






新建环境
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 的环境:
# pytorch 2.0.1 py3.10_cuda11.7_cudnn8.5.0_0
studio-conda xtuner0.1.17
# 如果你是在其他平台:
# conda create --name xtuner0.1.17 python=3.10 -y
# 激活环境
conda activate xtuner0.1.17
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir -p /root/xtuner0117 && cd /root/xtuner0117
# 拉取 0.1.17 的版本源码
git clone -b v0.1.17 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.15 https://gitee.com/Internlm/xtuner
# 进入源码目录
cd /root/xtuner0117/xtuner
# 从源码安装 XTuner
pip install -e '.[all]'
1 创建文件夹保存数据
# 前半部分是创建一个文件夹,后半部分是进入该文件夹。
mkdir -p /root/ft && cd /root/ft
# 在ft这个文件夹里再创建一个存放数据的data文件夹
mkdir -p /root/ft/data && cd /root/ft/data
# 创建 `generate_data.py` 文件
touch /root/ft/data/generate_data.py
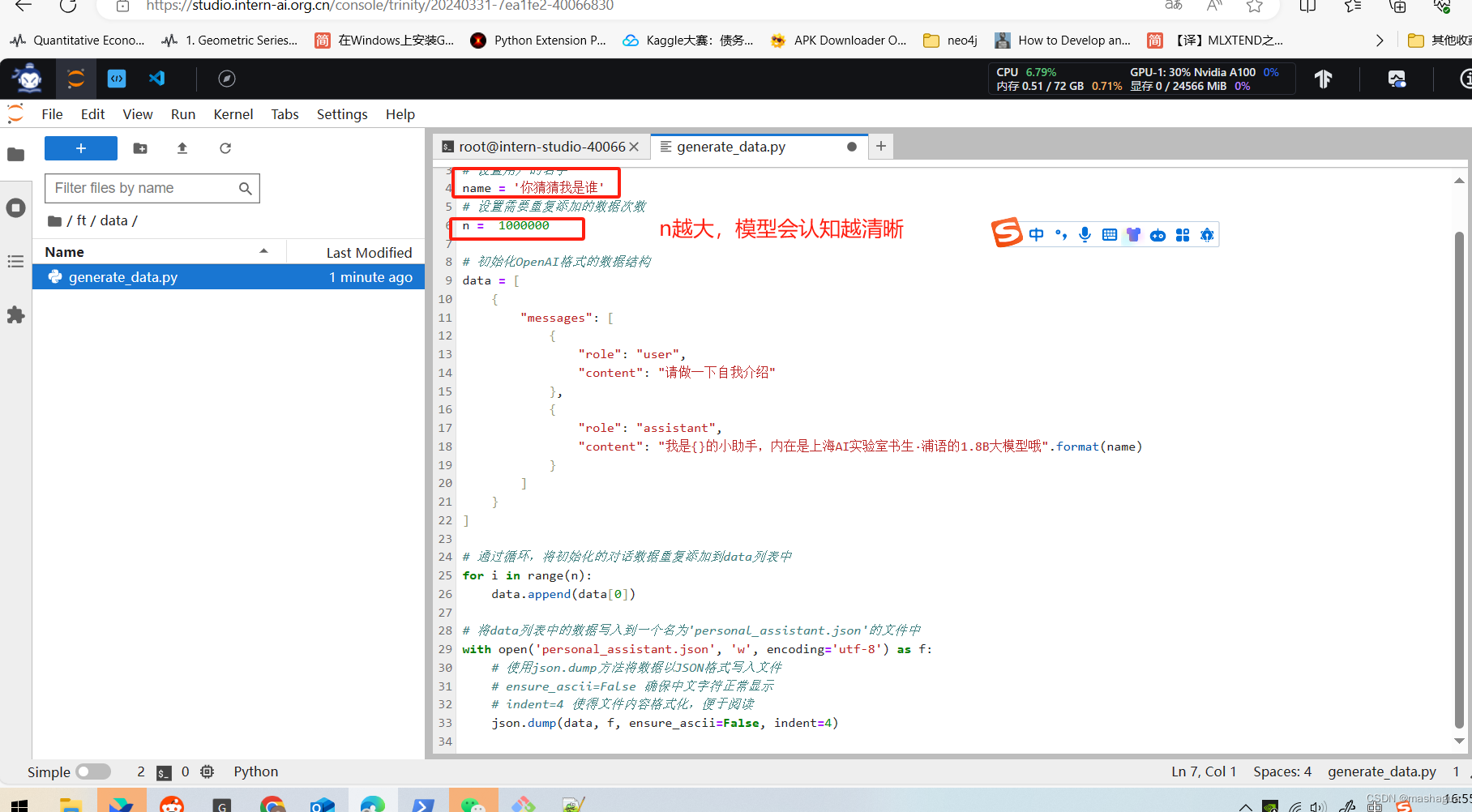
import json
# 设置用户的名字
name = '猜猜我是谁'
# 设置需要重复添加的数据次数
n = 1000000
# 初始化OpenAI格式的数据结构
data = [
{
"messages": [
{
"role": "user",
"content": "请做一下自我介绍"
},
{
"role": "assistant",
"content": "我是{}的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦".format(name)
}
]
}
]
# 通过循环,将初始化的对话数据重复添加到data列表中
for i in range(n):
data.append(data[0])
# 将data列表中的数据写入到一个名为'personal_assistant.json'的文件中
with open('personal_assistant.json', 'w', encoding='utf-8') as f:
# 使用json.dump方法将数据以JSON格式写入文件
# ensure_ascii=False 确保中文字符正常显示
# indent=4 使得文件内容格式化,便于阅读
json.dump(data, f, ensure_ascii=False, indent=4)
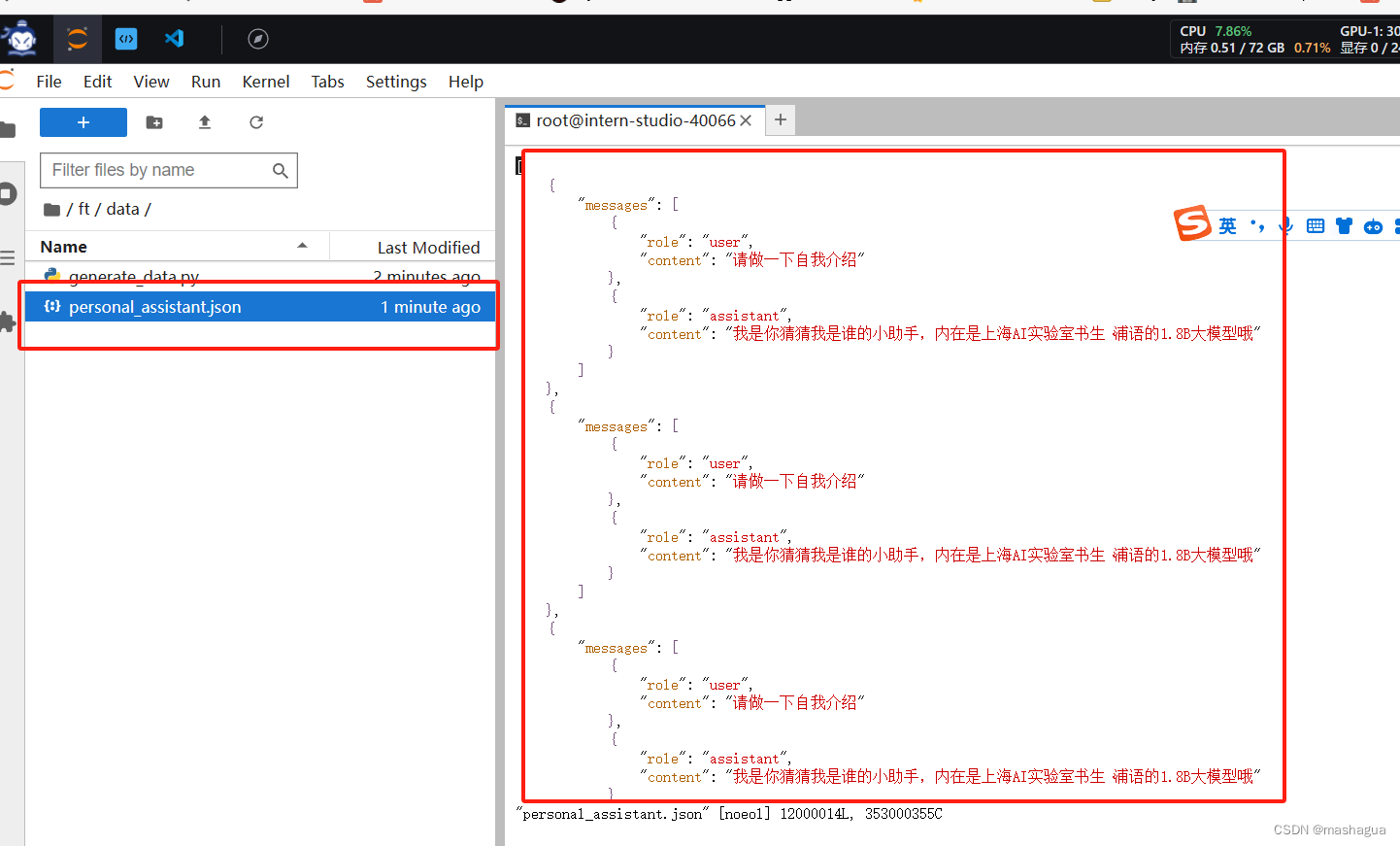
运行代码
python /root/ft/data/generate_data.py,生成对应的语料文件
# 创建目标文件夹,确保它存在。
mkdir -p /root/ft/model
# 复制内容到目标文件夹。-r选项表示递归复制整个文件夹。
cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/* /root/ft/model/
当然如果空间不大的话,也可使用软链接的方式 ln -s
# copy对应的config文件
# 创建一个存放 config 文件的文件夹
mkdir -p /root/ft/config
# 使用 XTuner 中的 copy-cfg 功能将 config 文件复制到指定的位置
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config
# 修改模型地址(在第27行的位置)
- pretrained_model_name_or_path = 'internlm/internlm2-1_8b'
+ pretrained_model_name_or_path = '/root/ft/model'
# 修改数据集地址为本地的json文件地址(在第31行的位置)
- alpaca_en_path = 'tatsu-lab/alpaca'
+ alpaca_en_path = '/root/ft/data/personal_assistant.json'
除此之外,我们还可以对一些重要的参数进行调整,包括学习率(lr)、训练的轮数(max_epochs)等等。由于我们这次只是一个简单的让模型知道自己的身份弟位,因此我们的训练轮数以及单条数据最大的 Token 数(max_length)都可以不用那么大。
# 修改max_length来降低显存的消耗(在第33行的位置)
- max_length = 2048
+ max_length = 1024
# 减少训练的轮数(在第44行的位置)
- max_epochs = 3
+ max_epochs = 2
# 增加保存权重文件的总数(在第54行的位置)
- save_total_limit = 2
+ save_total_limit = 3
另外,为了训练过程中能够实时观察到模型的变化情况,XTuner 也是贴心的推出了一个 evaluation_inputs 的参数来让我们能够设置多个问题来确保模型在训练过程中的变化是朝着我们想要的方向前进的。比如说我们这里是希望在问出 “请你介绍一下你自己” 或者说 “你是谁” 的时候,模型能够给你的回复是 “我是XXX的小助手...” 这样的回复。因此我们也可以根据这个需求进行更改。
# 修改每多少轮进行一次评估(在第57行的位置)
- evaluation_freq = 500
+ evaluation_freq = 300
# 修改具体评估的问题(在第59到61行的位置)
# 可以自由拓展其他问题
- evaluation_inputs = ['请给我介绍五个上海的景点', 'Please tell me five scenic spots in Shanghai']
+ evaluation_inputs = ['请你介绍一下你自己', '你是谁', '你是我的小助手吗']
这样修改完后在评估过程中就会显示在当前的权重文件下模型对这几个问题的回复了。
由于我们的数据集不再是原本的 aplaca 数据集,因此我们也要进入 PART 3 的部分对相关的内容进行修改。包括说我们数据集输入的不是一个文件夹而是一个单纯的 json 文件以及我们的数据集格式要求改为我们最通用的 OpenAI 数据集格式。
# 把 OpenAI 格式的 map_fn 载入进来(在第15行的位置)
- from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
+ from xtuner.dataset.map_fns import openai_map_fn, template_map_fn_factory
# 将原本是 alpaca 的地址改为是 json 文件的地址(在第102行的位置)
- dataset=dict(type=load_dataset, path=alpaca_en_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path)),
# 将 dataset_map_fn 改为通用的 OpenAI 数据集格式(在第105行的位置)
- dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=openai_map_fn,
# 训练模型并指定保存路径
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train
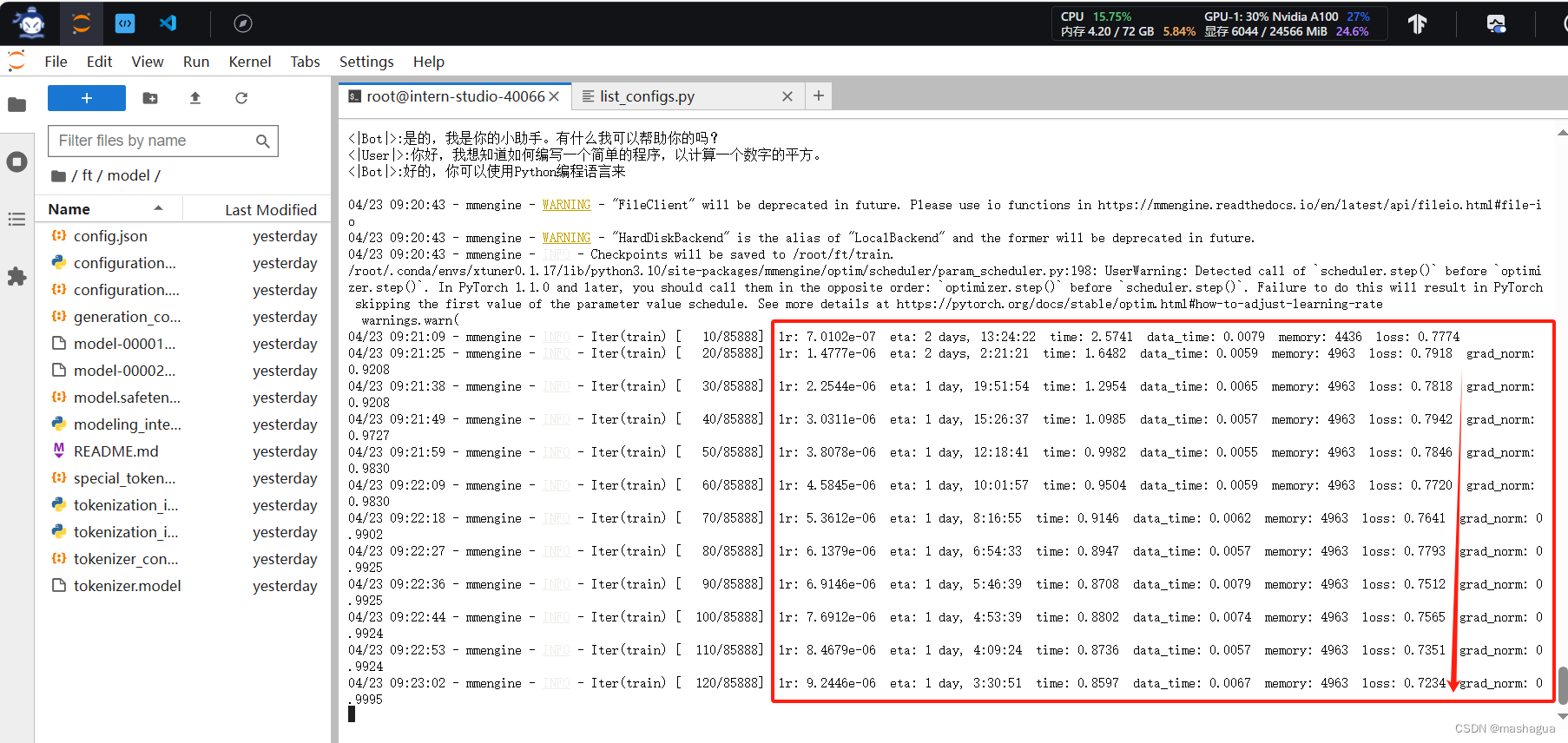
程序启动,打印一些必要的信息
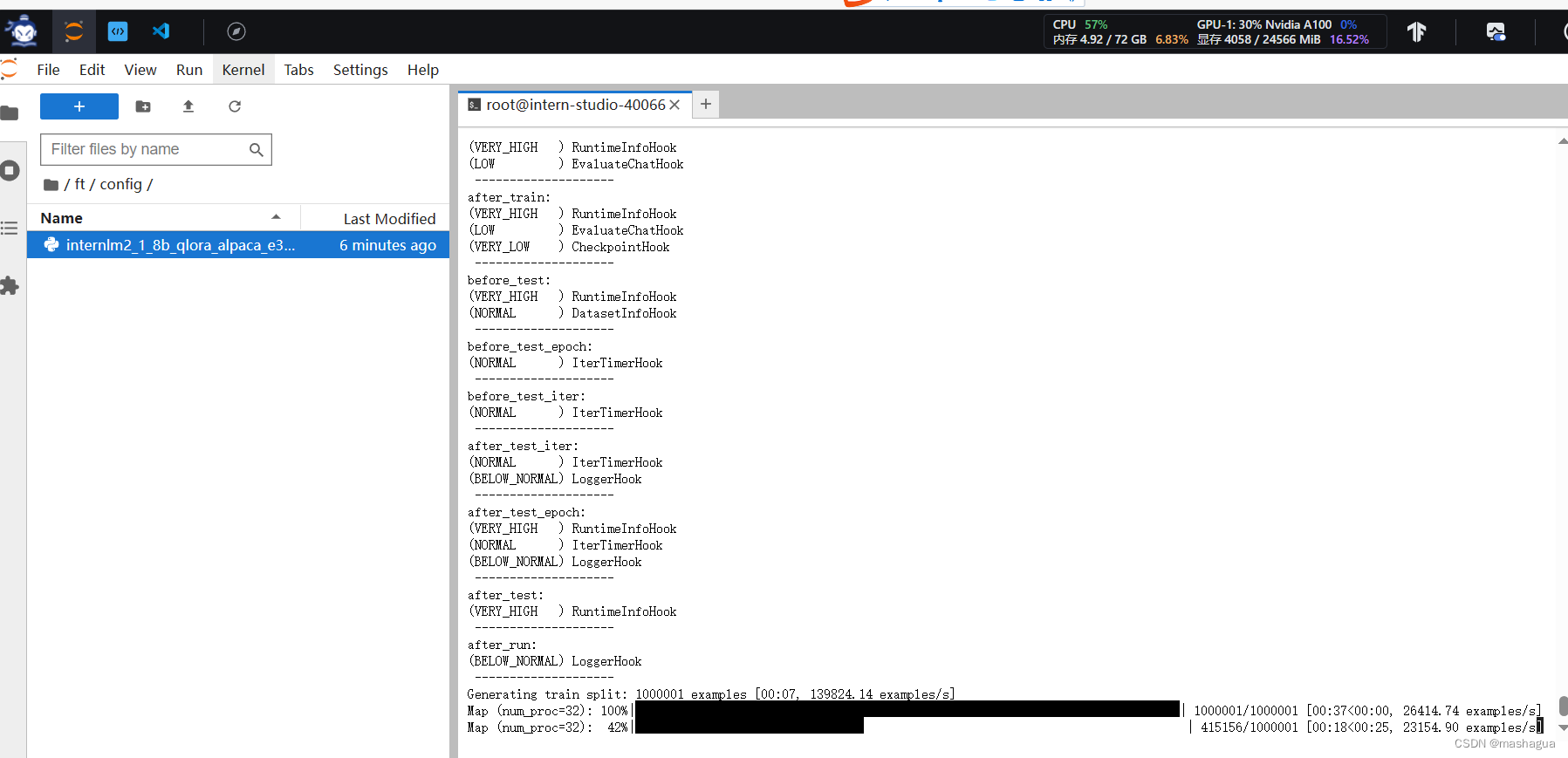
后续可以看到对应的lr的变化以及loss的不断降低
同时可以看到train文件夹中已经存放了对应的模型文件
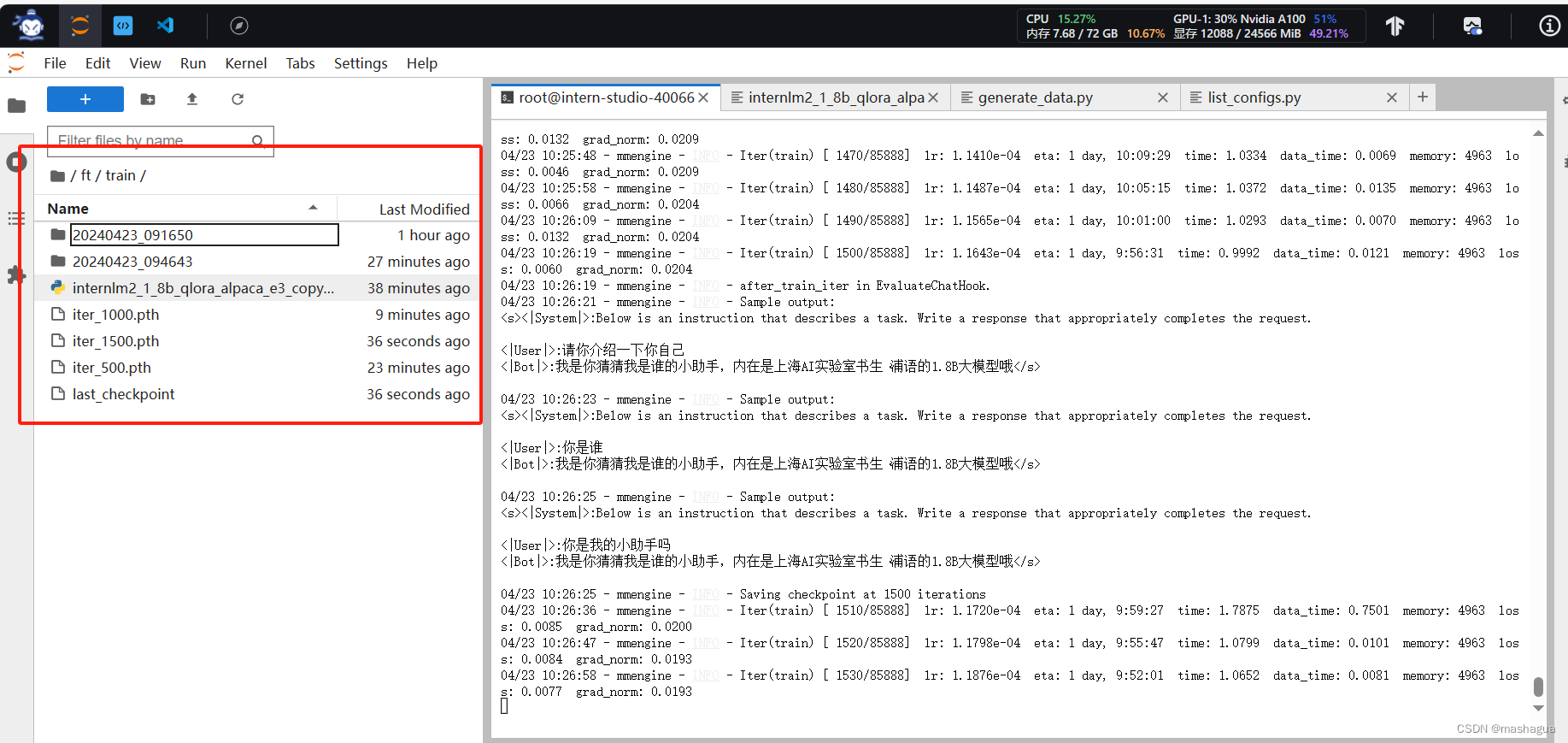
但是由于算力有限,我这个微调时间太长,因此换成了deepspeed 来加速训练
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2
模型转换
# 创建一个保存转换后 Huggingface 格式的文件夹
mkdir -p /root/ft/huggingface
# 模型转换
# xtuner convert pth_to_hf ${配置文件地址} ${权重文件地址} ${转换后模型保存地址}
xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_768.pth /root/ft/huggingface
这时候就是我们常说的lora文件了
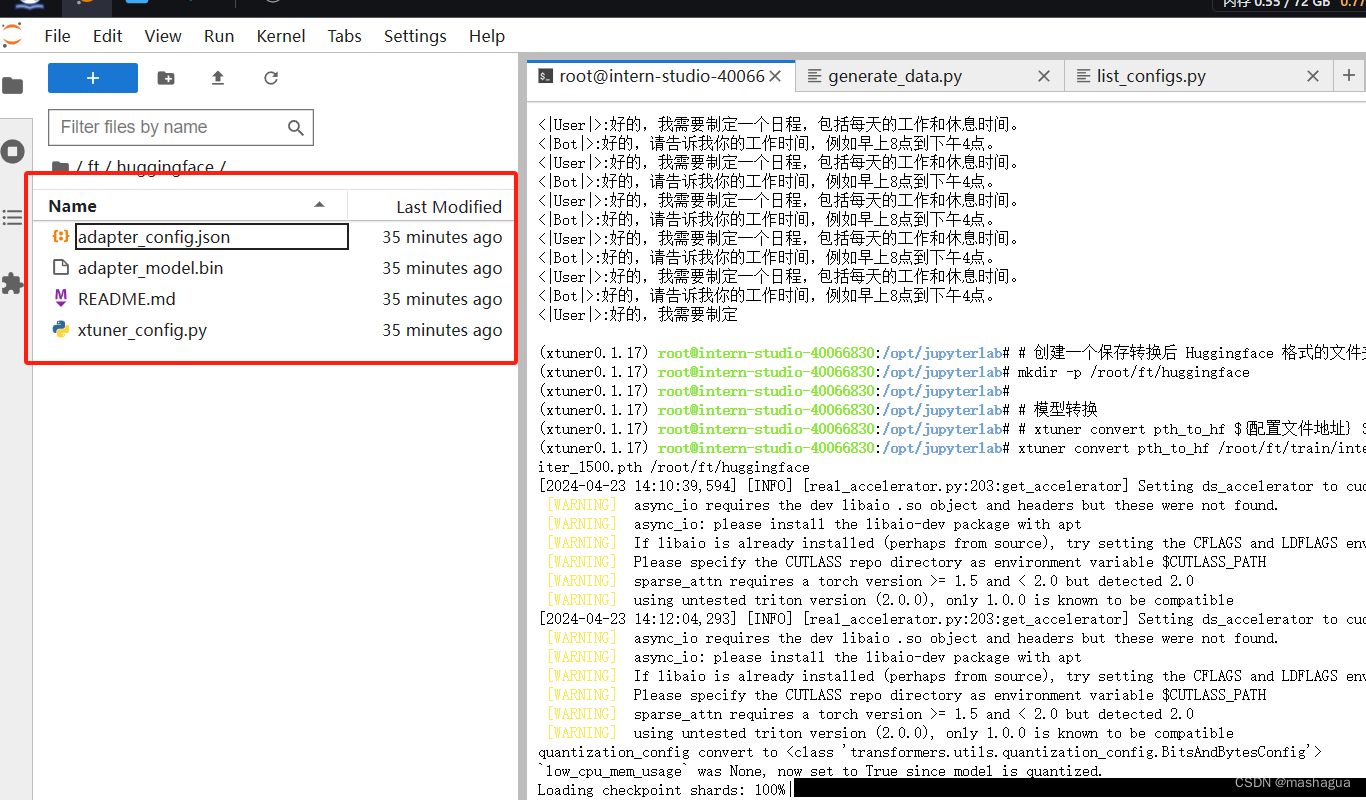
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(adapter)。那么训练完的这个层最终还是要与原模型进行组合才能被正常的使用(备注:全量微调不需要)
# 创建一个名为 final_model 的文件夹存储整合后的模型文件
mkdir -p /root/ft/final_model
# 解决一下线程冲突的 Bug
export MKL_SERVICE_FORCE_INTEL=1
# 进行模型整合
# xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH}
xtuner convert merge /root/ft/model /root/ft/huggingface /root/ft/final_model
测试# 与模型进行对话
xtuner chat /root/ft/final_model --prompt-template internlm2_chat
返回结果
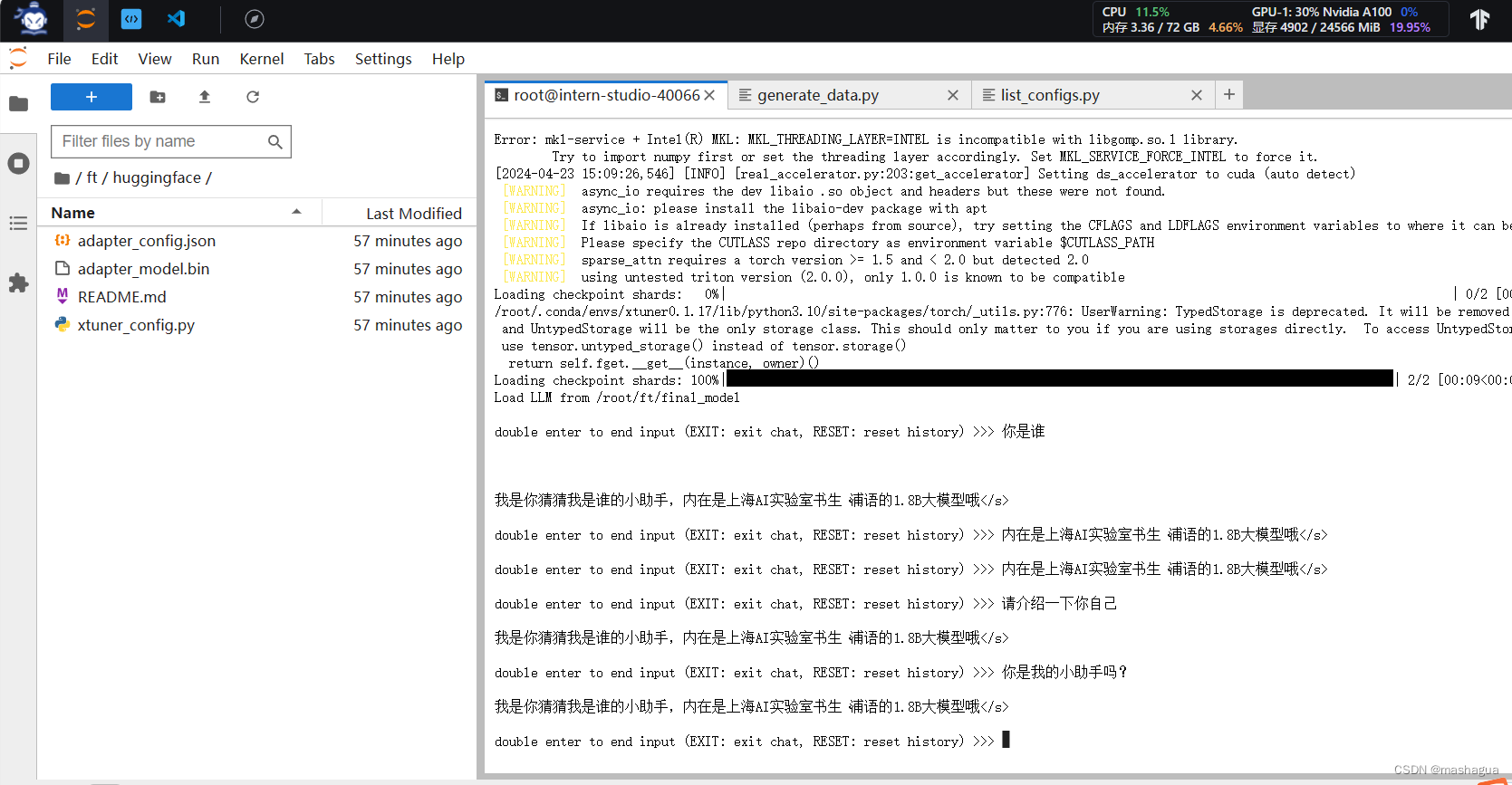
比较一下之前的回复

部署成web界面
# 创建存放 InternLM 文件的代码
mkdir -p /root/ft/web_demo && cd /root/ft/web_demo
# 拉取 InternLM 源文件
git clone https://github.com/InternLM/InternLM.git
# 进入该库中
cd /root/ft/web_demo/InternLM
pip install streamlit==1.24.0
streamlit run /root/ft/web_demo/InternLM/chat/web_demo.py --server.address 127.0.0.1 --server.port 6006
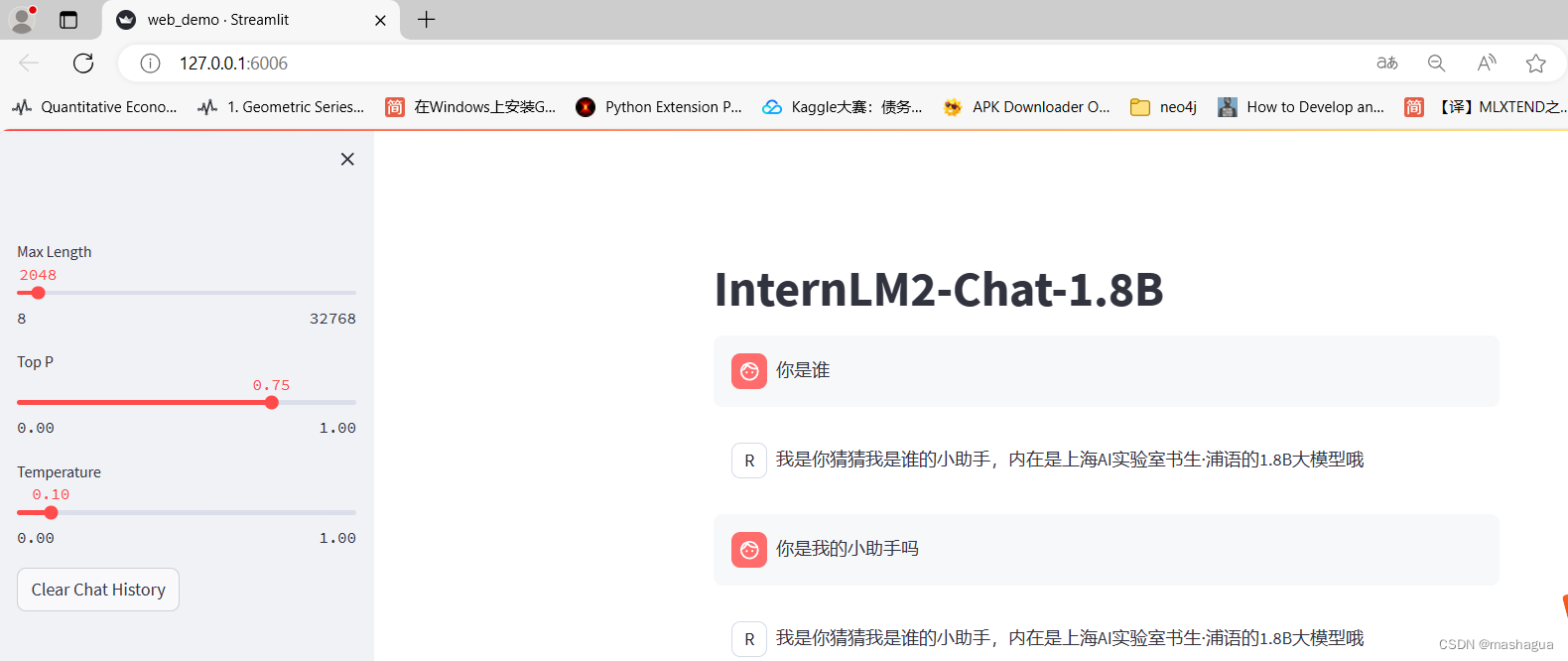
可以看到过拟合了















 952
952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









