







虽然LLM的文章还没都看完,但是终究是开始看起来了VLM,首当其冲,当然是做一片文献综述啦。这篇文章比较早了,2024年2月份出的last version。
文章链接:https://arxiv.org/abs/2304.00685
GitHub链接:GitHub - jingyi0000/VLM_survey: Collection of AWESOME vision-language models for vision tasks
这篇文章是南洋理工的研究员们做的综述。主要包括以下内容:
(1)介绍视觉识别范式发展的背景;
(2)VLM 的基础,总结广泛采用的网络架构、预训练目标和下游任务;
(3)VLM 预训练和评估中广泛采用的数据集;
(4)现有 VLM 预训练方法、VLM 迁移学习方法和 VLM 知识提炼方法的回顾和分类;
(5)对所回顾方法的基准测试、分析和讨论;
(6)未来视觉识别 VLM 研究中可以关注的几个研究挑战和潜在研究方向。
然后咱们就来进入正文啦!
visual recognition/视觉识别这个大任务是计算机视觉研究里的基础且重要的任务,涉及到图片分类、物体检测和分割之类的。传统的方法需要大量的带标签的数据,来提供给机器学习。最近由于LLM的盛行,模型微调的技术感动人心,vision language model pre-training应运而生,zero-shot prediction露出马脚。
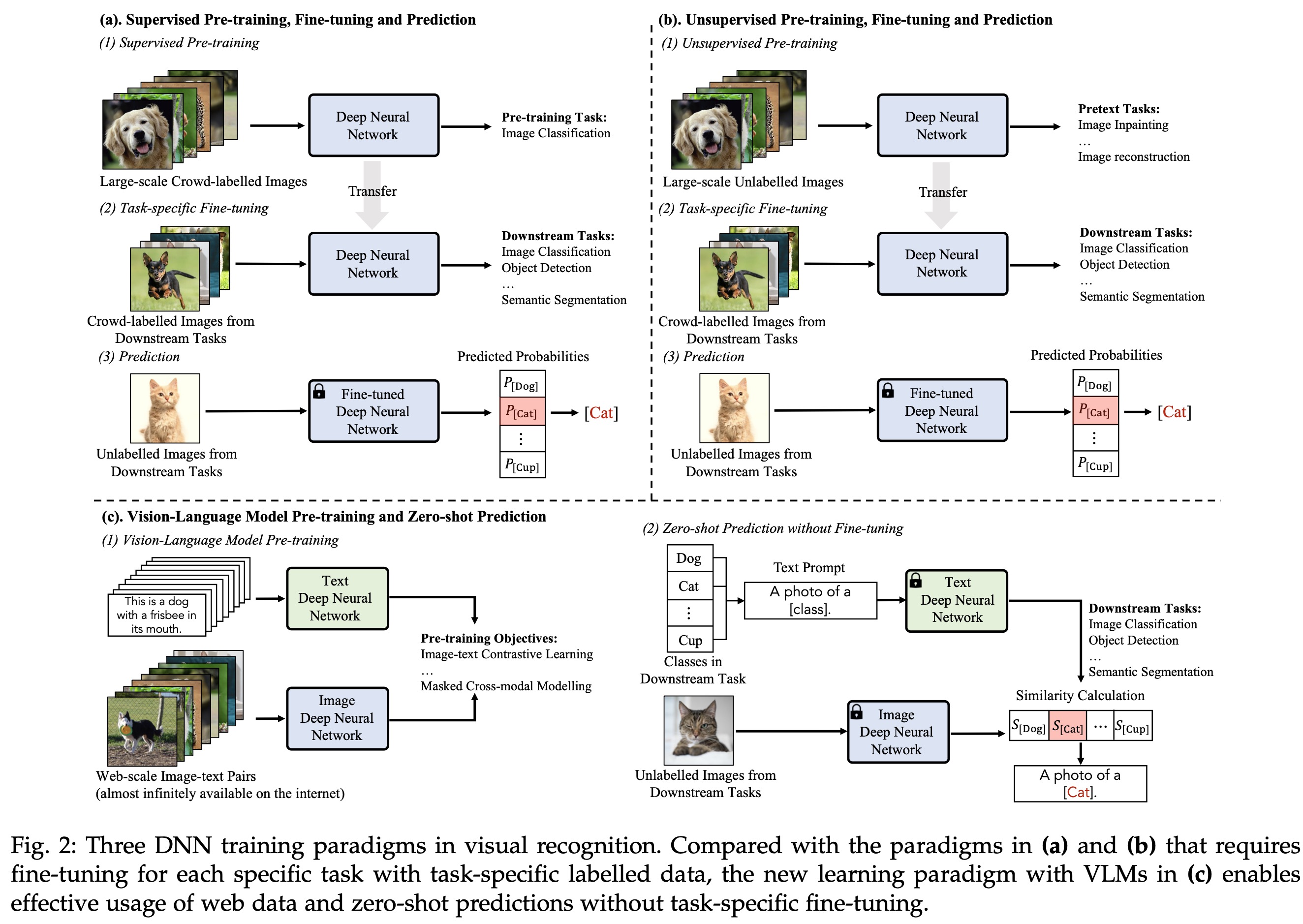
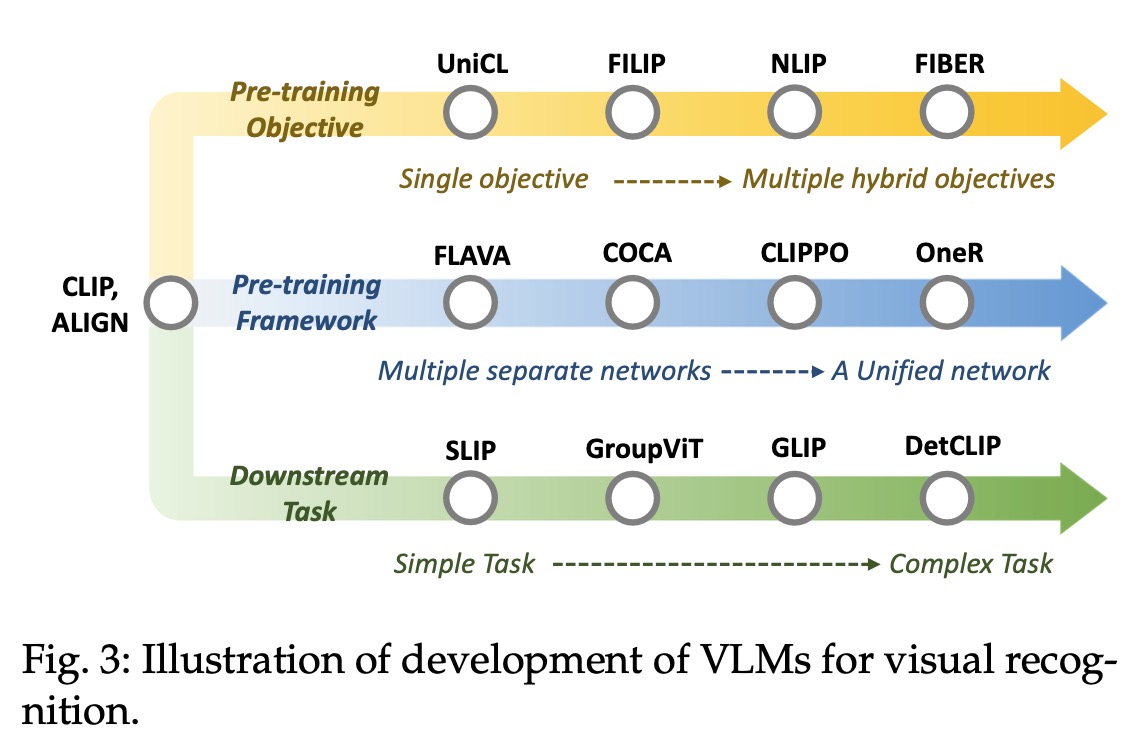
首先,vision language model pre-training是啥呢,就是根据大量的图像-文本对来去学习其中的关系,比如CLIP模型比如一上来我有5对图像文本对,这5个pair就是我的正样本,另外,我继续两两配对出的其他图像文本对就是我的负样本了,not match。接着我们可以通过计算文本和图像之间的相似度来得到文本和图像之间的对应关系。鉴于vision language model pre-training这种训练出来模型的优秀表现,后面延伸出来两类研究,一类是VLMs with transfer learning,比如加入prompt tuning或者在网络结构中加入adapter。一类是VLMs with knowledge distillation,即尝试将有用的信息比如更多的语义知识加入到VLM的训练过程中,让下游任务表现更出色。在不同研究主题发展的过程中,贴心作者列出了你不得不知道的那些VLM工作:
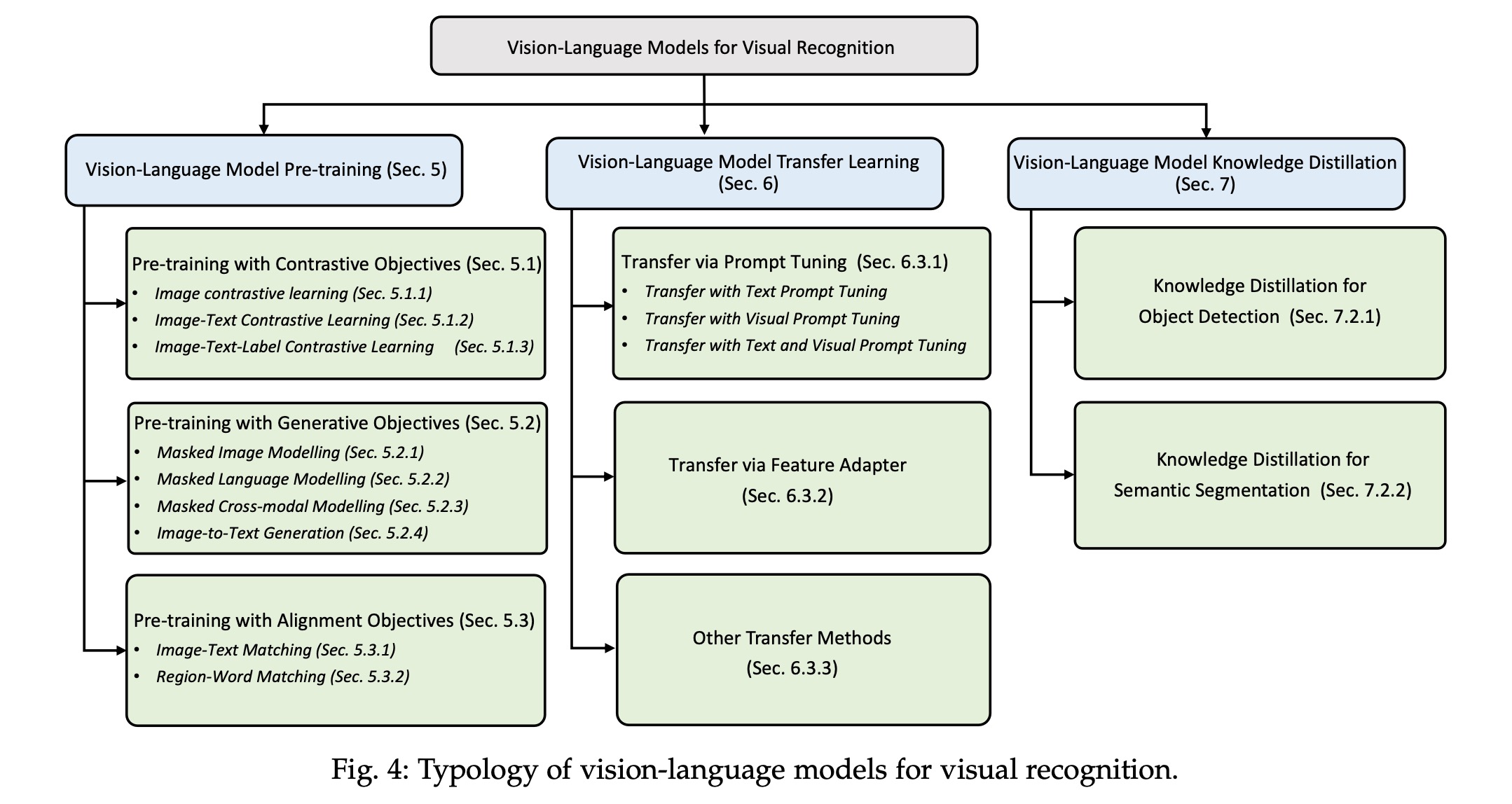
以及本篇文章讲到的VLM相关工作的拓扑结构:
首先,在VLM模型的训练过程中,必要的步骤就是要把图片和文本的feature分别去做表示,在学习图片的特征时,主要的网络结构有两种:CNN-based(比如ConvNet, VGG, ResNet等)和transformer-based(比如Vit)。学习文本的feature一般就是上Transformer及其变形了。
然后,在学习文本和图像关系的时候,其实是要搞一些任务/目标去学习,主要有三类:contrastive objectives, generative objectives和alignment objectives。 contrastive objectives涉及到image contrastive learning,image-text contrastive learning以及image-text-label contrastive learning。generative objectives涉及到不同类似数据的生成,图像、文本又或是cross-modal两者都有,因此在做masked的时候可以分成masked image modeling,masked language modeling,masked cross-modal modeling和image-to-text generation。大概就是我掩盖一部分信息来预测或者reconstruct。Alignment objectives就是做对齐,image-text matching,region-word matching。
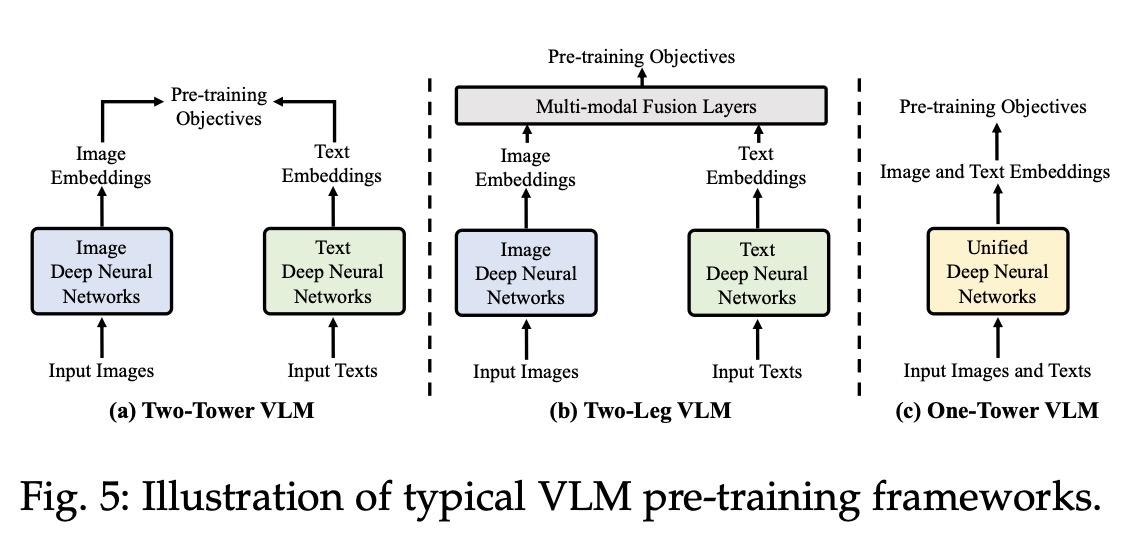
最后,作者给出了VLM pre-training的几种框架,即得到文本和图像的feature后,怎么过layer:two-tower, two-leg and one-tower pre-training frameworks.
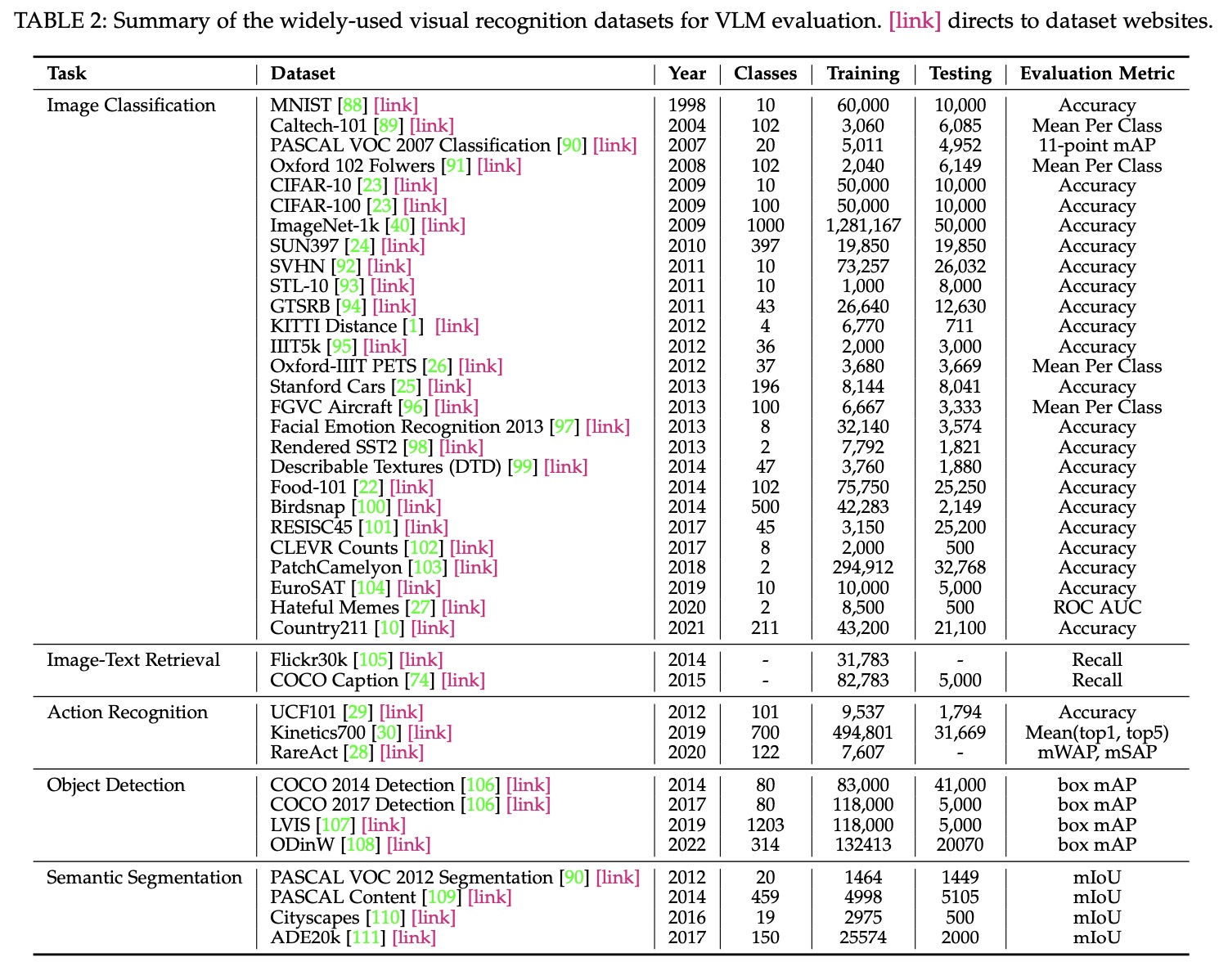
在文章的最后,作者总结了VLM现有的dataset,具体模型的工作。这里给两幅图:
- 不同任务的数据集:
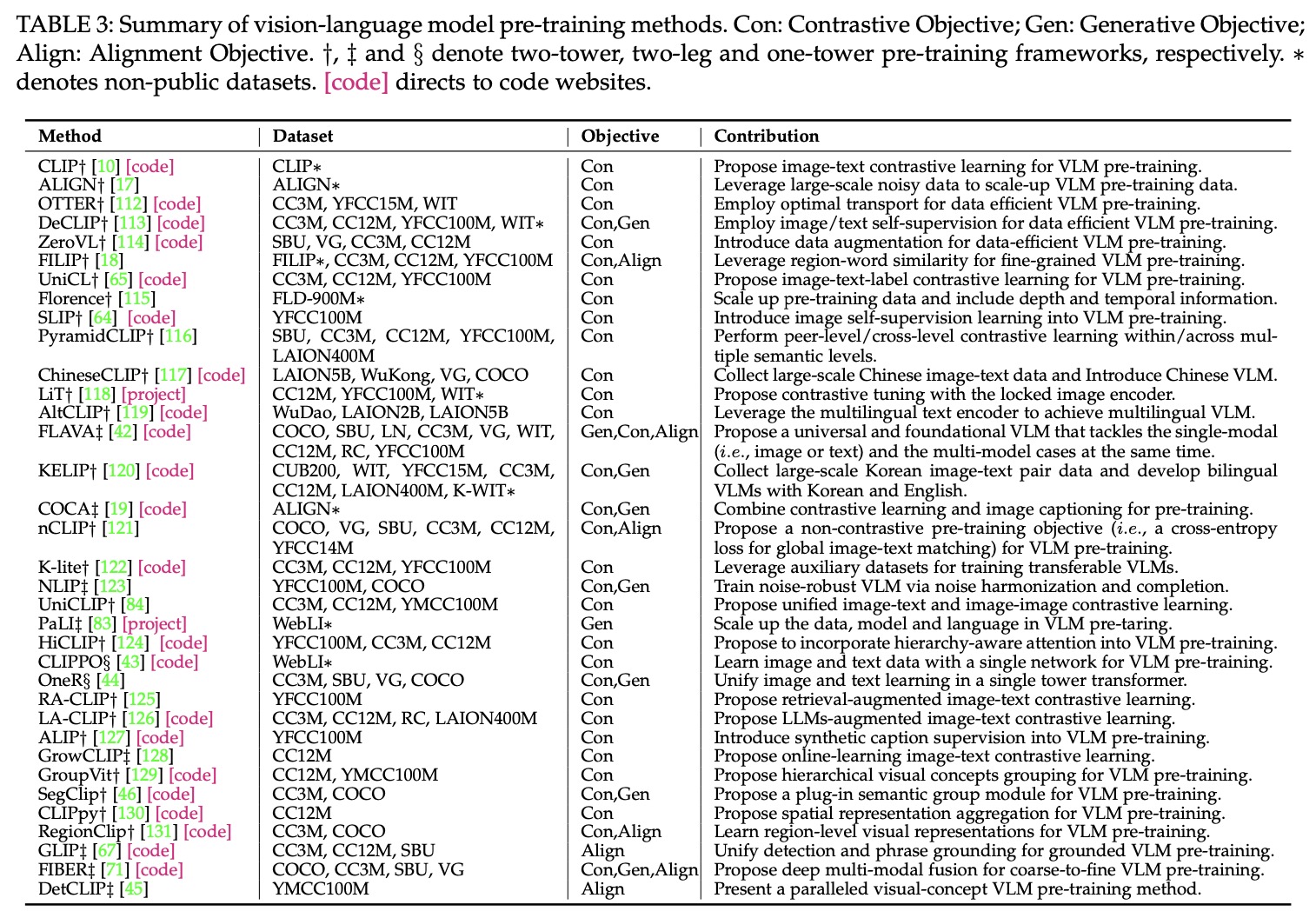
- Summary of vision-language model pre-training methods
具体大家还是看文章啦,业余的感觉能感受到大概框架了。

















 1607
1607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









