







N-BEATS: Neural basis expansion analysis for interpretable time series forecasting
0. 论文基本信息

发表信息:ICLR 2020
论文地址:https://arxiv.org/abs/1905.10437
1. 简介
论文主要关注单元/单变量时序点预测问题(univariate times series point forecasting problem)。
时序预测在真实商业中扮演着础并且很重要的角色,然而不像计算机视觉和NLP中,ML和DL已经获取了很好的运用并取得了显著效果,在时序预测中,ML和DL仍然在和传统的统计方法在竞争。例如在M4比赛中,获得最好排名结果的仍然是经典统计技术的集成方法(这里时间点是2018)。另一方面,M4比赛的冠军(Syml 2020),使用的方法是深度模型和Holt-Winters模型的混合模型,因此有人得出结论:使用混合模型是提升时序预测效果和价值的一条有效路径。
本篇论文期望在时序预测任务上探索纯DL架构的模型,进而挑战上面的结论,证明通过纯DL方法也能取得很好的效果。此外,在可解释性DL架构设计方面,作者期望能够回答下面问题:在模型中是不是能通过引入合适的归纳偏置(inductive bias),使其能够提取一些对预测有帮助的可解释性因素,从而使其内部操作更具解释性。
本论文贡献包含两部分:
- 深度学习架构:首次提出了没有运用精心设计的时序模块的纯DL模型,并取得了超过精心设计的统计模型的效果。证明了在时序预测任务上使用纯DL模型是可行的,并且加强了这一条路径的研究积极性。
- 面向时序任务的可解释DL:论文验证了可以通过类似传统的分解方法,例如“seasonality-trend-level”,精心设计模型结构,从而使其具有可解释性输出是可行的。
2. N-BEATS模型结构
论文模型架构设计方法依赖于几个关键原则:
- 首先,基本架构应该是简单、通用、并且表达能力强(体现为模型深度)
- 其次,架构不应该依赖于时间序列特定的特性工程或输入缩放
- 最后,作为探索可解释性的先决条件,架构在使其输出具有可解释性方面是可扩展的
原则1和2让我们探索纯DL架构在时序预测中的潜力
2.1 基本单元(BASIC BLOCK)
N-BEATS基本单元如图1最左部分所示。我们以第 l l l个block为例来进行描述。该block的输入为 x l x_l xl,输出为两个向量: x ^ l \hat x_l x^l 和 y ^ l \hat y_l y^l。
对于第一个block,其输入 x l x_l xl就是整个模型的原始输入:一定窗口大小的历史观测值;如果输出窗口或步数为 H H H,则典型的输入窗口大小为 2 H 2H 2H到 7 H 7H 7H。对于其他block,其输入为前面block的残差。每个block有两个输出, y ^ l \hat y_l y^l表示该block前向预测 H H H步的值, x ^ l \hat x_l x^l表示该block后向预测 x l x_l xl的预测值。
block内部包含两部分。第一部分是一个全连接网络,产生用于预测的膨胀系数正向
θ
l
f
\theta_l^f
θlf和反向
θ
l
b
\theta_l^b
θlb。第一部分的运算如下,这里LINEAR是一个简单的线性变换层,FC层是一个标准的全连接加RELU作为激活函数。
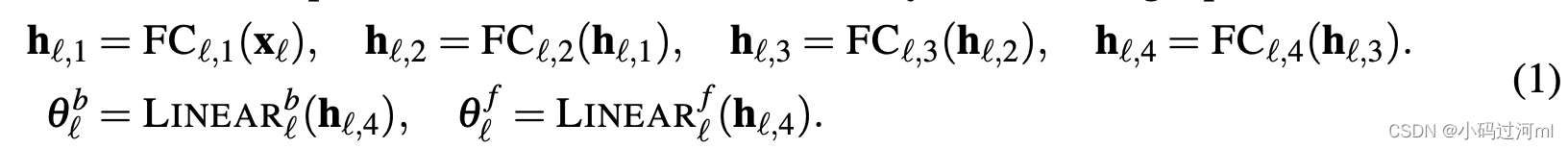
第二部分由两个基层构成:
g
l
f
g_l^f
glf和
g
l
b
g_l^b
glb,它们分别接受输入
θ
l
f
\theta_l^f
θlf和
θ
l
b
\theta_l^b
θlb,生成前向预测
y
^
l
\hat y_l
y^l和后向预测
x
^
l
\hat x_l
x^l。其基本运算如下面公式所示,这里
v
i
f
v_i^f
vif和
v
i
b
v_i^b
vib分别是前向和后向基向量。函数
g
l
f
g_l^f
glf和
g
l
b
g_l^b
glb用来提供足够丰富的集合
{
v
i
f
}
i
=
1
d
i
m
(
θ
l
f
)
\{v_i^f\}_{i=1}^{dim(\theta_l^f)}
{vif}i=1dim(θlf)和
{
v
i
b
}
i
=
1
d
i
m
(
θ
l
b
)
\{v_i^b\}_{i=1}^{dim(\theta_l^b)}
{vib}i=1dim(θlb),这样他们的输出可以等价的看成是膨胀系数
θ
l
f
\theta_l^f
θlf和
θ
l
b
\theta_l^b
θlb的一个直接反馈。
g
l
f
g_l^f
glf和
g
l
b
g_l^b
glb可以是可学习的,也可以设置为特定的函数形式,用来反映特定问题的归纳偏置,进而限制输出的结构。
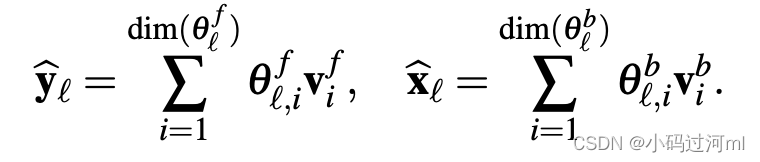
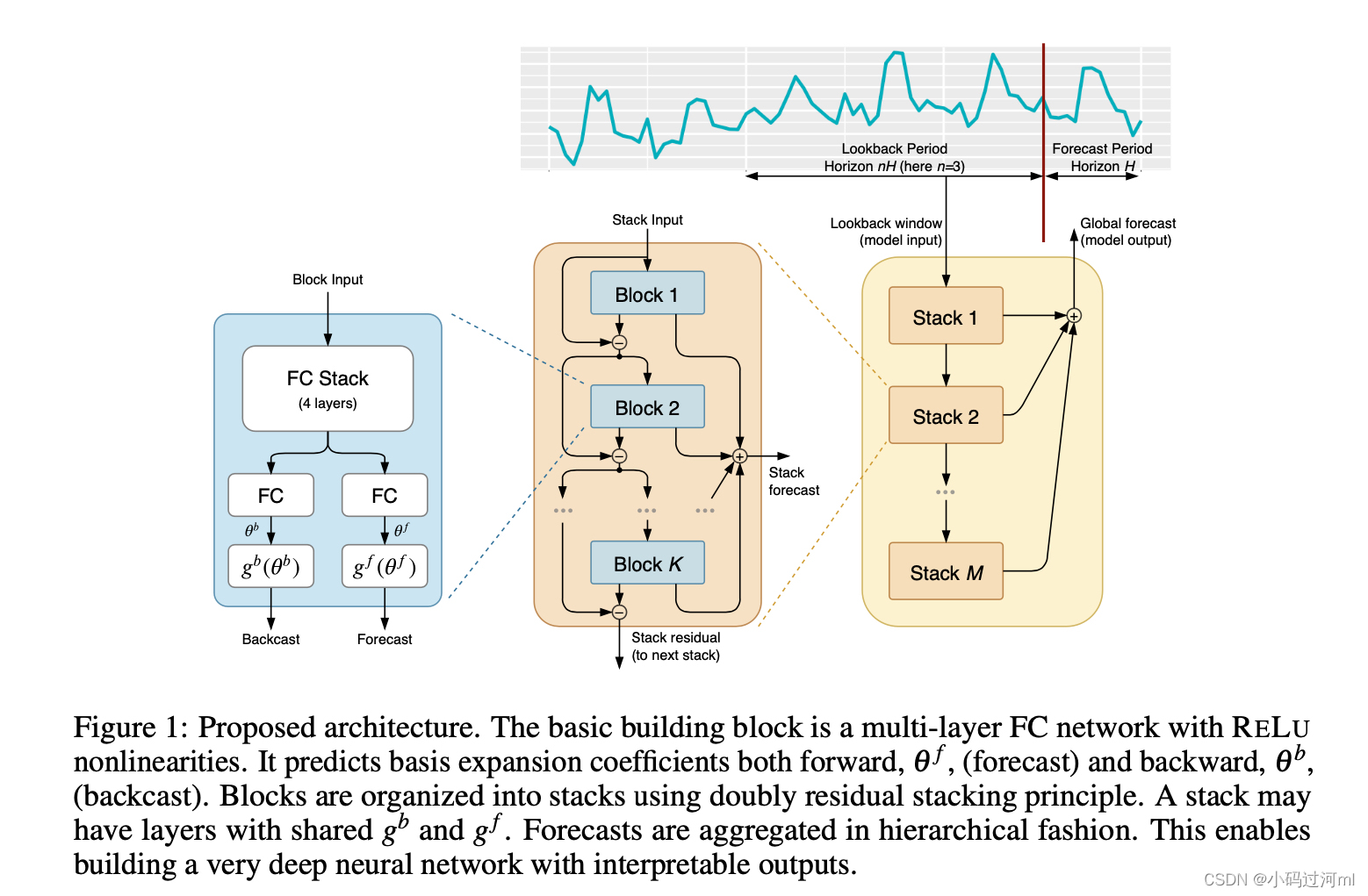
2.2 双重残差叠加 DOUBLY RESIDUAL STACKING
经典的残差网络架构在将结果传递给下一个模块之前,会将输入添加到输出中,这在提高深层架构的可训练性方面具有明显的优势。在时序任务中使用该方法的问题是它们导致了难以解释的网络结构。论文提出了一种新的分层双残差拓扑结构,如图1(中间和右边)所示。提出的架构包含两个残差分支,一个分支运行在每一层的前向预测上,另一个分支运行在每一层的后向预测上。其运算描述如下公式:
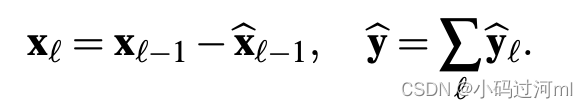
如前所述,第一个block的输入是模型的全部原始输入
x
x
x。对于其他所有blocks,backcast残差分支可以认为是在对输入信号进行序列分析。前一个block去掉了其可以很好拟合的部分
x
^
l
−
1
\hat x_{l-1}
x^l−1,使得下游block的预测更加容易。这种结构同时还促进了梯度反向传播。
更重要的是,每个基本block输出它本身可以预测的部分前向预测 y l ^ \hat{y_l} yl^,这些前向预测提供了层级分解,其首先在stack层级聚合,然后再整个模型层级聚合,最终的预测结果是全部预测结果的和。
在通用模型中,允许每一个block有自己的后向
g
l
b
g_l^b
glb 和前向
g
l
f
g_l^f
glf ,此时网络对梯度流更加透明。
在精心设计的不同stack之间共享
g
l
b
g_l^b
glb 和
g
l
f
g_l^f
glf的架构下,通过聚合各个部分的预测,对实现可解释性至关重要。
2.3 可解释性
基于 g l b g_l^b glb 和 g l f g_l^f glf的选择,论文提出了两种模型架构,通用架构和可解释性架构。
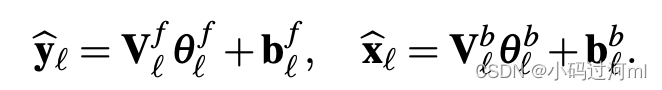
** 待完善 **
3. 实验
论文中说的两个模型架构被记为:generic (N-BEATS-G) 和 interpretable (N-BEATS-I)
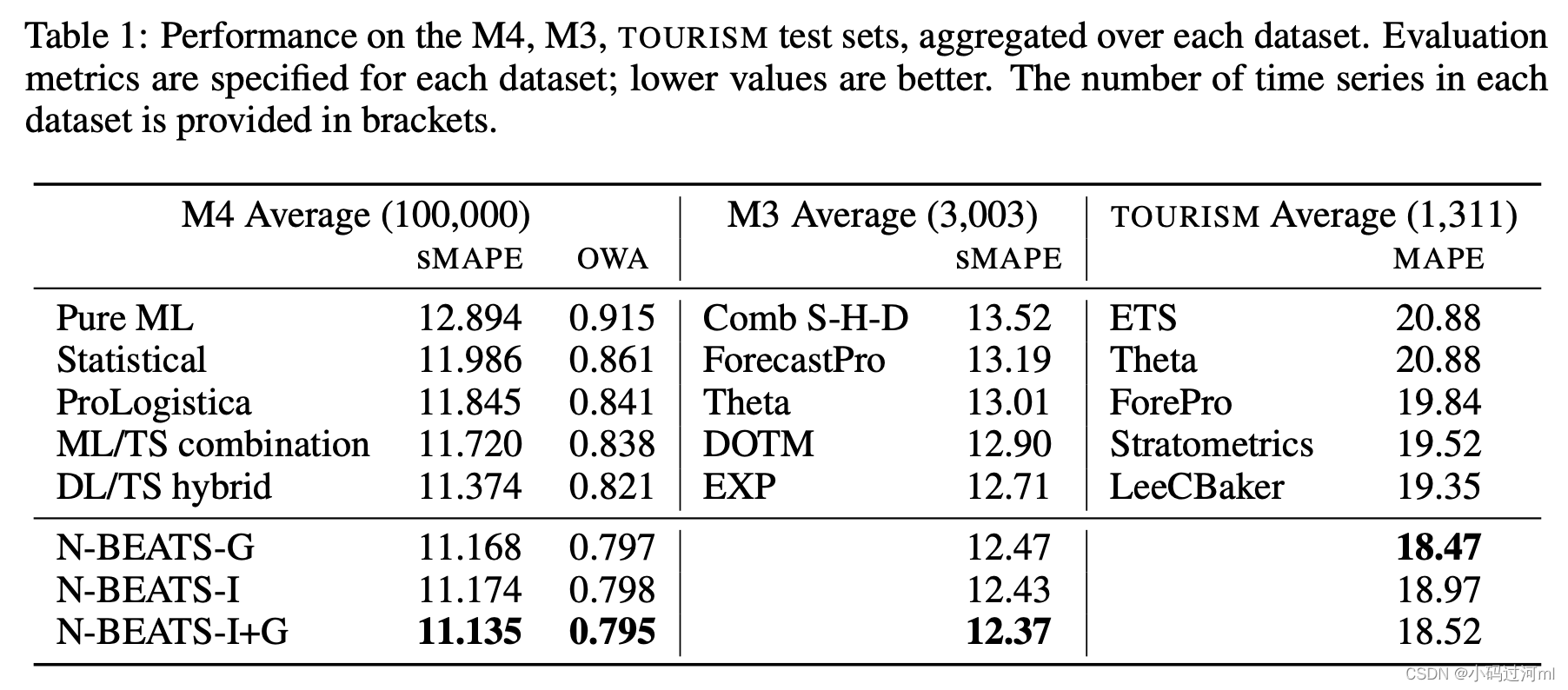
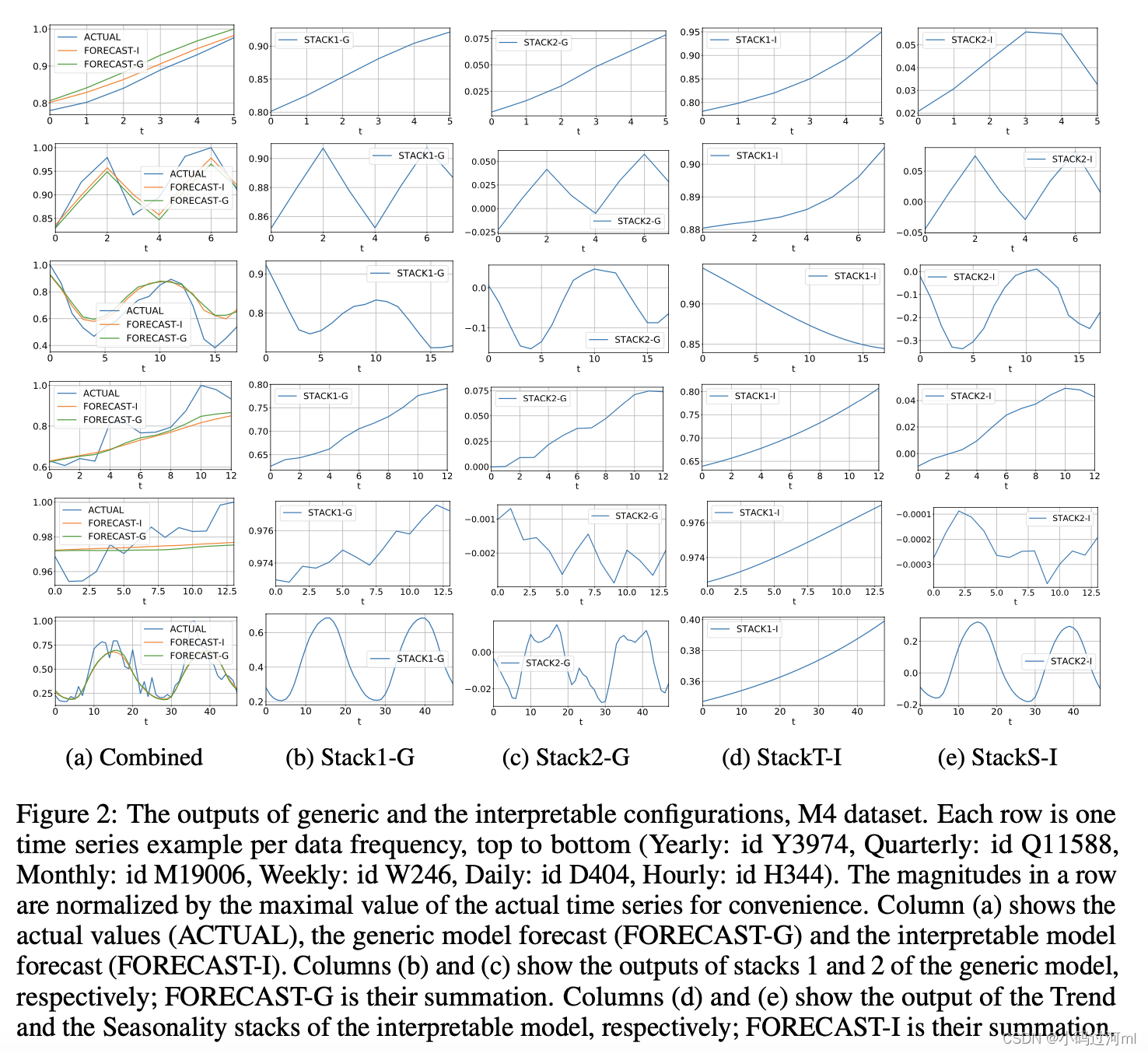














 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









