









人工智能咨询培训老师叶梓 转载标明出处
尽管感知系统在视觉识别任务中取得了显著进展,但它们仍然依赖于人类明确指示目标对象或类别。这种系统缺乏主动推理和理解用户隐含意图的能力。为了解决这一问题,香港中文大学、SmartMore 和微软亚洲研究院的研究人员提出了一种新的分割任务——推理分割(Reasoning Segmentation),并建立了一个名为 ReasonSeg 的基准数据集,包含超过一千对图像-指令对,用于评估模型的推理和世界知识应用能力。图1展示了LISA模型在处理复杂推理和世界知识时的能力。

推理分割任务要求模型根据包含复杂推理的隐含查询文本生成二值分割掩码。与传统的引用分割任务不同,推理分割的查询文本不仅限于简单的引用,还可能包含复杂的描述或世界知识。例如,“含有高维生素C的食物”而不是简单的“橙子”。这要求模型具备两个关键能力:1)联合图像推理复杂和隐含的文本查询;2)生成分割掩码。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
Dify是一款开源的大模型应用开发平台,旨在简化和加速生成式AI应用的创建和部署。 2025年1月18日20:00-21:30(一个半小时)叶梓老师带你从零开始,动手操作,快速上手Dify,解锁大模型的无限潜能。微信视频号预约直播:sphuYAMr0pGTk27
LISA 模型
嵌入即掩码(Embedding as Mask): 大多数现有的多模态大模型(如LLaVA、Flamingo、BLIP-2和Otter)支持图像和文本输入,但只能输出文本,无法直接输出细粒度的分割掩码。VisionLLM提出了一种解决方案,通过将分割掩码解析为多边形序列,使其能够以纯文本形式表示分割掩码,并在现有的多模态大模型框架内进行端到端训练。然而,这种端到端训练方法引入了优化挑战,并且如果没有大量的数据和计算资源,可能会损害模型的泛化能力。例如,训练一个7B的VisionLLM模型需要4×8 NVIDIA 80G A100 GPU和50个周期,这在计算上是难以承受的。相比之下,训练LISA-7B只需要在8个NVIDIA 24G 3090 GPU上进行10,000步训练。
为了将新的分割能力注入多模态大模型,提出了嵌入即掩码范式。具体来说,在原始大模型词汇表中引入一个新的<SEG>令牌,表示请求分割输出。给定文本指令xtxt和输入图像ximg,将它们输入到多模态大模型F中,模型输出文本响应yˆtxt。当大模型打算生成二值分割掩码时,输出yˆtxt会包含<SEG>令牌。然后提取<SEG>令牌对应的最后一层嵌入h˜seg,并应用一个MLP投影层γ以获得hseg。同时,视觉骨干网络Fenc从视觉输入ximg中提取密集的视觉特征f。最后,hseg和f被输入到解码器Fdec中,以生成最终的分割掩码Mˆ。
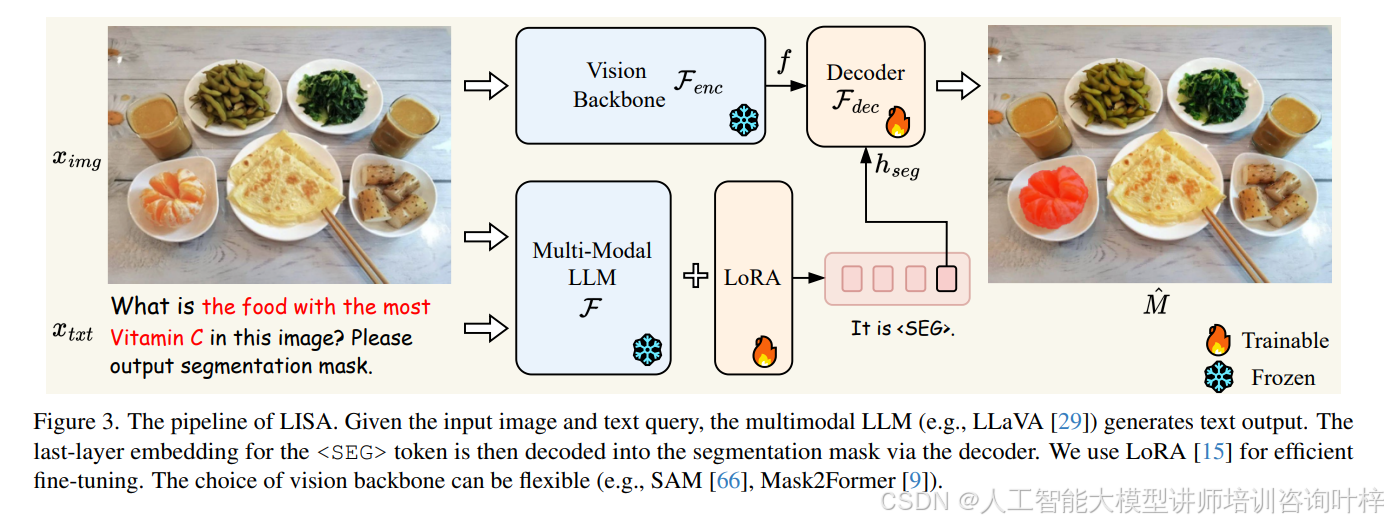
图3展示了LISA的流程。给定输入图像和文本查询,多模态大模型(例如LLaVA)生成文本输出。<SEG>令牌的最后一层嵌入随后通过解码器解码为分割掩码。为了高效微调,使用了LoRA。视觉骨干网络的选择可以是灵活的,例如SAM或Mask2Former。
训练目标: 模型通过文本生成损失Ltxt和分割掩码损失Lmask进行端到端训练。总体目标L是这两个损失的加权和,由λtxt和λmask确定。具体来说,Ltxt是文本生成的自回归交叉熵损失,Lmask是掩码损失,鼓励模型生成高质量的分割结果。为了计算Lmask,使用像素级二值交叉熵(BCE)损失和DICE损失的组合,相应的损失权重为λbce和λdice。给定真实目标ytxt和M,这些损失可以表示为:
Ltxt= 交叉熵(yˆtxt,ytxt)Lmask=λbce* BCE(Mˆ,M) +λdice* DICE(Mˆ,M)
训练数据准备: 训练数据主要包含三部分,均来自广泛使用的公共数据集。具体如下:
- 语义分割数据集:语义分割数据集通常包含图像及其对应的多类别标签。在训练过程中,为每张图像随机选择几个类别。为了生成符合视觉问答格式的数据,采用如“USER: <IMAGE> Can you segment the {class name} in this image? ASSISTANT: It is <SEG>.”的问答模板,其中
{class name}是选定的类别,<IMAGE>表示图像块的占位符。对应的二值分割掩码用作提供掩码损失监督的真实值。训练过程中还使用其他模板生成QA数据,以确保数据多样性。采用的数据集包括ADE20K、COCO-Stuff和LVIS-PACO部分分割数据集。 - 引用分割数据集:引用分割数据集提供输入图像和目标对象的明确简短描述。因此,可以使用“USER: <IMAGE> Can you segment {description} in this image? ASSISTANT: Sure, it is <SEG>.”的模板轻松将其转换为问答对,其中
{description}是给定的明确描述。采用的数据集包括refCOCO、refCOCO+、refCOCOg和refCLEF。 - 视觉问答数据集:为了保留多模态大模型原有的视觉问答能力,训练过程中也包含了视觉问答数据集。使用LLaVA-Instruct-150k数据。

图4展示了从不同类型数据中生成训练数据的方式,包括语义分割数据、引用分割数据和视觉问答(VQA)数据。
值得注意的是,上述数据集不包含任何推理分割数据样本。相反,它只包含查询文本中明确指示目标对象的样本。令人惊讶的是,即使没有复杂的推理训练数据,LISA在ReasonSeg基准测试中也表现出令人印象深刻的零样本能力。此外,通过仅在239个涉及复杂推理的数据样本上微调模型,可以进一步提升性能。
可训练参数: 为了保留预训练多模态大模型(例如LLaVA)所学到的知识,采用LoRA进行高效微调,并完全冻结视觉骨干网络Fenc。解码器Fdec则进行完全微调。此外,大模型的词嵌入(embed tokens)、大模型头部(lm head)和投影层γ也是可训练的。
实验
实验设置
网络架构: 除非另有说明,使用LLaVA-7B-v1-1或LLaVA-13B-v1-1作为基础多模态大模型F,并采用ViT-H SAM作为视觉骨干网络Fenc。投影层γ是一个MLP,通道数为[256, 4096, 4096]。
实现细节: 训练使用8个NVIDIA 24G 3090 GPU。训练脚本基于deepspeed引擎。使用AdamW优化器,学习率和权重衰减分别设置为0.0003和0。还采用WarmupDecayLR作为学习率调度器,其中warmup迭代次数设置为100。文本生成损失λtxt和掩码损失λmask的权重分别设置为1.0和1.0,BCE损失λbce和DICE损失λdice的权重分别设置为2.0和0.5。此外,每个设备的批量大小设置为2,梯度累积步数设置为10。在训练过程中,为语义分割数据集中的每张图像最多选择3个类别。
数据集: 如第4.2节所述,训练数据主要由三种类型的数据集组成:
- 语义分割数据集:使用ADE20K和COCO-Stuff。此外,为了增强对某些对象部分的分割结果,还使用了部分语义分割数据集,包括PACO-LVIS、PartImageNet和PASCAL-Part。
- 引用分割数据集:使用refCLEF、refCOCO、refCOCO+和refCOCOg。
- 视觉问答(VQA)数据集:使用LLaVA-Instruct-150k数据集(用于LLaVA v1)和LLaVA-v1.5-mix665k数据集(用于LLaVA v1.5)。为了避免数据泄露,在训练过程中排除了出现在refCOCO(+/g)验证集中的COCO样本。此外,通过仅在239个ReasonSeg数据样本上微调模型,可以进一步提升模型的性能。
评估指标: 遵循大多数引用分割工作的做法,采用两个指标:gIoU和cIoU。gIoU定义为所有每张图像的交并比(IoUs)的平均值,而cIoU定义为累积交集与累积并集的比值。由于cIoU对大面积对象高度偏向且波动过大,因此更倾向于使用gIoU。
推理分割结果
推理分割结果如表1所示。值得注意的是,现有工作无法处理该任务,但模型能够完成涉及复杂推理的任务,gIoU性能提升超过20%。如前所述,推理分割任务与引用分割任务的本质区别在于,它要求模型具备推理能力或访问世界知识。只有真正理解查询,模型才能在任务中表现出色。现有工作无法正确理解隐含查询,而我们的模型利用多模态大模型实现了这一目标。
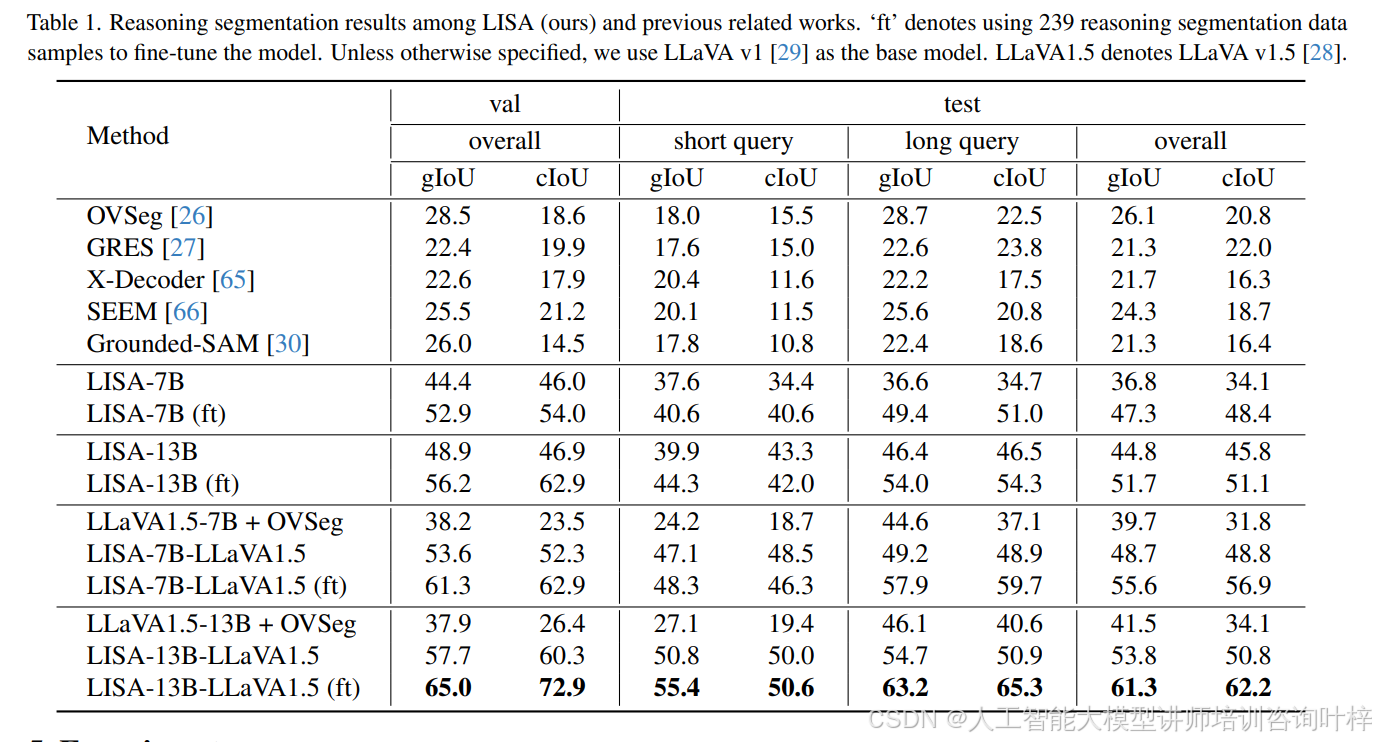
值得注意的是,我们还与传统的两阶段方法(LLaVA1.5 + OVSeg)进行了比较。具体来说,两阶段方法首先使用多模态大模型(例如LLaVA v1.5)为输入查询生成文本输出,然后采用引用或开放词汇分割模型(例如OVSeg)生成分割掩码。如果中间文本输出过长并超过OVSeg的输入标记长度限制,我们使用GPT-3.5进一步总结。更多细节可以在补充材料中找到。表1中的结果显示,模型显著优于两阶段方法。解释潜在原因如下:1)模型是端到端训练的,而两阶段方法是完全解耦的;2)两阶段方法依赖文本作为信息传递的中介,而模型利用更具表现力的隐藏嵌入。
另一个发现是,LISA-13B显著优于7B版本,尤其是在长查询场景中,这表明当前性能瓶颈可能仍然在于理解查询文本,更强的多模态大模型(例如LLaVA v1.5)可以带来更好的结果。
传统引用分割结果
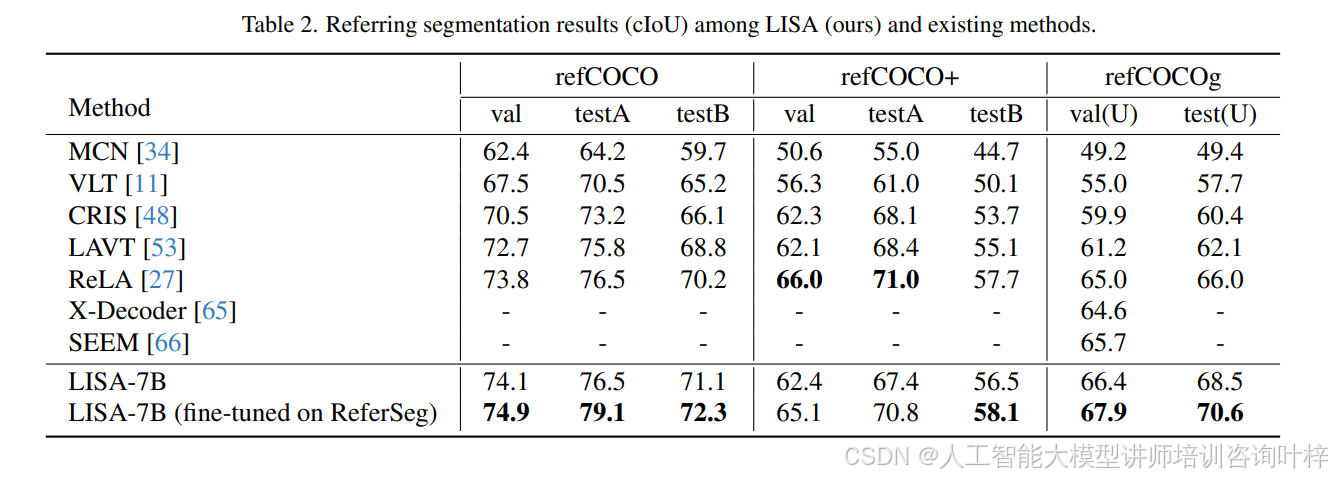
为了证明模型在传统引用分割任务中也表现出色,在表2中与现有最先进的方法进行了比较。在refCOCO、refCOCO+和refCOCOg的验证和测试集上评估了这些方法。模型在各种引用分割基准测试中均取得了最先进的结果。
消融研究
进行了广泛的消融研究,以揭示每个组件的贡献。除非另有说明,报告的是LISA-7B在验证集上的gIoU和cIoU指标。
视觉骨干网络的设计选择: 特别强调,除了SAM之外,其他视觉骨干网络也适用于本的框架。在表3中,我们注意到SAM表现最佳,这可能是因为其预训练阶段使用了大量高质量的数据。此外,还发现,即使使用Mask2Former骨干网络,本框架在推理分割任务上仍然表现出色,显著优于先前的作品,如X-Decoder。这表明视觉骨干网络的设计选择是灵活的,不仅限于SAM。
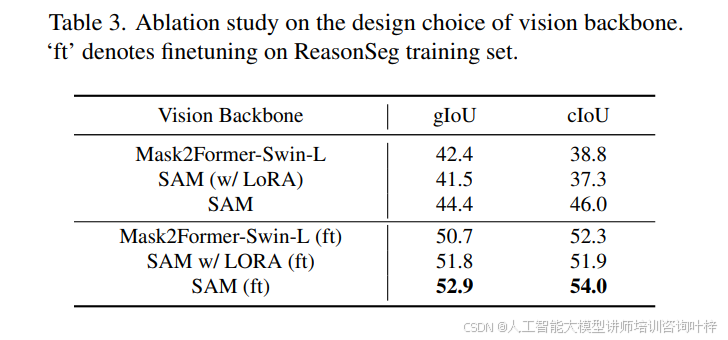
SAM LoRA微调: 还研究了在SAM骨干网络上应用LoRA的效果。在表3中,我们注意到LoRA微调的SAM骨干网络的性能劣于冻结的SAM骨干网络。一个可能的原因是微调损害了原始SAM模型的泛化能力。
SAM预训练权重: 为了证明SAM预训练权重的贡献,在表4中比较了实验1和实验3。如果没有使用SAM预训练权重,视觉骨干网络将从头开始训练。这导致性能大幅落后于基线模型。
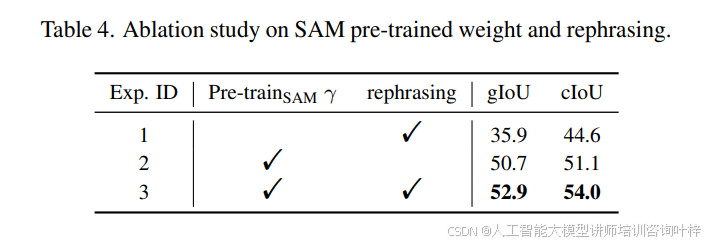
GPT-3.5指令重述: 在对推理分割数据样本进行微调时,使用GPT-3.5重述文本指令(具体细节在补充材料中展示),并随机选择一个。表4中实验2和实验3的比较显示,性能在gIoU上提高了2.2%,在cIoU上提高了2.9%。这一结果验证了这种数据增强的有效性。
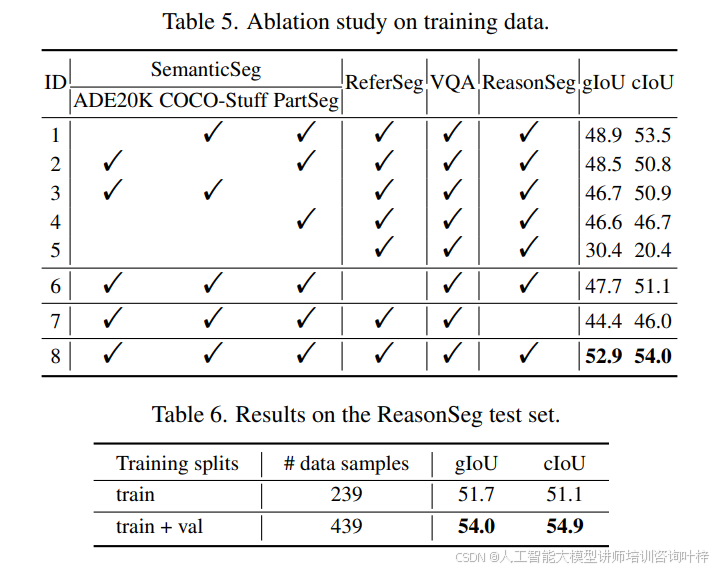
所有类型训练数据的贡献: 在表5中,展示了每种类型数据对性能的贡献。我们发现,在实验5中,没有使用任何语义分割数据集,性能大幅下降。我们推测,语义分割数据集为训练提供了大量的真实二值掩码,因为一个多类别标签可以诱导多个二值掩码。还注意到,在训练过程中添加更多的推理分割数据样本可以带来更好的结果。在表6中,在微调过程中还添加了ReasonSeg验证集(200个数据样本),这在gIoU和cIoU指标上都带来了更好的性能。这表明,更多的推理分割训练样本在当前阶段是有益的。
定性结果
如图5所示,提供了与现有相关作品的视觉比较,包括开放词汇语义分割模型(OVSeg)、引用分割模型(GRES)和通用分割模型(X-Decoder和SEEM)。这些模型在处理显示的案例时出现了各种错误,而本方法产生了准确且高质量的分割结果。

代码、模型和演示可在 https://github.com/dvlab-research/LISA 获取。



















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











