







引言
论文地址:https://arxiv.org/pdf/2409.11340
传统模型操作复杂,实用性有限,因为它们往往需要针对特定任务的结构和额外的网络;OmniGen 的设计旨在解决这一问题,因为它可以在一个模型中处理多种任务,这可能会对人工智能研究的未来产生重要影响。它有可能在未来的人工智能研究中占据重要地位。
一个具体的使用案例是,图像编辑和图像修复等复杂任务可以通过简单的指令来完成。因此,OmniGen 为图像生成开辟了新的可能性,我们期待着进一步的研究。
技术
OmniGen 结构非常简单,由两个主要部分组成:VAE(变异自动编码器)和变换器模型。
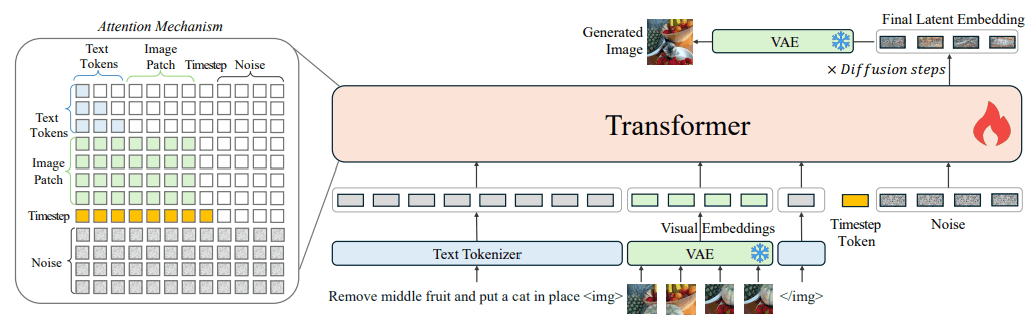
VAE 从图像中提取连续的视觉特征,而变换器则利用这些特征生成图像。这样就可以任意组合处理文本和图像输入,而无需额外的编码器。例如,图像编辑、姿态估计和边缘检测等任务都可以作为图像生成任务进行统一处理。
此外,OmniGen 还能在统一的数据集 "X2I "上学习各种任务,从而在不同任务之间共享和转移知识。

这使它能够灵活地处理未知任务和新领域,并表达传统任务特定模型所不具备的新功能。例如,基于视觉条件的生成可以生成新的图像,同时保留特定的对象和结构。

OmniGen 的一大优势是无需任何现有扩展或预处理即可生成各种图像。这使其易于应用于实际应用,操作直观。此外,与其他模型相比,OmniGen 的效率更高、效果更好,因为它只需较少的参数和训练数据就能获得同样或更好的效果。
试验
本文的实验评估了 OmniGen 在各种图像生成任务中的性能。具体来说,测试的任务范围很广,包括文本到图像的生成、图像编辑、基于视觉条件的图像生成以及传统的计算机视觉任务。
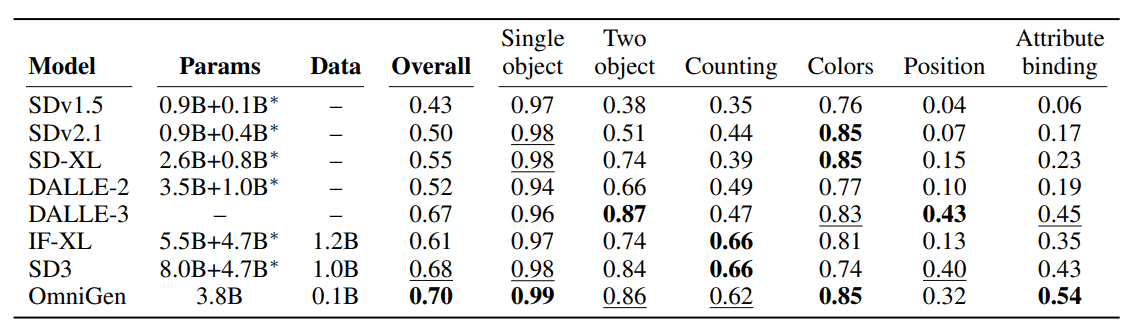
首先,在文本到图像生成的评估中,OmniGen 的表现不亚于或优于现有的扩散模型。评估指标衡量了生成图像的质量及其与文本的一致性,OmniGen 在参数和数据较少的情况下取得了优异的成绩。
其次,图像编辑实验表明,OmniGen 能够执行多种操作,如更改背景、添加和删除对象。特别是使用 EMUEdit 数据集进行的测试表明,OmniGen 在编辑准确性和与原始图像的匹配方面表现出色。

此外,还进行了实验,以评估根据视觉条件生成新图像的能力,如边缘检测和姿势估计。
最后,我们还评估了计算机视觉任务,如弱光图像改进、去毛刺和内绘,并整合了传统的视觉处理技术。这表明,OmniGen 不仅是一个生成模型,还能高效处理传统的计算机视觉任务。
总结
本文的结论表明,OmniGen 在各种图像生成任务中都表现出了卓越的性能,并可能大大超过现有扩散模型的极限。OmniGen 是第一个能够以统一的方式处理各种任务的模型,如从文本生成图像、图像编辑和视觉条件生成。OmniGen 是第一个可以统一处理各种任务的模型,如从文本生成图像、图像编辑和视觉条件生成。
展望未来,OmniGen 的性能有望进一步提高,并可应用于新的任务。特别是,图像生成的统一方法可在未来为更广泛的人工智能应用做出贡献。研究团队的目标是通过开源进一步开发 OmniGen。



















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











