






LISA简介
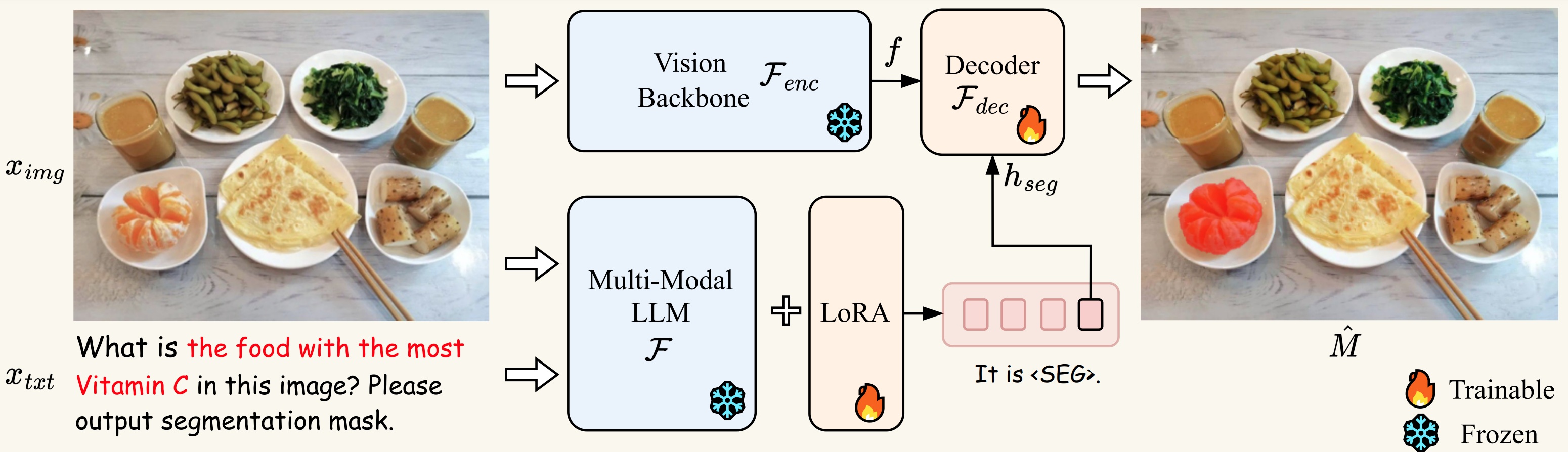
LISA(Large Language Instructed Segmentation Assistant)是由香港中文大学和商汤科技联合开发的一个创新性图像分割模型。它继承了多模态大语言模型的语言生成能力,同时又具备生成分割掩码的能力,可以处理涉及复杂推理、世界知识、解释性回答和多轮对话的图像分割任务。
LISA的核心思想是将语言理解与视觉分割相结合,通过自然语言指令来引导模型完成精确的图像分割。这种方法使得LISA能够处理传统分割模型难以应对的复杂场景,如"分割出图中能让女性站得更高的物体"或"分割出更适合拍摄近距离物体的相机镜头"等需要推理的任务。
LISA的主要特点
-
复杂推理能力: LISA可以理解并执行需要复杂推理的分割任务,如"分割出图中不寻常的部分"。
-
世界知识整合: 模型能够利用其内置的世界知识来完成任务,例如识别特定人物或物体。
-
解释性回答: LISA不仅能生成分割掩码,还能提供解释性的文字说明,阐述其分割决策的原因。
-
多轮对话支持: 模型支持多轮对话式交互,用户可以通过连续的问答来精炼分割结果。
-
零样本学习能力: 即使仅在非推理数据集上训练,LISA也展现出了强大的零样本推理分割能力。
-
微调效果显著: 在仅使用239对推理分割图像-指令对进行微调后,模型性能得到了进一步提升。
LISA的技术原理
LISA的核心架构基于多模态大语言模型(如LLaVA)和高性能图像分割模型(如SAM)的结合。它采用了以下关键技术:
-
多模态融合: 将语言理解和视觉分析能力融合在一个统一的框架中。
-
指令调优: 通过大量的图像-指令对训练,使模型能够理解并执行各种复杂的分割指令。
-
分割头设计: 在语言模型基础上增加专门的分割头,用于生成精确的像素级分割掩码。
-
推理机制: 设计了特殊的推理机制,使模型能够进行多步推理,处理复杂的分割任务。
-
知识蒸馏: 利用大语言模型的知识来增强分割模型的语义理解能力。
LISA的训练过程
LISA的训练过程包括以下几个主要步骤:
-
数据准备:
- 语义分割数据集: ADE20K, COCO-Stuff, Mapillary等
- 指代分割数据集: refCOCO, refCOCO+, refCOCOg等
- 视觉问答数据集: LLaVA-Instruct-150k
- 推理分割数据集: ReasonSeg(自建)
-
预训练模型准备:
- 语言模型: 使用LLaVA系列模型
- 视觉模型: 采用SAM ViT-H权重
-
训练流程:
deepspeed --master_port=24999 train_ds.py \ --version="PATH_TO_LLaVA" \ --dataset_dir='./dataset' \ --vision_pretrained="PATH_TO_SAM" \ --dataset="sem_seg||refer_seg||vqa||reason_seg" \ --sample_rates="9,3,3,1" \ --exp_name="lisa-7b" -
LoRA权重合并: 训练完成后,需要将LoRA权重与基础模型合并,生成完整的LISA模型。
-
验证与评估: 使用专门的验证集评估模型性能,确保模型在各种任务上都达到预期效果。
LISA的应用场景
LISA的强大能力使其在多个领域都有潜在的应用价值:
-
医疗影像分析: 可以根据医生的自然语言描述,精确分割出病变区域。
-
自动驾驶: 能够理解复杂的道路场景,分割出特定的交通元素。
-
遥感图像处理: 可以根据需求分割出特定地理特征或人造建筑。
-
工业质检: 通过自然语言指令识别产品缺陷或异常区域。
-
视频编辑: 为视频编辑软件提供智能分割功能,简化后期制作流程。
-
增强现实: 为AR应用提供更精确的场景理解和物体分割能力。
-
机器人视觉: 提升机器人对复杂环境的理解和交互能力。
LISA的实际使用
要使用LISA进行推理,可以按以下步骤操作:
-
安装必要的依赖:
pip install -r requirements.txt pip install flash-attn --no-build-isolation -
下载预训练模型:
-
运行推理脚本:
CUDA_VISIBLE_DEVICES=0 python chat.py --version='xinlai/LISA-13B-llama2-v1' -
输入文本提示和图像路径,例如:
- Please input your prompt: Where can the driver see the car speed in this image? Please output segmentation mask. - Please input the image path: imgs/example1.jpg -
LISA将生成分割掩码并提供解释性文字。
对于本地部署,可以使用以下命令启动Web界面:
CUDA_VISIBLE_DEVICES=0 python app.py --version='xinlai/LISA-13B-llama2-v1 --load_in_4bit'
LISA的未来发展
尽管LISA已经展现出了强大的能力,但研究团队仍在持续改进和扩展其功能:
-
模型规模扩展: 探索更大规模模型的潜力,以进一步提升性能。
-
多语言支持: 扩展LISA以支持更多语言的指令和回答。
-
实时处理: 优化推理速度,使LISA能够在实时应用中使用。
-
跨模态学习: 增强LISA在视频、音频等其他模态上的能力。
-
可解释性研究: 深入研究模型的决策过程,提高其可解释性。
-
领域适应: 开发针对特定领域(如医疗、地理信息系统)的专用版本。
-
与其他AI技术集成: 探索与强化学习、图神经网络等技术的结合。
结论
LISA代表了计算机视觉和自然语言处理融合的一个重要里程碑。它不仅提高了图像分割的灵活性和精度,还为人机交互提供了更自然、更直观的方式。随着技术的不断进步,我们可以期待LISA及类似模型在各个领域带来更多创新应用,推动人工智能向着更智能、更易用的方向发展。
LISA项目的开源不仅为研究人员提供了宝贵的资源,也为整个AI社区带来了新的机遇。我们鼓励更多的开发者和研究者参与到LISA的改进和应用中来,共同推动这一激动人心的技术领域的发展。
文章链接:www.dongaigc.com/a/lisa-reasoning-segmentation-helper
https://www.dongaigc.com/a/lisa-reasoning-segmentation-helper
https://www.dongaigc.com/p/dvlab-research/LISA
www.dongaigc.com/p/dvlab-research/LISA

















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









