






本文主要关于多元线性回归(MSE)与L1,L2范数结合在一起从而提高鲁棒性,即正则化应用于MSE产生的Ridge,Lasso,Elasticnet回归的内容。
一,Ridge回归
岭回归实质上就是普通的MSE加上一项L2惩罚项来提高模型的鲁棒性,但同时也会降低一定的准确率。
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.linear_model import SGDRegressor
X = 2*np.random.rand(100,1)
y = 4 + 3*X + np.random.randn(100,1)
rm = Ridge(alpha=0.4,solver='sag')#alpha调大,提高泛化能力,准度降低,alpha调小,泛化能力减弱,准度提高
rm.fit(X,y)
print("Ridge:")
print("predict:",rm.predict([[1.5]]))
print("w1:",rm.coef_)
print("bias:",rm.intercept_)
print("----------------"*10)
print("SGD:")
sr = SGDRegressor(penalty='l2',max_iter=1000)
sr.fit(X,y.reshape(-1,))
print("predict:",sr.predict([[1.5]]))
print("w1:",sr.coef_)
print("bias:",sr.intercept_)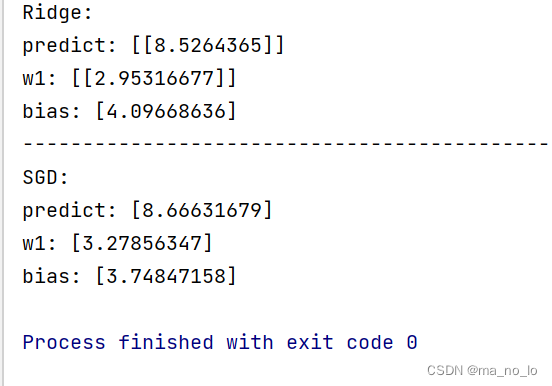
上图为α值为0.4时产生的结果,当提高α值(即提高正则化力度),我们会发现准确度下降(如下图)。
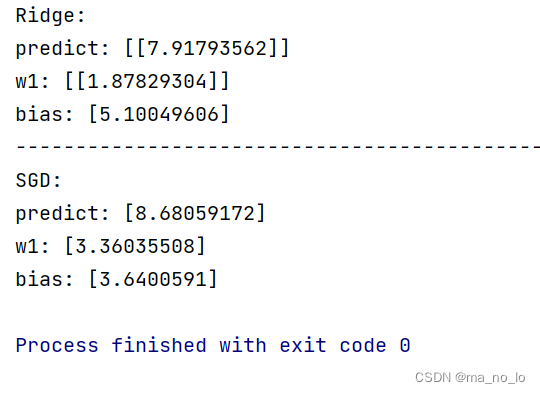
二,Lasso回归
Lasso回归的损失函数包含MSE和L1范数两部分,符合正则化特点地,提高正则化力度的同时,准确值下降。
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.linear_model import SGDRegressor
X = 2*np.random.rand(100,1)
y = 4 + 3*X + np.random.randn(100,1)
lm = Lasso(alpha=0.15,max_iter=30000)
lm.fit(X,y)
print("Lasso:")
print("w1:",lm.coef_)
print("bias:",lm.intercept_)
print("predict:",lm.predict([[1.5]]))
print("----------------"*10)
print("SGD:")
sr = SGDRegressor(penalty='l1',max_iter=10000)
sr.fit(X,y.reshape(-1,))
print("w1:",sr.coef_)
print("bias:",sr.intercept_)
print("predict:",sr.predict([[1.5]]))
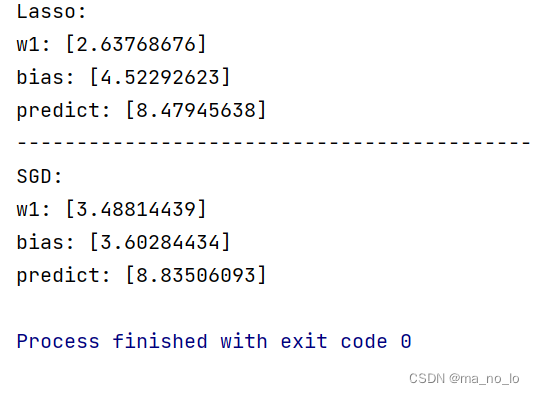
当α为0.15时产生的结果,当提高α值,观察下图,我们发现L1范数对α更加敏感,当α大于1.2后w1归零,这里我们使用α=0.7观察现象。

三,Elasticnet回归
观察其损失函数,不难发现Elasticnet回归实质上就是由MSE,L1,L2三部分组成,p决定我们更注重哪种范数来正则化。
import numpy as np
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import SGDRegressor
X = 2*np.random.rand(100,1)
y = 4 + 3*X + np.random.randn(100,1)
er = ElasticNet(alpha=0.04,l1_ratio=0.1,)
er.fit(X,y)
print("ElasticNet:")
print("bias:",er.intercept_)
print("w1:",er.coef_)
print("predict:",er.predict([[1.5]]))
print("----------------"*10)
print("SGD:")
sr = SGDRegressor(penalty="elasticnet",max_iter=1000)
sr.fit(X,y.reshape(-1,))
print("bias:",sr.intercept_)
print("w1:",sr.coef_)
print("predict:",sr.predict([[1.5]]))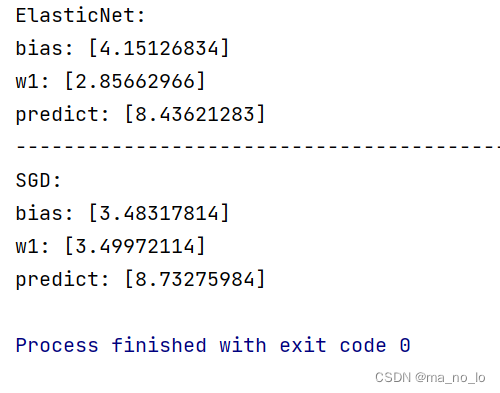
我们可以通过调整α来调整整体正则化力度,调整l1_ratio来调整正则化侧重,这样可以更好的规范损失函数。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









