









paper:《Self-Adaptive Proposal Model for Temporal Action Detection based on Reinforcement Learning》
背景
1.任务描述:本paper用于视频行为检测任务,对于给定的视频,检测出视频中的可能产生运动的片段和行动的类别,传统的针对这一任务,我们常常分成两步的来解决:
[1].对于原始视频提取可能的产生动作的proposal片段。
[2].利用提取出的大量的proposal片段,判断出其中行为对应的类别。

本论文的数据集是针对于THUMOS2014 挑战赛,训练集会给予大量的视频,并给出这些视频的真实类别和对应片段时间的定位。
2.对于给定的视频,我们很重要的任务是先定位到合适的proposal集位置,我们称正确的、标记好的位置为Gound Truth。

3.对于proposal的检测,涉及到两个问题:proposal位置的任意性和检测窗口大小的不定性,通常的方法是对于要检测的片段设定不同尺寸的检测窗口大小,但是这样需要多次的使用不同的检测窗口走从前向后的循环,因此生成proposal的速度会比较慢。 对于上面的问题,我们期望有好的方式,能够:
[1].只需要一次对整个视频的遍历,就可以生成所有的proposal片段
[2].可以自适应的调节proposal尺寸的大小,不需要死板的设定固定的尺寸。
针对于以上的期待,我们引入强化学习的方式来较好、且快的生成合适的proposal集合。
任务转换
1.进行任务的转化,我们设定生成一个proposal的过程为一个马尔科夫决策过程。 这样的MDP过程可为如下的形式:
检测框左移 -> 检测框收缩 -> 检测框放大…….->启动生成proposal
2.对应的上面的马尔科夫决策过程,我们可以进行如下的问题转化:
[1]智能体(agent): 移动框决策者。
[2]状态(state):检测框看到的图像、前几次移动的历史记录
[3]行为(action):对检测框的位置调整,调整行为包括左移、右移、左扩展...等
[4]奖励(reward):我们设定对于不同的行为有不同的奖励模式,但主要以IOU(当前窗口和正确ground truth窗口的重合面积)作为奖励依据。
[5]策略(policy):从随机起点的位置开始,MDP序列会在提交一次proposal为止,行走到提交位置就称之一个策略。

3.以上完成了转换定义过程,现在对动作、状态、奖励进行详细定义。
[1]对于动作,我们定义8个可选的动作,这8个动作分别是右移、左移、右扩展、左扩展、缩小、不规则跳跃、结束此本搜索触发器,下面的白框是动作前的、黄框是移动后的位置。

这里的跳跃是不规则移动,在训练时,我们会移动到一个IOU不为0的位置区域,在测试时我们会朝前进方向forward移动两次(训练和测试过程有较大差别、会分别介绍)
[2]对于状态,我们设定其为二元组合形式,包括两部分,分别是观测窗口看到的图像(帧长度不定)和历史动作向量,历史维度为28维(4*7),表示过去4步的动作。

[3]对于奖励,我们根据不同行为的特点设定不同的反馈奖励,可以分为三种情况,第一种情况是对于触发器行为,我们设计的奖励函数式如下,开始时设定了最低IOU保障(例0.5),如果选择trigger动作,且触发时IOU大于阈值,就给予大奖励+3,如果小于阈值,说明trigger触发的不好,就给予强惩罚。
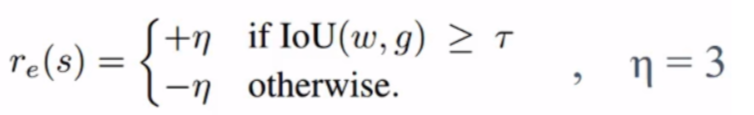
对于跳跃动作jump,我们的意图是当窗口和ground truth无交集时就执行jump,跳跃到其他位置,这是因为往往视频中ground truth位置是非常稀疏的,所以我们需要在当前IOU为0时启动跳跃, 这里是启动跳跃的位置IOU为0,也就是该启动跳跃时,令奖励为+1,如果IOU不为0,说明在不该 跳跃位置跳跃则给予-1。
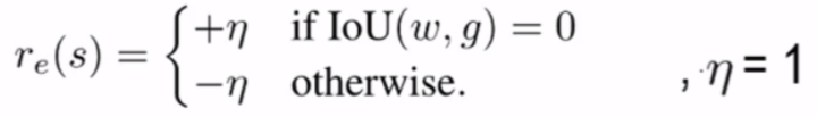
此外,对于其他的6种操作,我们同一使用如下的奖励函数,以动作后的IOU变化情况作为奖励函数依据,如果进行移动后新的窗口w'与ground truth重合有提升则给予正奖励,否则给予负的奖励。
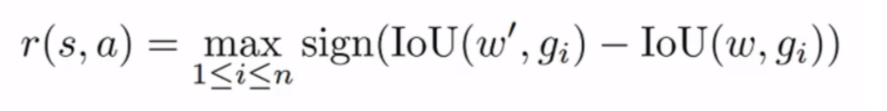
通过以上过程,完成了基本建模,接下来开始搭建网络和训练。
模型
1.我们搭建了如下的模型,用于输入状态,输出每个行为的Q值,用于选择最佳的行为。

主要包括三部分:
[1]第一部分使用预训练好的C3D模型+temporal pooling层做特征提取,其中C3D是做动作检测最常用的模型,我们这里使用在Sports-1M数据集训练和在UCF-101数据集上微调的C3D模型作为基本提取特征的模型。但是因为C3D模型的输入必须是固定的,而我们的观测窗口的帧数是不定的,所以这里会在C3D第五层卷积层之后添加一个temporal pooling层,会在厚度上进行池化,缩减成厚底为16,实现厚度的统一。


[2]第二部分是训练一个DQN网络,通过输入提取出的4096维特征外加历史行为记录,经过四层全连接输出7个行为的Q值,通过计算Q估计和Q现实值计算损失对DQN网络进行训练,在一个状态下选择最佳的行为。

[3]第三部分是训练位置修正网络,网络的输入是提取出的4096维特征,输出距离靠近的ground truth的起点和终点的坐标偏移量(帧差距),根据预测偏移量和真实偏移量计算损失值、训练模型,预测出距离最近的偏移距离,使用这样的预测在协助我们更好的提取proposal。

![]()
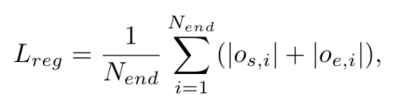
以上已经定义好网络结构,接下来我们分别对训练过程和测试过程进行讲解。
训练
在进行训练,对于每个视频执行rounds步,如下图的过程。
[1].初始随机设定滑窗位置,设定滑窗大小为当前视频中ground truth中片段平均长度。
[2]在每个round内,设定最大探索次数为max_step次,且无中途停止条件:
*如果当前位置IOU值为0,则直接执行jump动作(强启发性,跳转给奖励,而不用随机跳),跳转到一个随机的跟ground truth有重合的位置。
*如果当前位置IOU大于一个触发阈值,则直接执行触发动作,记录行为记忆,同时为了保证放置agent错过更高IOU的位置,我们同时根据ε-greedy policy执行非触发动作,进行行走,并保存记忆。
*对于其他情况,根据ε-greedy policy(1-ε概率利用Q网络选最佳动作)选择动作,并进行记忆的保存。 可以发现并没有流程内的截止条件,会生成多个trigger触发行为记忆,使用了大量的启发式,并且对RL的本质了解的很透彻(有效记忆引导)。

上面的训练过程,可以积累很多的动作记忆,在积攒记忆过程中,我们也类似充电汽车算法中的过程,不断取一批次记忆训练DQN网络。接下来讲述下测试过程,测试阶段对于一个视频,会不断从视频开始走到视频结束,执行trigger动作就提取proposal。
测试
1.对于每个视频的proposal集提取,执行的步骤如下:
[1]从视频的起点开始,滑窗长度为之前ground truth的平均长度。
[2]从起点开始不断往后,直到走到视频终点,生成每个proposal过程如下:
*将当前状态输入DQN网络,输出对应行为的Q值,如果jump的Q值最大就朝着视频结束移动两次,如果trigger的Q值最大就生成本次proposal,结束本次探索,如果是其他动作,就按动作执行。
*当生成出proposal后,我们下一步的生成proposal的终止位置作为其实位置下一个proposal的探索。 可以发现对于视频生成proposal的数量是不定的。

可以发现对于视频生成proposal的数量是不定的。
2.下面是预测过程的图示,初始从起点开始,遇到选jump就往右走,遇到trigger就提交,提交后可以继续往后走。 绿色是正确决策,红叉是错误决策。

3.以上完成了训练和预测过程, 后讲过效果验证主要考虑两方面:
[1]提取proposal的质量(用proposal的recall值作为衡量,也就是提取的proposal集对真实ground truth的覆盖率)。 [2]使用提取出的proposal拿来做动作行为分类的效果(使用proposal做分类的准确路,使用PR指标计算AP曲线下的面积)。
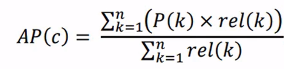

4.对于检测proposal质量方面,可以发现伴随这proposals的生成数量增加,我们的SAP算法在100个之前效果是Recall得分是非常高的,在之后就不如其他算法,这是因为SAP算法proposal较为精简,冗余小



5.在分类效果方面,对于不同类别的动作分类,SAP算法相比于常见的模型有更好的AP精度得分。
















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









