







一、训练数据人像分割
训练ER-NeRF或者RAD-NeRF时,在数据处理时,其中有一步是要把人像分割出来,而且人像要分成三块,人的头部,人的有脖子,人的身体部分,效果如下:

从上面的分割的结果,可以到,算法最终要的结果是头部用蓝色表示,脖子用绿色表示,身体部用红色表示,背景部分用白色表示,但很多时候,分割的效果并不是都这么理想,会出现各种各样问题,比如下面的分割效果,它会把身体一部分当成背景颜色:

这样的分割效果,如果用到训练里面去,就会影响训练的效果,解决的办法是,可以去优化源码里面自带的bisnet网络,但操作起来有些麻烦。我自己试着重构代码,但效果还是不理想。后来看到Segment-and-Track Anything这个项目,就想到跳出当前的框架,直接用Segment-and-Track Anything来解决这个问题。
二、Segment-and-Track Anything
1. 算法简介
“Segment-and-Track Anything” 是由浙江大学 ReLER 实验室开发的一款多功能视频分割和目标跟踪模型,它深度整合了 SAM(Segment Anything Model)和视频分割技术,使其能够高效地跟踪视频中的目标,并支持多种交互方式(如点、画笔和文字输入)。
在这个基础上,SAM-Track 实现了多个传统视频分割任务的统一,使其能够一键分割和追踪任意视频中的任意目标,将传统视频分割技术推向通用视频分割领域。SAM-Track 在复杂场景下表现出卓越的性能,即使在单一GPU卡上也能高质量地稳定跟踪数百个目标。
SAM-Track 模型基于 ECCV’22 VOT Workshop 四个赛道的冠军方案 DeAOT。DeAOT 是一种高效的多目标视频对象分割模型,在提供首帧物体标注的情况下,可以对视频的其余帧中的物体进行追踪分割。DeAOT 使用一种识别机制,将一个视频中的多个目标嵌入到同一高维空间中,从而实现对多个物体的同时跟踪。DeAOT 在多物体追踪方面的速度表现媲美其他专注于单个物体追踪的 VOS 方法。此外,通过基于分层 Transformer 的传播机制,DeAOT 更好地整合了长时序和短时序信息,表现出卓越的追踪性能。然而,DeAOT 需要参考帧的标注来初始化,为了提高方便性,SAM-Track 利用了图像分割领域的明星模型 SAM,以获取高质量的参考帧标注信息。SAM 凭借出色的零样本迁移能力以及多种交互方式,使 SAM-Track 能够为 DeAOT 高效获取高质量的参考帧标注信息。
虽然 SAM 模型在图像分割领域表现出色,但它无法输出语义标签,并且文本提示也无法有效地支持 Referring Object Segmentation 以及其他依赖深层语义理解的任务。因此,SAM-Track 模型进一步集成了 Grounding DINO,实现了高精度的语言引导视频分割。Grounding DINO 是一种开放集合目标检测模型,具备出色的语言理解能力。
2. 项目部署
2.项目部署
可参考我之前的博客:
Segment-and-Track Anything——通用智能视频分割、目标追踪、编辑算法解读与源码部署
3.项目应用
运行项目之后,打开项目的交互界面,然后打开要分割的视频,然后等待一会,下面的窗口就出现视频的第一帧图像。
-
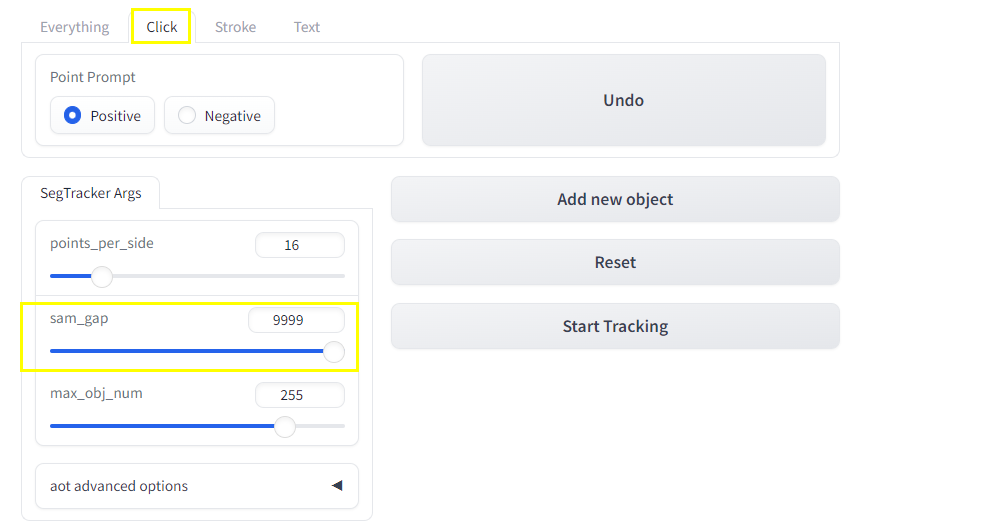
第一步点Click这个功能,把gam_gap拉到最大,然后点击Reset:
-
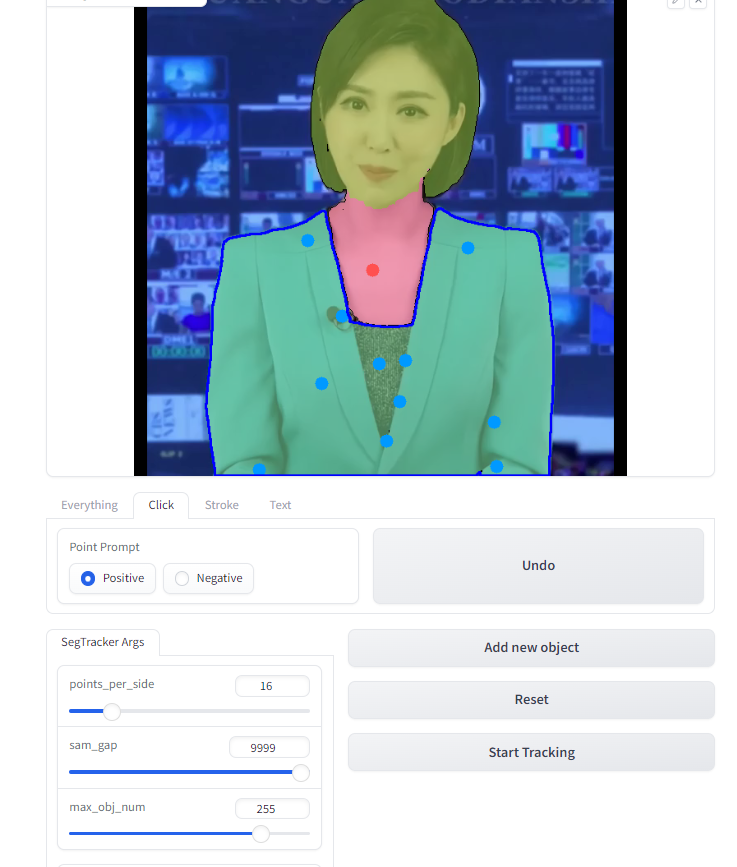
第二步,使用鼠标点击要分割部分,Positive是选择扩展区域,Negative是删除区域,Undo是撤消上一步操作。
-
选择完成一个部分之后,点击Add new object添加新的部分,在这个项目中,总共有三个部分,分别是头部,脖子,身体。
-
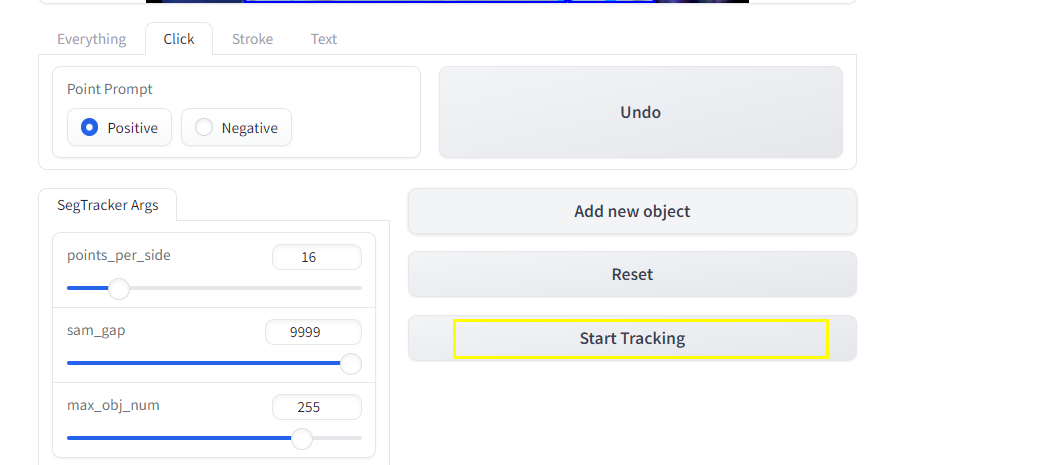
当所有的部分都分割完成之后,点Start Tracking开始对目标进行目标追踪。
-
项目会运行一段时间,时间长短取决于视频的长短,运行完成之后,在项目目标下,可以找到追踪分割出来的mask图像:

三、合成数据
分割完成之后,可以看到最终分割结果比源码自带的效果要好很多,但要改成NeRF要的颜色格式,就是头部用蓝色表示,脖子用绿色表示,身体部用红色表示,背景部分用白色表示。
1.获取颜色值
这里要获取分割出来的颜色值,才能把它改成想的颜色值,使用python和cv2实现点击获取颜色值:
def mouse_callback(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
# 获取鼠标点击处的像素颜色
pixel_color = cv_src[y, x]
b, g, r = pixel_color
print(f"颜色值 (B, G, R):({
b 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











