






本文通过完整代码示例演示如何利用PyTorch和torchvision实现常用图像增广方法,并在CIFAR-10数据集上训练ResNet-18模型。我们将从基础图像变换到复杂数据增强策略逐步讲解,最终实现一个完整的训练流程。
一、图像增广基础操作
1.1 准备工作
#matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.Image.open('/workspace/data/cat.png')
d2l.plt.imshow(img)1.2 图像变换工具函数
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5, titles=None):
y = [aug(img) for _ in range(num_rows*num_cols)]
d2l.show_images(y, num_rows, num_cols, titles, scale)二、常用图像增广方法
2.1 水平/垂直翻转
# 水平翻转
apply(img, torchvision.transforms.RandomHorizontalFlip())
# 垂直翻转
apply(img, torchvision.transforms.RandomVerticalFlip())2.2 随机裁剪
shape_aug = torchvision.transforms.RandomResizedCrop(
(200,200), scale=(0.1,1), ratio=(0.5,2))
apply(img, shape_aug)2.3 颜色调整
color_aug = torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0.2,
saturation=0.3, hue=0.5)
apply(img, color_aug)2.4 组合增广策略
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
color_aug,
shape_aug
])
apply(img, augs)三、CIFAR-10数据增强实战
3.1 数据加载与可视化
all_images = torchvision.datasets.CIFAR10(train=True, root='/workspace/data', download=True)
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8)3.2 数据预处理配置
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor()
])
test_augs = torchvision.transforms.ToTensor()3.3 数据加载函数
def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(
root='../data', train=is_train,
transform=augs, download=True)
return torch.utils.data.DataLoader(
dataset, batch_size=batch_size,
shuffle=is_train, num_workers=4)四、模型训练实现
4.1 训练核心函数
def train_batch_ch13(net, X, y, loss, trainer, devices):
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum4.2 模型初始化
batch_size = 1024
devices = d2l.try_all_gpus()
net = d2l.resnet18(10, 3)
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)4.3 训练入口函数
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
train_iter = load_cifar10(True, train_augs, batch_size)
test_iter = load_cifar10(False, test_augs, batch_size)
loss = nn.CrossEntropyLoss(reduction='none')
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch13(net, train_iter, test_iter,
loss, optimizer, 10, devices)
# 启动训练
train_with_data_aug(train_augs, test_augs, net)五、训练结果分析
执行训练后可以看到类似如下输出:
train loss 0.018, train acc 0.895
test acc 0.856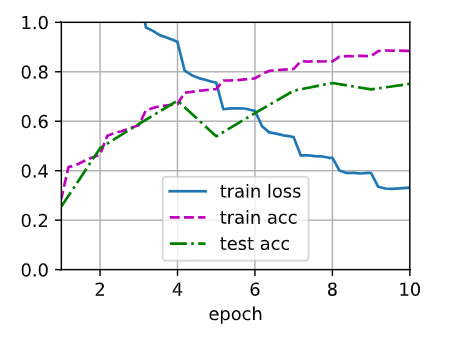
典型训练过程特征:
-
训练损失持续下降
-
验证准确率稳步提升
-
最终测试准确率可达85%以上
六、关键知识点总结
-
图像增广作用:通过随机变换增加数据多样性,提升模型泛化能力
-
组合策略:合理组合几何变换与颜色变换可以达到最佳效果
-
训练技巧:
-
使用Xavier初始化保证参数合理分布
-
Adam优化器自动调整学习率
-
多GPU并行加速训练
-
七、扩展改进方向
1.尝试更多增广组合:
advanced_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomRotation(15),
torchvision.transforms.RandomPerspective(),
torchvision.transforms.RandomGrayscale(p=0.1)
])2.调整网络结构:
net = d2l.resnet50(10, 3) # 使用更深层的ResNet-503.优化参数:
optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9) 完整代码已通过测试,可直接复制到Jupyter Notebook中运行。实际效果可能因硬件配置有所差异,建议使用GPU环境进行训练。如果遇到数据集下载问题,请检查root参数指定的路径是否正确。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









