








论文信息:Google,2020,AAAI
论文地址:https://arxiv.org/abs/1908.07442
相关代码:https://github.com/dreamquark-ai/tabnet (pytorch版本)
1. 简介
XGBoost和LightGBM这类提升(Boosting)树模型在表格数据任务中有良好的表现,其具有以下优点:
- 模型的decision manifolds可看成超平面边界的
- 可解释性较好
- 训练速度快
传统的DNN一味堆叠网络层易导致模型过参数化,在表格数据上表现不尽人意。而且缺乏归纳偏差 (Inductive Bias),即缺乏学习符合某个规则模型的假设,使得DNN难以在表格决策流形上找到最优解。但如果能够设计这样一种DNN,它既吸收树模型的长处,又继承DNN的优点,那这样的模型无疑是针对于表格数据的一大利器。
TabNet是一种新的高性能和可解释的经典深度表格数据模型架构,继承了树方法的优点 (可解释性和稀疏特征选择),又继承了DNN的优点 (表征学习和端对端训练)。TabNet主要贡献:
- 可直接使用表格数据,不需要预先处理;使用的基于梯度下降的优化方法,使它能方便地加入端到端(end-to-end)的模型中。
- 在每一个决策时间步,利用序列注意力模型选择重要的特征,学习到最突出的特征,使模型具有可解释性。这是一种基于实例的特征选择(对于每个实例选择的特征不同),且它的特征选择和推理使用同一框架。
- TabNet有两个明显优势,一方面是它在分类和回归中都表现出了与其它模型差不多的模型效果,另一方面,它具有局部可解释性(特征重要性和组合方法),和全局可解释性(特征对模型的贡献)。
- 对表格数据,使用无监督数据预训练(mask方法),可提高模型性能。
2. TabNet介绍
整体架构
TabNet结构如下图,一个encoder和一个decoder,其中encoder里有feature transformer、attentive transformer;而decoder只有feature transformer。
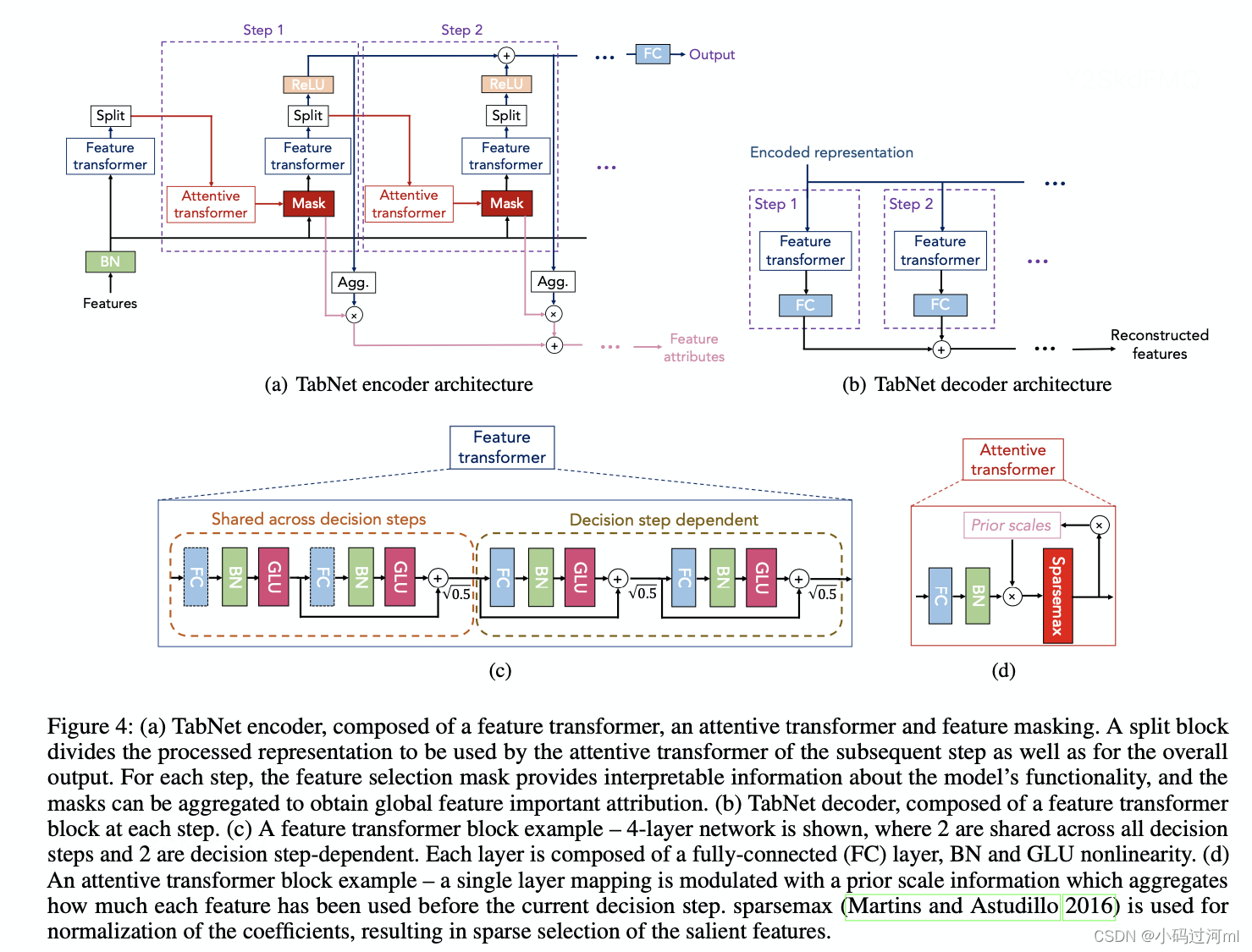
Feature Transformer
Feature transformer模块由两部分组成,前半部分称为参数共享层(在所有step决策中参数共享),作用是提取出特征的共性,这种设计参数更新量更少,学习更加鲁棒;后半部分为参数独立层(在每个step决策中参数不共享),作用是提取出各个sep决策中的特征特征,参数独立使得每个step决策中可能具有不同的特征处理能力,特征处理更加有效。。两部分采用的均是FC+BN+GLU (gated linear unit)的单元方式,其中FC为全连接层,BN为BatchNormal 。
Attentive Transformer
Feature Transformer的输出会被用作Attentive Transformer的输入。Attentive Transformer的主要任务是选择特征子集传递到下一步。通过这种方式,Attentive Transformer执行特征选择,有助于模型关注最重要的特征。
决策步骤
在每一步,模型都使用Attentive Transformer选择特征,并使用Feature Transformer进行特征转换。这样,模型能够逐步地、自适应地进行特征选择和处理。有一个超参数用于设定重复此步骤的次数,这影响了模型的深度和复杂性。
最终预测
模型通过使用每个决策步骤的Feature Transformer输出来生成最终预测,确保了基于全局特征的决策。
注意力掩码
在每一步,模型还生成注意力的掩码,这有助于理解哪些特征被用于进行预测,增强了模型的可解释性。这种结构使TabNet在处理表格数据时既高效又准确,同时还提供了特征重要性的度量,增加了模型的可解释性。
3. 实验
Instance-wise feature selection
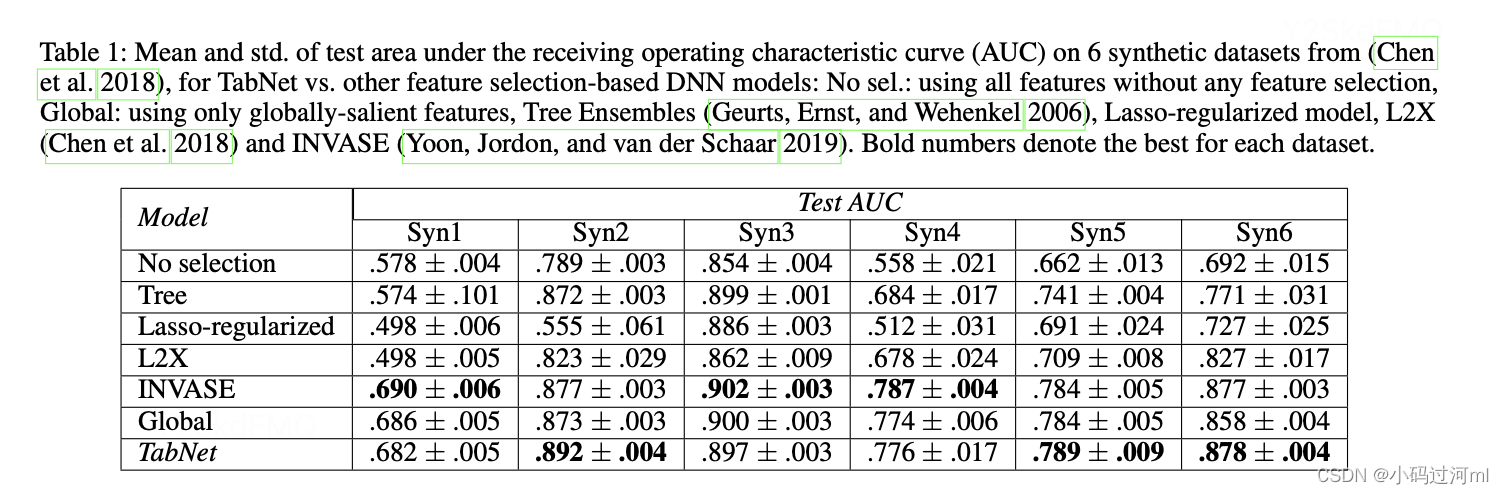
该实验考察的是TabNet根据不同样本来选择相应特征的能力,用的是6个人工构建的数据集Syn1-6,实验结论:
- TabNet比所有其他的模型都要好;
- TabNet的效果与全局特征选择非常接近,它可以找到哪些特征是全局最优的;
- 删除冗余特征之后,TabNet提升了全局特征选择
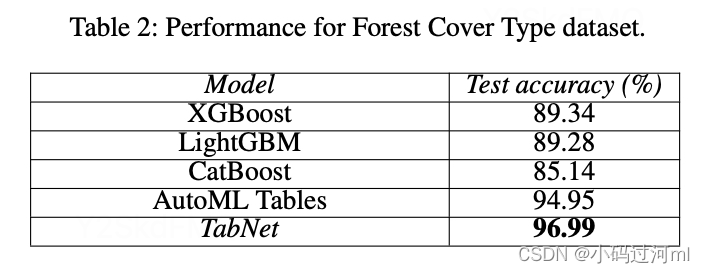
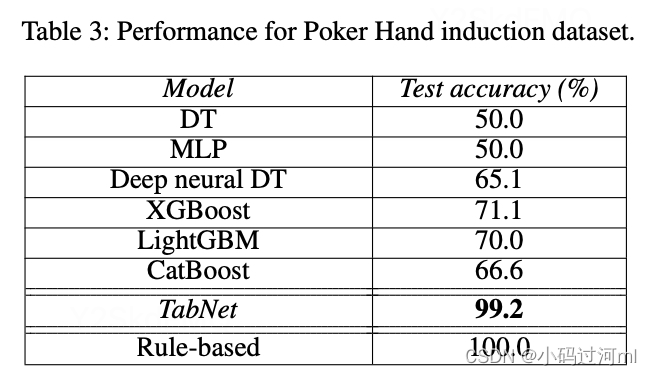
Performance on real-world datasets
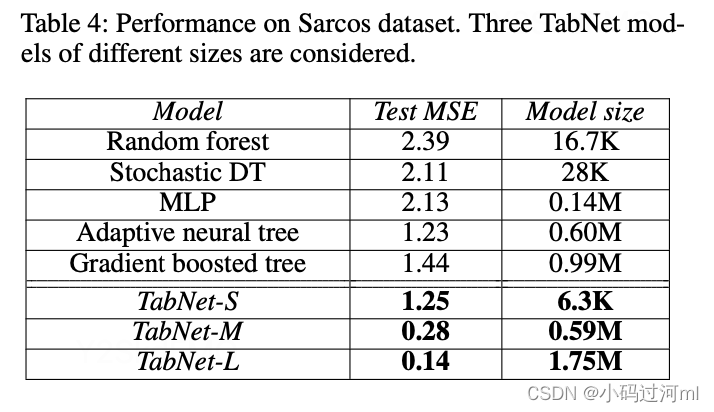
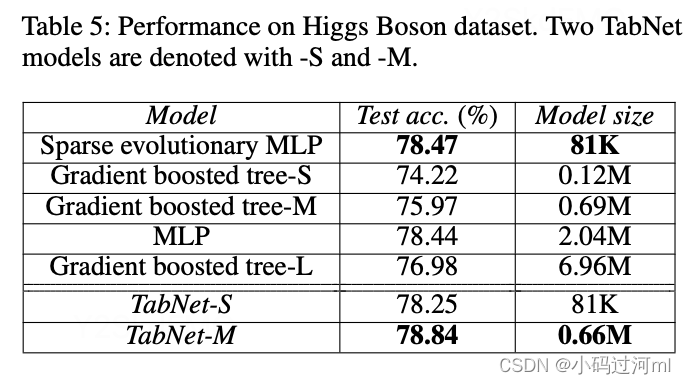
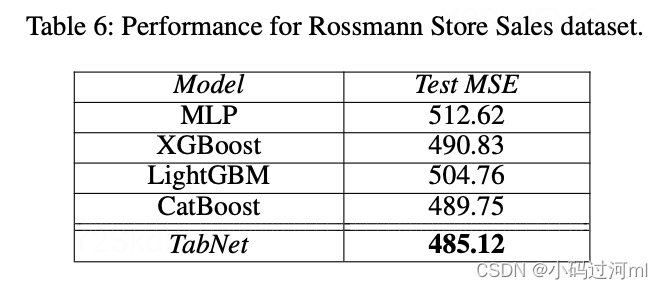

















 2497
2497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









