







论文:RAFT: Adapting Language Model to Domain Specific RAG
⭐⭐⭐⭐
UC Berkeley, arXiv:2403.10131
Blog:gorilla.cs.berkeley.edu/blogs/9_raft.html
一、论文速读
RAFT(Retrieval Aware Fine-Tuning)是一个经过监督微调(SFT)后的 LLM,在运行时通过检索特定领域的参考资料来回答用户的问题。
RAFT 的特点在于它的微调(SFT)过程。在 SFT 过程中,训练模型忽略任何检索到的、无助于回答特定问题的文档,从而让模型学会消除干扰。另外,RAFT 使用 chain-of-though 来进一步提高模型的推理能力。
RAFT 在 LLaMa2-7B 模型上经过 SFT 得到的,SFT 的思路如下:
在每一个训练样本中,包含一个 question Q Q Q,一个文档集合 D k D_k Dk,一个针对 question 的 chain-of-though 风格的 answer A ∗ A* A∗,另外还有两类 documents:
- oracle document D ∗ D* D∗:可以推导出问题答案的 doc,也就是对回答问题有用的 doc
- distractor document D i D_i Di:干扰文档,对回答问题没有用的 doc
我们期望 RAFT 能够在看到输入 Q Q Q、 D ∗ D* D∗、 D i D_i Di 后,能够生成 A ∗ A* A∗,以此为目标对其进行监督微调。
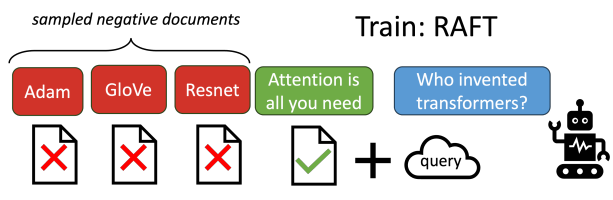
但这里有一个关键 trick:对于 P P P% 的训练样本,我们给 RAFT 输入了 Q Q Q、oracle doc 和 distractor doc,但剩下的 ( 1 − P ) (1-P) (1−P)% 的训练样本,只给 RAFT 输入 Q Q Q 和 distractor doc,不再给他输入 oracle doc,如下所示:
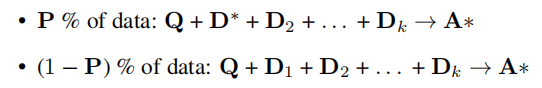
这种在微调时特意混合相关文档和不相关文档的做法,可以有效提高模型忽略不相关信息的能力。这种思路是特意针对目前的 LLM 具有对不相关文本太脆弱的问题而设计的。
二、论文中一些讨论
2.1 LLMs for Open-Book Exam
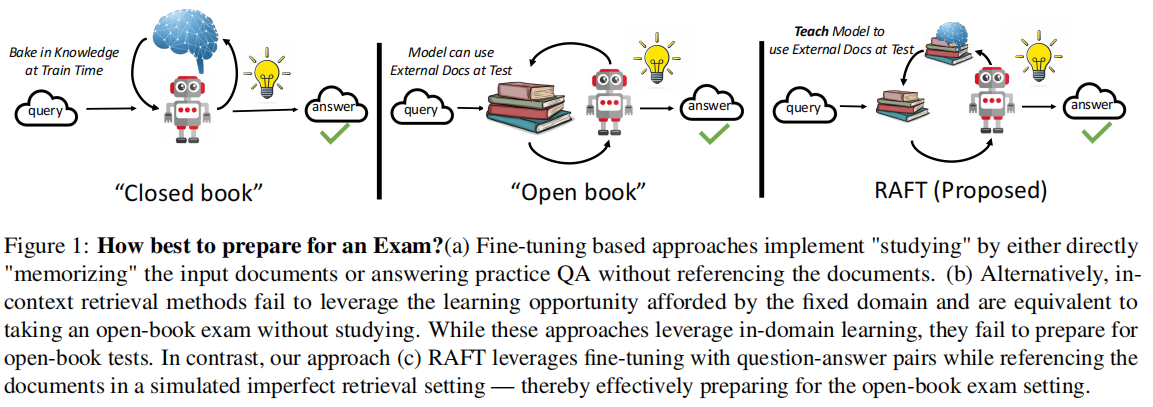
论文用现实世界的“让 LLM 去准备一场考试”做了一个很形象的比喻,存在三类考试:
- Closed-Book Exam:即闭卷考试,在考试期间,LLM 不允许去参考任何其他文档资料,只能凭借自己的预训练期间得到的参数化知识来完成回答。
- Open Book Exam:即开卷考试,考试期间,LLM 可以去参考任何互联网资料,从而获取 “new knowledge” 来完成回答。
- Domain Specific Open-Book Exam:这是本文重点关注的方向。LLM 事先知道自己将要被测试的 domain,并会提前准备,考试时,可以参考该领域的所有文档资料来完成回答。
在我们的场景中,特定领域的文档资料就是企业的内部文档、最新的新闻或者企业私有的代码库等等。而所谓的“提前准备考试”,就是使用特定领域的训练数据来对 LLM 进行 SFT。
下图展示了不同的考试类型:
2.2 RAG & SFT
- RAG:Retriveal Augmented Generation
- SFT:Supervised Fine-Tuning
论文对两者的特点和存在的缺点进行了讨论:
- RAG only:基于 RAG 的方法,允许 LLM 在测试期间去参考相关文档,但没能利用模型在训练学习期间去适应这个 domain 的场景,也没有学习如何去利用可以参考的文档,相当于“不学习直接带着课本去考试”
- SFT only:像最开始发布的 ChatGPT,在测试期间只能凭借自己的参数化记忆来完成用户回答,无法参考文档,相当于“努力学习了但没带课本去考试”
所以本文所研究的核心问题就是:How to adapt pre-trained LLMs for Retrieval Augmented Generation(RAG) in specialized domains?
RAFT 模型关注的就是如何让 SFT 和 RAG 进行结合,来达到更好的效果。
三、CoT 的使用
前面第一节就介绍了 RAFT 的训练思路,这里着重介绍一下 chain-of-though 是如何用于提升 RAFT 的推理能力的。
用于对 RAFT 进行 SFT 的训练数据中,每个 question 的 answer 都是 CoT style 的,并且 answer 中还清晰地标注了引用来源。一个训练数据样本如下所示:
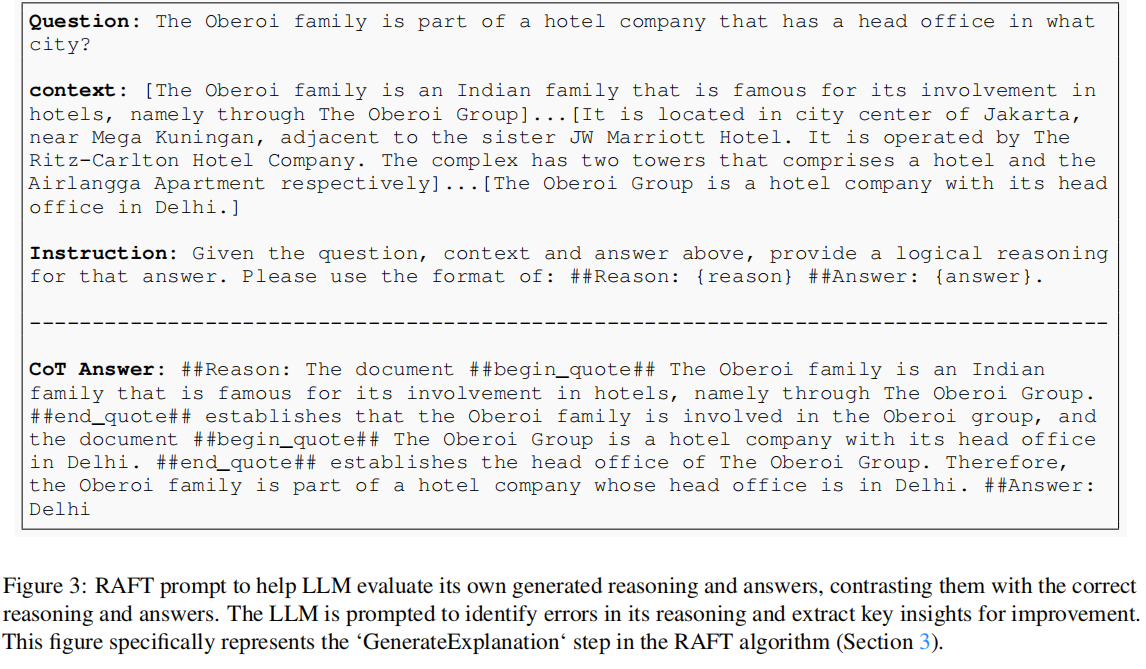
使用这个 CoT style 的 answer 作为训练样本对 RAFT 进行 SFT,是提高训练质量的关键因素之一。
四、RAFT 成功的总结
总结一下 RAFT 模型能够表现好的原因:
- 对原生的 LLM 模型,使用 domain specific 的训练数据对其进行 SFT,让 LLM 能够提前熟悉这个 domain,并学会利用检索到的文档来生成回答。
- SFT 训练中,将 oracle doc 和 distractor doc 进行混合来对 LLM 做训练,提高了 RAFT 忽略不相关信息的能力。
- SFT 训练样本中,answer 采用 CoT style,提高了模型的推理能力。
RAFT 是一个巧妙融合了 SFT 和 RAG 的方法,它独立于 retriever 的选型,是一个很值得参考的工作。















 1274
1274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









