







课程地址:https://class.coursera.org/ntumlone-001/class
课件讲义:http://download.csdn.net/download/malele4th/10212756
注明:文中图片来自《机器学习技法》课程和部分博客
建议:建议读者学习林轩田老师原课程,本文对原课程有自己的改动和理解
Lecture 12 Neural Network
上节课我们主要介绍了Gradient Boosted Decision Tree。GBDT通过使用functional gradient的方法得到一棵一棵不同的树,然后再使用steepest descent的方式给予每棵树不同的权重,最后可以用来处理任何而定error measure。上节课介绍的GBDT是以regression为例进行介绍的,使用的是squared error measure。本节课讲介绍一种出现时间较早,但当下又非常火的一种机器算法模型,就是神经网络(Neural Network)。
目录
1 Motivation
在之前的机器学习基石课程中,我们就接触过Perceptron模型了,例如PLA算法。Perceptron就是在矩gt(x)外面加上一个sign函数,取值为{-1,+1}。现在,如果把许多perceptrons线性组合起来,得到的模型G就如下图所示:
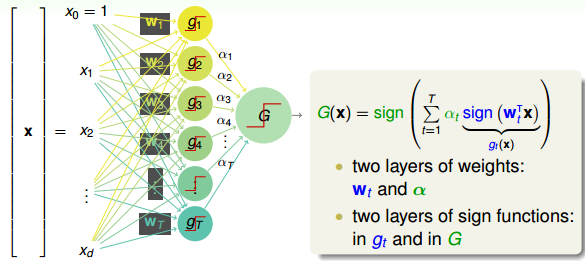
所以说,linear aggregation of perceptrons实际上是非常powerful的模型同时也是非常complicated模型。再看下面一个例子,如果二维平面上有个圆形区域,圆内表示+1,圆外表示-1。这样复杂的圆形边界是没有办法使用单一perceptron来解决的。如果使用8个perceptrons,用刚才的方法线性组合起来,能够得到一个很接近圆形的边界(八边形)。如果使用16个perceptrons,那么得到的边界更接近圆形(十六边形)。因此,使用的perceptrons越多,就能得到各种任意的convex set,即凸多边形边界。之前我们在机器学习基石中介绍过,convex set的VC Dimension趋向于无穷大(
2N
2
N
)。这表示只要perceptrons够多,我们能得到任意可能的情况,可能的模型。但是,这样的坏处是模型复杂度可能会变得很大,从而造成过拟合(overfitting)。
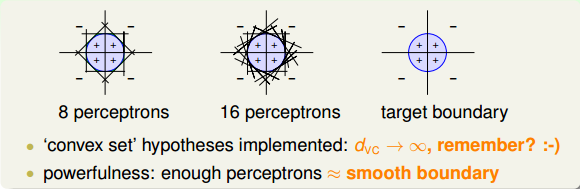
总的来说,足够数目的perceptrons线性组合能够得到比较平滑的边界和稳定的模型,这也是aggregation的特点之一。
2 Neural Network Hypothesis
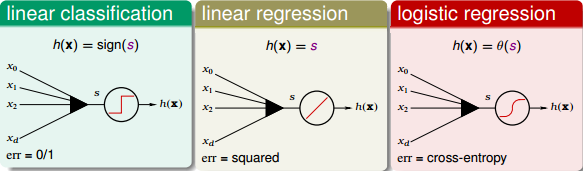
我们之前已经介绍过三种线性模型:linear classification,linear regression,logistic regression。那么,对于OUTPUT层的分数s,根据具体问题,可以选择最合适的线性模型。如果是binary classification问题,可以选择linear classification模型;如果是linear regression问题,可以选择linear regression模型;如果是soft classification问题,则可以选择logistic regression模型。本节课接下来将以linear regression为例,选择squared error来进行衡量。
介绍完Neural Network Hypothesis的结构之后,我们来研究下这种算法结构到底有什么实际的物理意义。还是看上面的神经网络结构图,每一层输入到输出的运算过程,实际上都是一种transformation,而转换的关键在于每个权重值 w(l)ij w i j ( l ) 。每层网络利用输入x和权重w的乘积,在经过tanh函数,得到该层的输出,从左到右,一层一层地进行。其中,很明显,x和w的乘积 ∑d(l−1)i=0w(l)ijx(l−1)i ∑ i = 0 d ( l − 1 ) w i j ( l ) x i ( l − 1 ) 越大,那么tanh(wx)就会越接近1,表明这种transformation效果越好。再想一下,w和x是两个向量,乘积越大,表明两个向量内积越大,越接近平行,则表明w和x有模式上的相似性。从而,更进一步说明了如果每一层的输入向量x和权重向量w具有模式上的相似性,比较接近平行,那么transformation的效果就比较好,就能得到表现良好的神经网络模型。也就是说,神经网络训练的核心就是pattern extraction,即从数据中找到数据本身蕴含的模式和规律。通过一层一层找到这些模式,找到与输入向量x最契合的权重向量w,最后再由G输出结果。
3 Neural Network Learning
神经网络中,这种从后往前的推导方法称为Backpropagation Algorithm,即我们常常听到的BP神经网络算法

4 Optimization and Regularization
下面我们将主要分析神经网络的优化问题。由于神经网络由输入层、多个隐藏层、输出层构成,结构是比较复杂的非线性模型,因此 Ein(w) E i n ( w ) 可能有许多局部最小值,是non-convex的,找到全局最小值(globalminimum)就会困难许多。而我们使用GD或SGD算法得到的很可能就是局部最小值(local minimum)。
基于这个问题,不同的初始值权重w(l)ij通常会得到不同的local minimum。也就是说最终的输出G与初始权重w(l)ij有很大的关系。在选取w(l)ij上有个技巧,就是通常选择比较小的值,而且最好是随机random选择。这是因为,如果权重w(l)ij很大,那么根据tanh函数,得到的值会分布在两侧比较平缓的位置(类似于饱和saturation),这时候梯度很小,每次迭代权重可能只有微弱的变化,很难在全局上快速得到最优解。而随机选择的原因是通常对权重w(l)ij如何选择没有先验经验,只能通过random,从普遍概率上选择初始值,随机性避免了人为因素的干预,可以说更有可能经过迭代优化得到全局最优解。

防止过拟合:L2正则化

除了weight-elimination regularizer之外,还有另外一个很有效的regularization的方法,就是Early Stopping。简而言之,就是神经网络训练的次数t不能太多。因为,t太大的时候,相当于给模型寻找最优值更多的可能性,模型更复杂,VC Dimension增大,可能会overfitting。而t不太大时,能有效减少VC Dimension,降低模型复杂度,从而起到regularization的效果。Ein和Etest随训练次数t的关系如下图右下角所示:
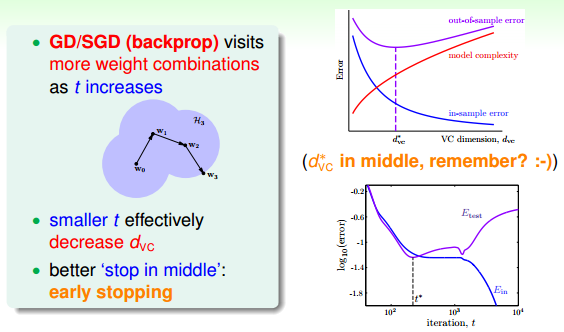
那么,如何选择最佳的训练次数t呢?可以使用validation进行验证选择。
5 总结
本节课主要介绍了Neural Network模型。首先,我们通过使用一层甚至多层的perceptrons来获得更复杂的非线性模型。神经网络的每个神经元都相当于一个Neural Network Hypothesis,训练的本质就是在每一层网络上进行pattern extraction,找到最合适的权重 w(l)ij w i j ( l ) ,最终得到最佳的G。本课程以regression模型为例,最终的G是线性模型,而中间各层均采用tanh函数作为transform function。计算权重 w(l)ij w i j ( l ) 的方法就是采用GD或者SGD,通过Backpropagation算法,不断更新优化权重值,最终使得 Ein(w) E i n ( w ) 最小化,即完成了整个神经网络的训练过程。最后,我们提到了神经网络的可以使用一些regularization来防止模型过拟合。这些方法包括随机选择较小的权重初始值,使用weight-elimination regularizer或者early stopping等。















 3907
3907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









