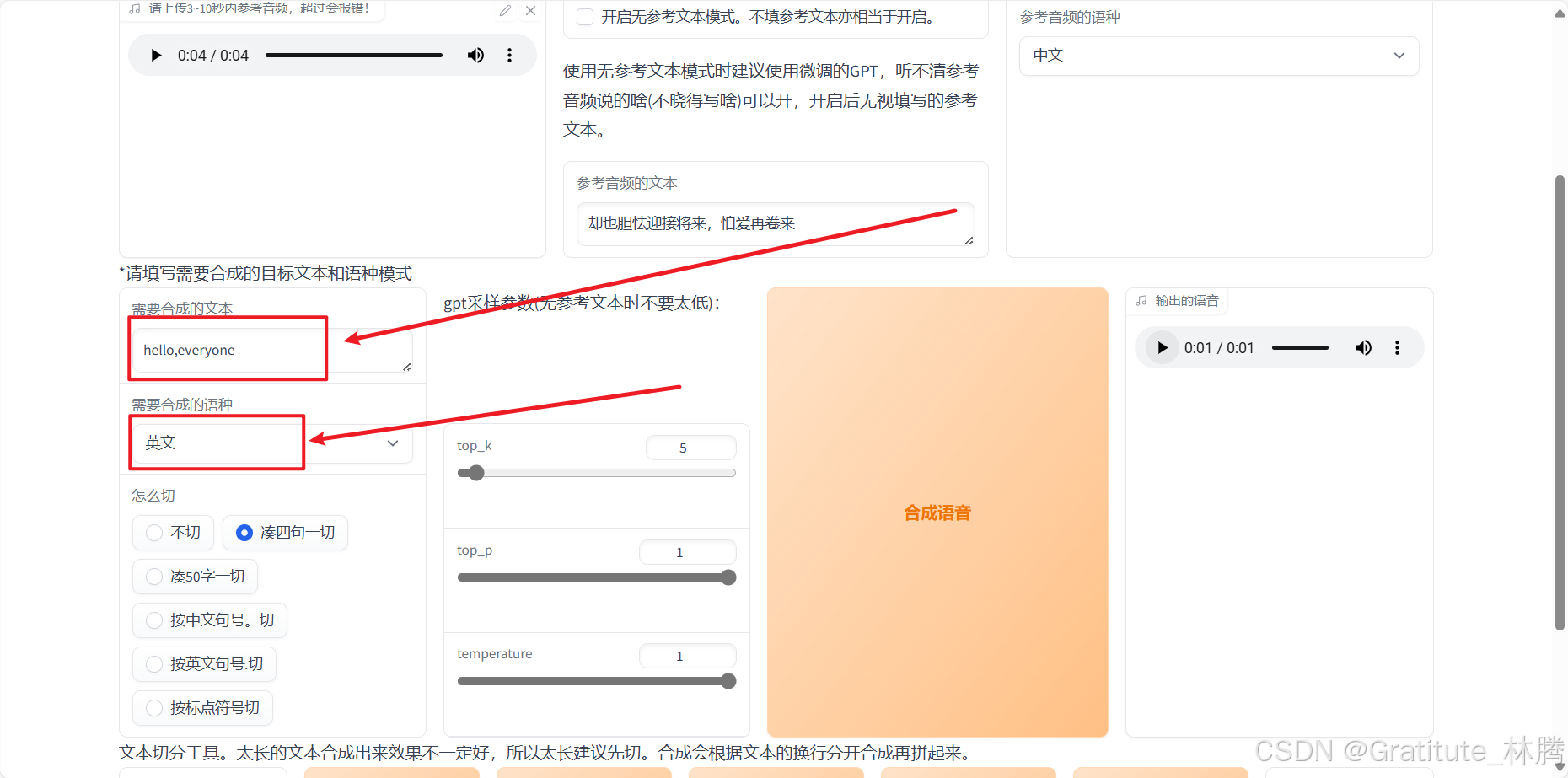
也可以合成英文音频,挺有意思的:
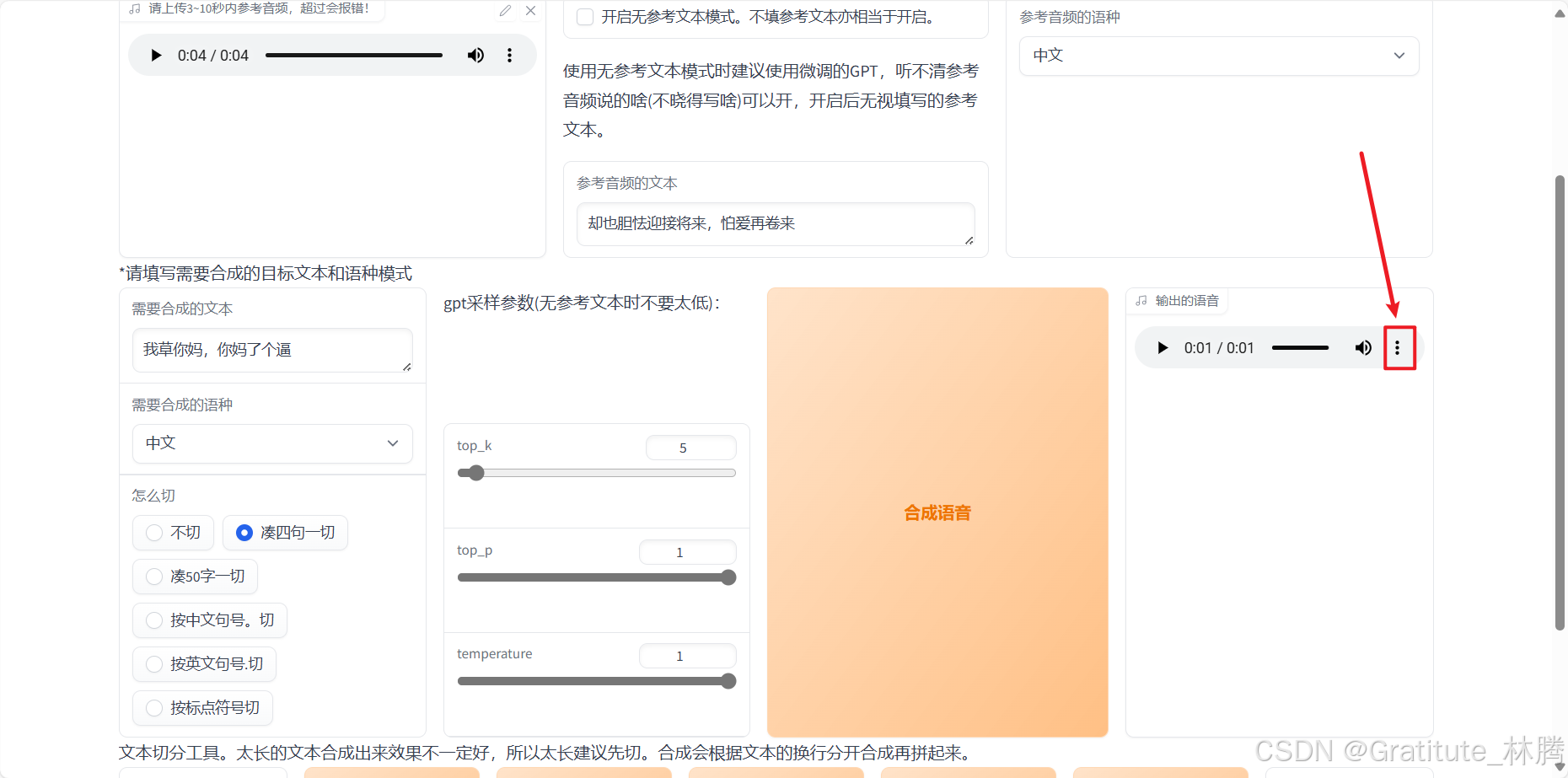
点击三个点,可以将生成的音频下载下来:
临时文件
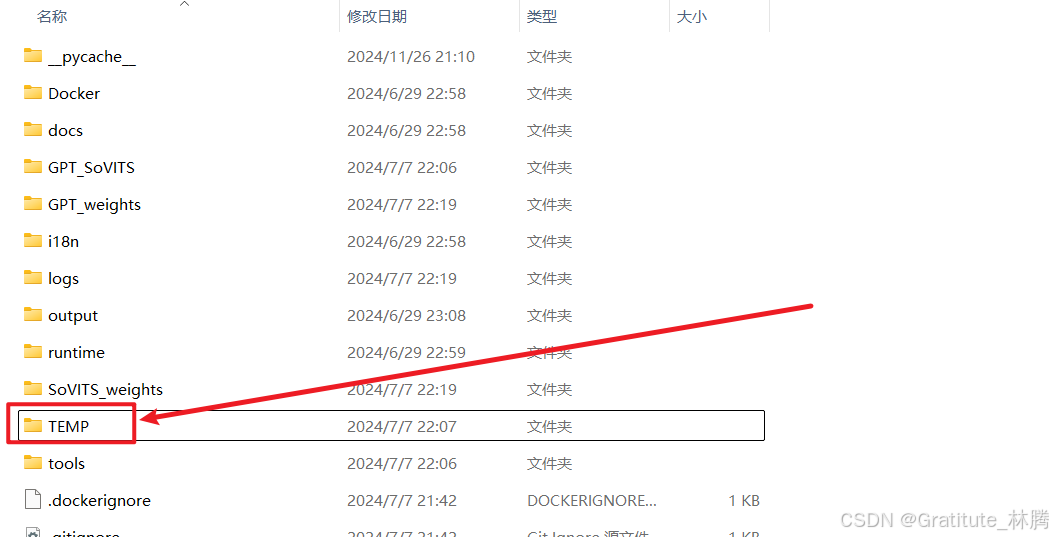
TEMP文件夹存放着我们使用过的音频,记得定时清理:
还有很多其他功能,待自己摸索了。。。。。

















 3135
3135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









