







1. 代码部分
此代码块为train_model.py内的代码
# USAGE
# python train_model.py --embeddings output/embeddings.pickle \
# --recognizer output/recognizer.pickle --le output/le.pickle
# 加载必要的包
# 在提取的128维面部嵌入的基础上训练“标准”机器学习分类器(SVM,SGD分类器,随机森林等)
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
import pickle
def train_model():
## 加载序列化面部嵌入(serialized face embeddings )
print("[INFO] loading face embeddings...")
# 在此脚本文件中,使用函数extract_embeddings()提取的面部嵌入
data = pickle.loads(open(r'output/embeddings.pickle', "rb").read())
## 给标签编码
## 将人名作为标签存储到磁盘中
print("[INFO] encoding labels...")
# 初始化scikit-learn的标签编码器(LabelEncoder)
le = LabelEncoder()
# 编码人名的标签(这一步运行完之后,标签编码器便和data字典中的names关联起来了)
labels = le.fit_transform(data["names"])
## 训练用于识别人脸的线性支持向量机(SVM)模型
## 训练用于接收面部嵌入的模型,即人脸识别模型(recognizer model)
print("[INFO] training model...")
# 初始化SVM模型(可选用的核函数:rbf(径向基核,也就是高斯核函数),linear(线性核函数))
recognizer = SVC(C=1.0, kernel="linear", probability=True)
# 拟合模型(训练模型)
recognizer.fit(data["embeddings"], labels)
## 将标签编码器写入磁盘
f = open(r'output/le.pickle', "wb")
f.write(pickle.dumps(le))
f.close()
## 将人脸识别模型写入磁盘
f = open(r'output/recognizer.pickle', "wb")
f.write(pickle.dumps(recognizer))
f.close()
## 测试脚本用
if __name__ == '__main__':
train_model()
2. 函数结构说明

3. 程序流程图
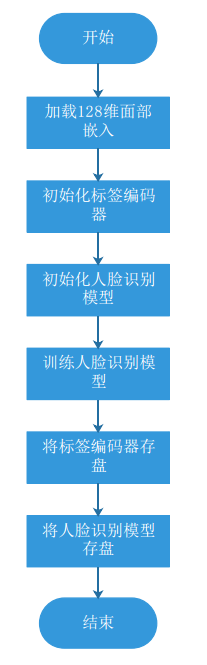
4. 函数图解



5. 使用说明
本函数需搭配视频流人脸识别系统一起使用。
视频流人脸识别系统的系统函数见此博客:一、视频流人脸识别系统的系统函数的构建(Python)
















 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











