






blog链接:RAFT
github链接:GitHub - ShishirPatil/gorilla at gh-pages
文章链接:https://github.com/ShishirPatil/gorilla/blob/gh-pages/assets/RAFT.pdf
现在大模型最有希望的落地方式就是在领域数据上大展身手,于是乎RAG方阵就向我们大步走来。RAG是retrieval-augmented generation的缩写,大致意思是,利用检索得到的信息来加强模型生成结果,而不是直接让模型输出结果。Berkeley,meta和Microsoft一起发了一篇文章叫做RAFT: Adapting Language Model to Domain Specific RAG。今天咱们就来拜读一下。
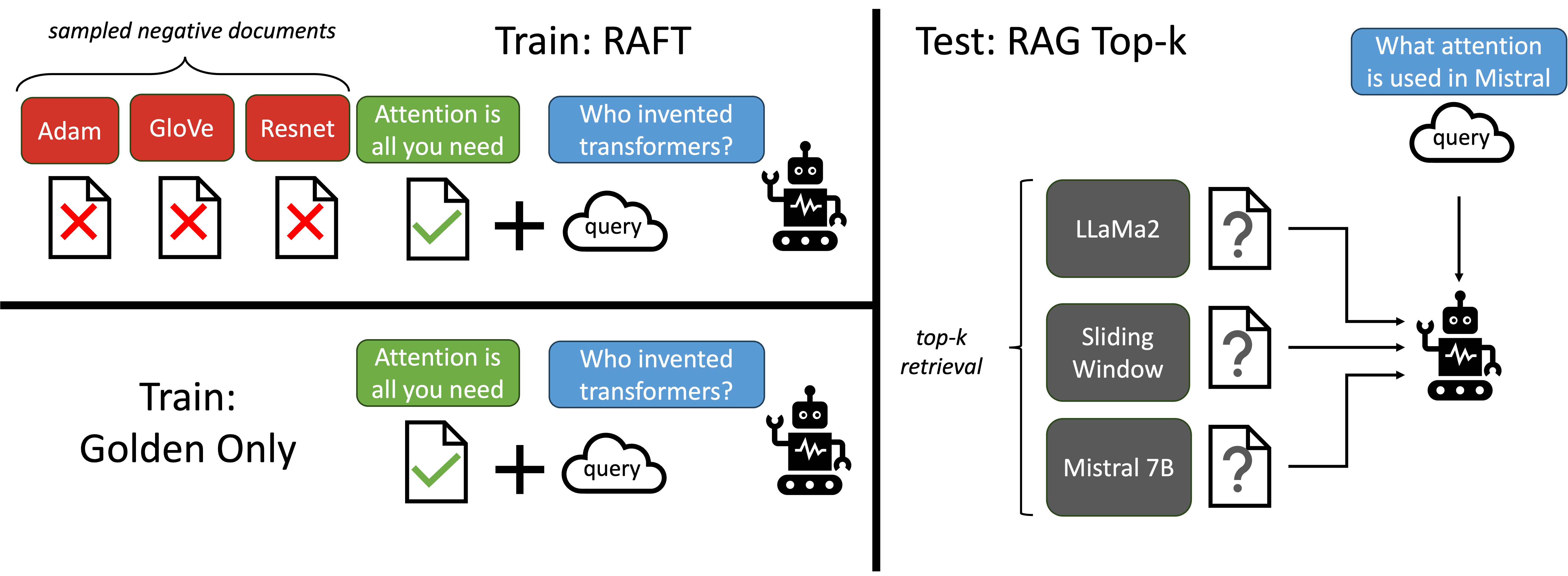
Retrieval Augmented Fine Tuning (RAFT),从全称来看,RAFT会根据领域相关的检索结果来finetune预训练的LLM。作者介绍,RAFT的工作原理是训练模型忽略任何检索到的、无助于回答给定问题的文档,从而消除干扰。因此,就需要准确识别和引用有用文档中的相关片段。另外,RAFT使用chain-of-thought来进一步完善模型的推理能力。
首先文章介绍几个考试,首先想象🤔一下,当我们和LLM问答的时候,可以看作是让LLM参加考试。
Closed-Book Exam:指的是LLM在考试时候无法查看任何其他的文件或资料来回答问题。对于LLM来说,这就是目前被用作chatbot的场景,这个时候LLM的知识储备来源于之前预训练和微调时候累计起来的。
Open-Book Exam:相比之下,还有一种场景就是开卷考。也就是LLM可以参考外部信息(比如网站,文本数据等等等)。这时的LLM会paired with一个检索器,返回K篇文章/文本片段。LLM只有通过这些片段才能得到新的知识。于是乎,咱们这个时候检索结果的质量就会很大程度上影响LLM后续的表现了。(这咋又回到了传统NLP呢。。。。)
RAFT:RAFT还不是开卷考,而是特定领域的开卷考(domain-specific open-book exam),哎,就是LLM不需要去open-domain上检索结果了。而是给了咱们LLM一本领域的参考书(领域文本数据)。LLM可以在这个参考书里找答案回答问题。检索器的能力不需要要求太高,这里咱就有答案。
作者定义了两个文档集,一个是oracle documents (D*),即可以推断出问题答案的文档。另一个是`distractor' documents (Di),就是和答案不相关的文档集。然后,整理了一份训练数据(包含两份数据:P%和1-P%),P%包含了问题、相关问答、不相关文档,1-P%包含了问题、不相关文档。下图中, A*是a corresponding Chain-of-though style answer,Q是question 。
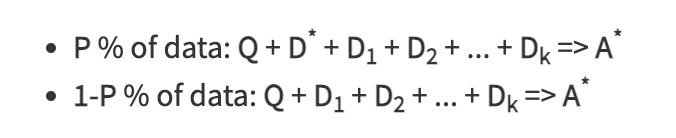
然后作者拿着🫴这份数据利用standard supervised training (SFT)对语言模型进行finetune。
在blog中,作者给出了一份训练数据的样例(来咱们看看prompt怎么写):
Question: The Oberoi family is part of a hotel company that has a head office in what city?
context: [The Oberoi family is an Indian family that is famous for its involvement in hotels, namely through The Oberoi Group]...[It is located in city center of Jakarta, near Mega Kuningan, adjacent to the sister JW Marriott Hotel. It is operated by The Ritz-Carlton Hotel Company. The complex has two towers that comprises a hotel and the Airlangga Apartment respectively]...[The Oberoi Group is a hotel company with its head office in Delhi.]
Instruction: Given the question, context and answer above, provide a logical reasoning for that answer. Please use the format of: ##Reason: {reason} ##Answer: {answer}.
CoT Answer: ##Reason: The document ##begin_quote## The Oberoi family is an Indian family that is famous for its involvement in hotels, namely through The Oberoi Group. ##end_quote## establishes that the Oberoi family is involved in the Oberoi group, and the document ##begin_quote## The Oberoi Group is a hotel company with its head office in Delhi. ##end_quote## establishes the head office of The Oberoi Group. Therefore, the Oberoi family is part of a hotel company whose head office is in Delhi. ##Answer: Delhi可以看到这份数据里包含了questions, context, instruction以及最终的CoT answer(chain-of-thought)。他们发现用##begin_quote##和##end_quote##表示引用的开头和结尾能够给模型有效提供上下文。
对于最终的实验结果的话,RAFT当然要好一些啦,不然发这个文章干啥呢。然后对于模型的选择,文章大大夸赞了一番Llama2-7B,“适用于RAG任务,是良好的基础模型,在单个GPU上也可以提供服务,易于部署balbalbal”。羡慕啊,他们是在Microsoft AI studio来进行模型的微调的,也不知道外人要花多少个铜板才能玩。有一说一,那个blog最后一直在彩虹屁,有点子像广告帖。Thanks to the help of Meta Llama-2 and Microsoft AI Studio, it is easy to fine-tune and deploy LLMs for enterprises, greatly enabling the deployments of custom models for different enterprises.
好的,读完了这篇文章,大概学到了一种微调数据生成的方式。。。看看啥时候试试效果吧。现在越来越不相信效果好这件事情了。

















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









