







VoiceCraft: 实现语音编辑和合成的 SOTA
论文地址:https://arxiv.org/html/2403.16973v1
源码地址:https://github.com/jasonppy/voicecraft
本文介绍VoiceCraft 的开发情况,它在语音编辑和零点语音合成 (TTS) 方面都实现了 SOTA。在本文中,文本到语音(Text-to-Speech)被描述为 TTS,与本论文一致。
研究要点包括
- **问题集:**为语音编辑和零镜头语音合成(TTS)开发统一模型。
- **解决方法 1:**提出了一种标记补充神经编解码语言模型 VoiceCraft。
- **解决方法 2:**在语音编辑和语音合成任务中学习和评估 VoiceCraft。
- **要点:**VoiceCraft 可按照最高行业标准进行语音编辑和合成。
换句话说,VoiceCraft可以实现非常自然的语音编辑,与示例语音样本毫无区别,同时在零镜头 TTS 方面优于以前的先进模型。

顺便提一下,VoiceCraft 的代码和模型权重可在 GitHub 上获取,目的是促进语音合成和人工智能安全方面的研究。
研究背景
神经编解码语言模型
近年来,人们利用神经编解码语言模型对语音合成进行了大量研究。
神经编解码器语言建模是一种与语言生成相同的语音生成方法,它将语音信号转换为离散的标记序列,并将语言模型应用于该序列。
它的独特之处在于,它不使用旋律谱图作为中间表示,而是使用语音标记。
零镜头 TTS 和音频编辑
Zero-shot TTS 与转录类似,您可以输入"语音样本模型 "和要转录的文本。然后,人工智能会用样本语音读出您要转录的文本。
另一方面,语音编辑是指更改语音样本中的单词或短语,并将其自然朗读出来。在此过程中,有必要保持口音、语调等,而不改变语音的任何其他部分。
参考官方演示页面会更容易理解这方面的内容。
在 TTS 和语音编辑领域已开发出各种模型,但很少有模型能统一执行零点 TTS 和语音编辑。
此外,还缺乏 “更真实的语音数据”,包括各种口音、语言风格、录音条件和噪音。
VoiceCraft 的主要方法
VoiceCraft 通过对神经编解码语言模型 (NCLM) 的输出词块进行排序,以及随后由纯解码器变换器进行自回归序列预测,实现了语音编辑和 TTS。

代币分类程序分为两个步骤
- 因果掩蔽
- 延迟堆叠
第一种因果屏蔽法将连续语音波形作为输入,并使用 Encodec 对其进行量化。在训练过程中,X 标记的跨度会被随机屏蔽并移至序列的末尾。
下一步的延迟堆叠会移动矢量,使其成为一个对角取出元素的矢量,以便在 Y 中对时间 t 的代码集 k 进行预测时,以代码集 k-1 为条件。
使用变压器解码器建模
然后使用变换器解码器对生成的标记序列 Z 进行自回归建模。然后,将语音的 W 和 Z 的合并文本作为条件输入。
语音编辑任务推理的特点是识别要编辑的跨度,并使用掩码标记进行自回归掩码估计。
而 "零镜头 TTS "则是将提示音频、文本和目标文本串联起来。
这两种情况的关键在于,考虑到双向语境,使用标记重排技术可以实现自然语音合成。
VoiceCraft 与现有模式的对比
在本研究中,我们进行了与现有模型的对比实验,以测试VoiceCraft 在语音编辑和零镜头 TTS 任务中的性能。
音频编辑实验
特别是在这里,它通过 "更真实的语音数据 "进行了验证,包括各种口音、说话风格、录音条件和背景噪音。
具体来说,作者在语音编辑任务中使用了一个新创建的数据集REALEDIT,该数据集包含从有声读物、YouTube 视频和播客中收集的 310 个实际录音,需要编辑的文本长度从 1 到 16 个单词不等。需要编辑的文本长度从 1 到 16 个单词不等。

验证将 VoiceCraft 与现有最佳性能模型 FluentSpeech 进行比较。WER 用作定量指标,MOS(平均意见分数)用作定性评估。
结果如下
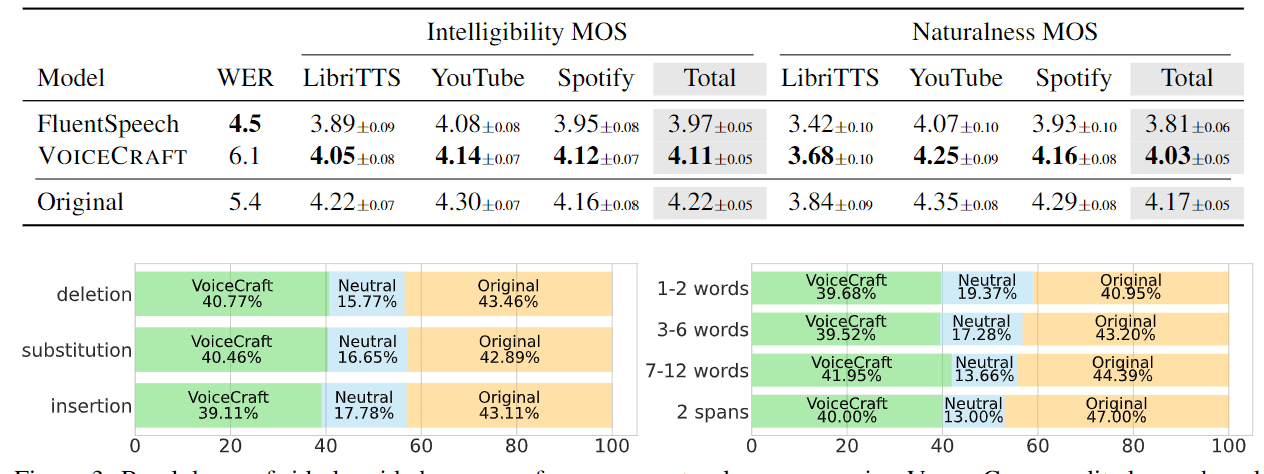
VoiceCraft 在所有 MOS 方面都优于 FluentSpeech。
此外,使用 VoiceCraft 编辑的音频在 48% 的情况下与人类编辑前实际录制的音频没有区别。
零镜头语音合成(TTS)实验
在这里,VoiceCraft 与 VALL-E、XTTS v2、YourTTS 和 FluentSpeech 进行了比较。
WER 和 SIM(与原配音者声音的相似度)用作定量指标,MOS 用作定性评估。
结果如下

VoiceCraft 在 SIM 和所有 MOS 指标上都优于其他型号。
VoiceCraft 是语音合成领域最先进的模型
这篇文章介绍了 VoiceCraft 在语音编辑和零镜头语音合成 (TTS) 方面实现 SOTA 的工作。
这项研究的局限性之一是,在生成过程中可能会出现长时间沉默和划痕噪音。
此外,他还指出,随着语音合成技术的进步,语音伪造和滥用的风险也在增加,这就要求对 VoiceCraft 等模型的水印和深度伪造检测进行更多研究。
总结
随着VoiceCraft代码和模型的公开,预计将进一步改进模型性能,并在 VoiceCraft 的基础上开发创新模型。
另一方面,滥用的风险也不容忽视,例如通过伪造语音进行欺诈。毕竟,当你听到 VoiceCraft 生成的声音时,你无法将其与当事人(输入声音的所有者)的声音区分开来。
因此,人们担心欺诈案件的数量会增加,例如,某人 “伪装成本人,要求亲属将钱转入其账户”。
















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











