







 本文探讨了聚类算法与二分类算法的对比,重点介绍了聚类算法如K-means,其通过无监督学习自动识别数据结构并进行分类。应用领域包括新闻分类、DNA分析等。
本文探讨了聚类算法与二分类算法的对比,重点介绍了聚类算法如K-means,其通过无监督学习自动识别数据结构并进行分类。应用领域包括新闻分类、DNA分析等。
以下内容有任何不理解可以翻看我之前的博客哦:吴恩达deeplearning.ai专栏
聚类算法通过分析大量数据,自动把数据分为好几个不同的类别。让我们看看具体是怎么做的。
对比——聚类算法和二分类算法
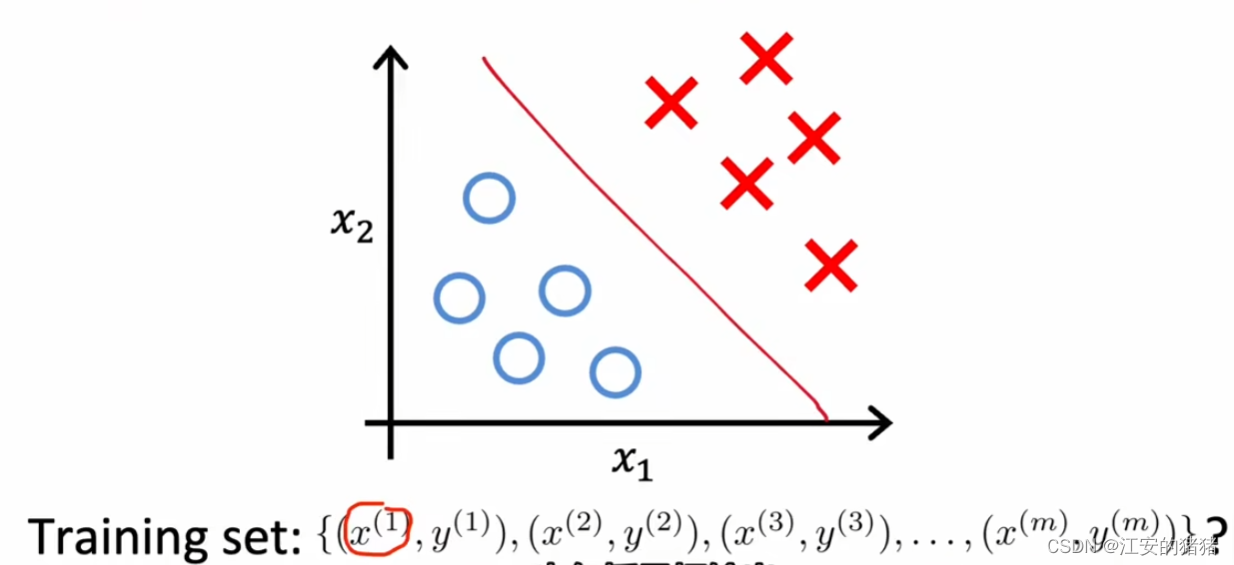
二分类算法
在我们之前提到过的二分类算法之中,你的数据集的每组数据包含两钟数据x,y;其中x代表每个数据的具体特征输入,而y代表每个特征的输出,同时包含输入和输出,那么就可以设计函数进行拟合,从而得到如图中红色线类似的拟合曲线。
聚类算法 Clustering Algorithm
在聚类算法之中,我们的输入仅仅包含一个输入x,所以图中的点不再被提前人为划分为类似上图的圆圈和叉叉,而是一堆黑点。因为没有标签y,所以我们不知道数据需要划分为几类。因此我们需要算法自己好好努力,去找到一些这些数据的特点,从而让算法替我们把数据划分。
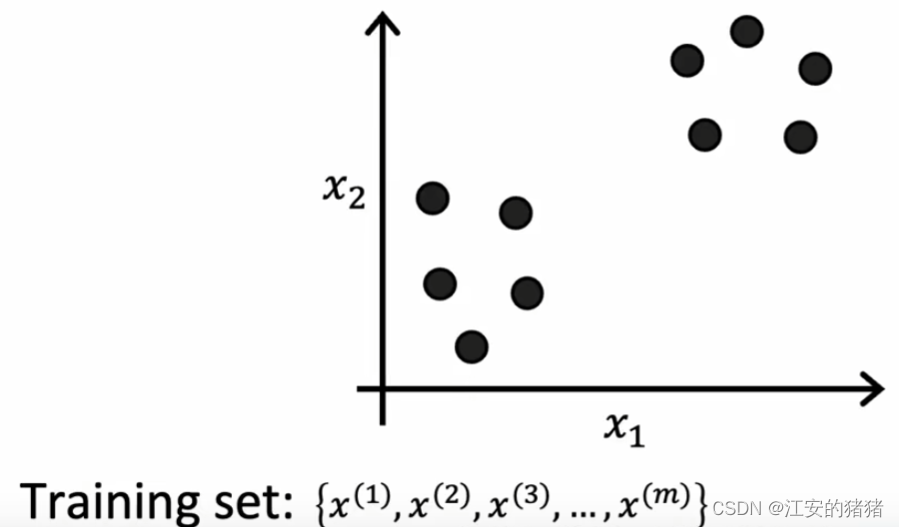
今天我们要了解的算法叫做聚类算法,它的工作方式是寻找你的数据里面的特定结构,并将同一类型的结构划分到一组之中,从而完成分类。
聚类算法的应用
聚类算法常用于:
- 新闻分类
- DNA分析
- 市场目标人群划分
- 天文分析

最常用的聚类算法——K-means Algorithm
让我们举个例子:
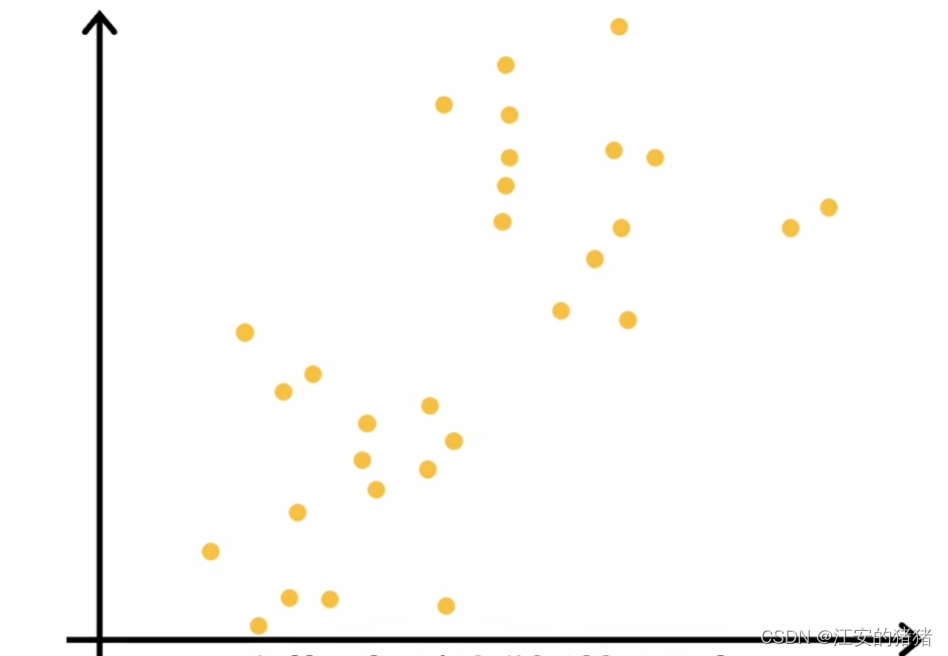
上图中的黄点是一些输入特征,k-means算法的第一步是会随机选择两个点,这里表现为红色和蓝色,它们可能表示的是两个不同集群的中心。如下图,当然,这两个选择可能不那么好,但是这只是一个开始:
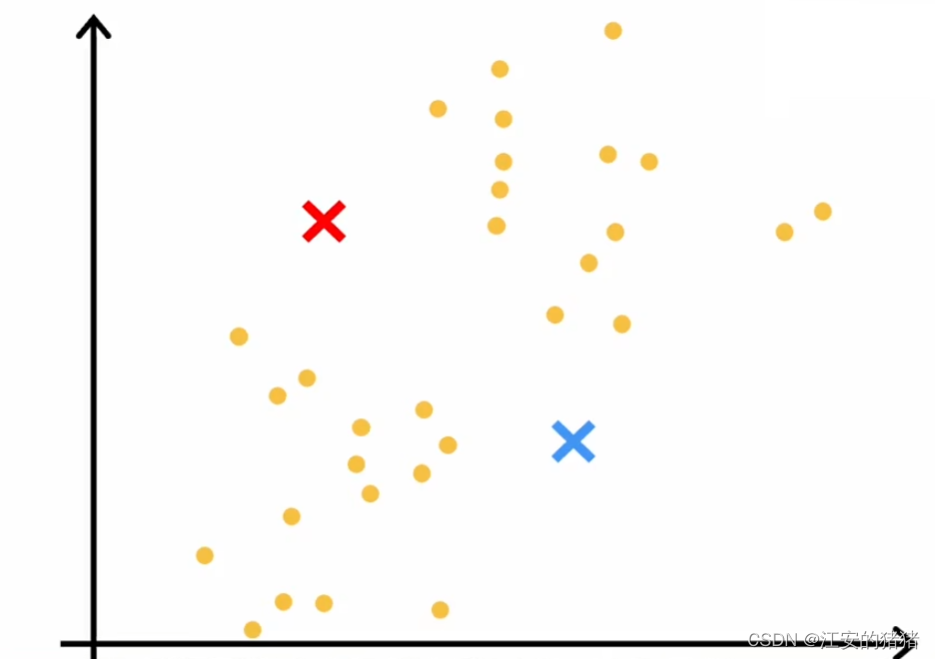
k-means算法在接下来的时间会重复做两件事情:
- 将点分配给这两个质心
- 移动簇质心
让我们看这意味着什么。
算法的第一步是随机猜测这些点的集群中心在哪里,它猜测的点叫做簇质心。在猜测完之后,算法将遍历图中所有的数据,然后计算这个数据是更接近红色or蓝色,并将它分给离它近的那个质心。这样就完成了刚刚所说的第一步。
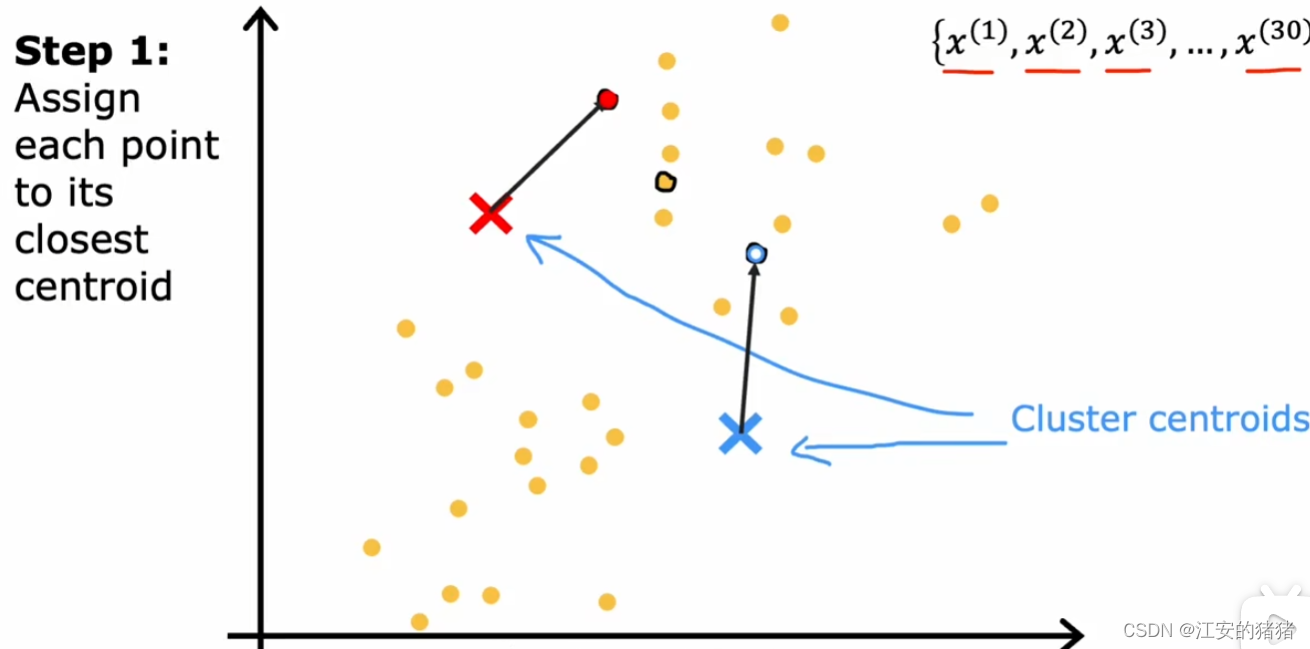
k-means的第二步是它会查看所有的红/蓝点并取平均值,并将质心移动到平均值所在位置:
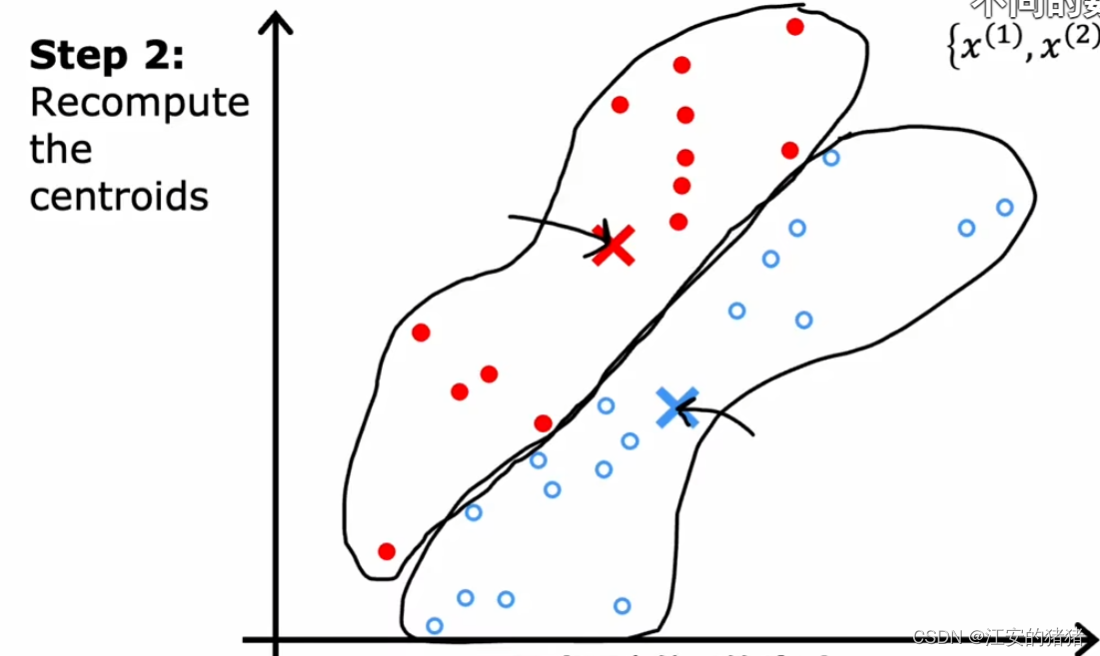
之后再重复以上步骤。
一直这样做下去之后,你会发现到某个时刻质点不再移动,此时数据就被成功地划分为两类了。

为了给读者你造成不必要的麻烦,博主的所有视频都没开仅粉丝可见,如果想要阅读我的其他博客,可以点个小小的关注哦。
















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











