









目录
概述
本章开始讲解如何进行测量,在算法优化的过程中,测量这个步骤是前提,也是一个基础,我们如何判断性能优化的快慢,是通过个人的感觉,或是通过个人的经验,还是用一套准确的工具测量出优化前后的差别呢?如果没有准确的数据支持的话,如果对性能的优化是30%或者50%,那也是很难让人承认的。在本章中,作者主要讲了两种工具,一种是编译器厂商一般都会提供的分析器,如果我们搜索gcc profiler 就会发现有很多中不同的分析器可供我们选择,在下面这个网页中,甚至罗列出了好几种。profiling - Good c++ profiler for GCC - Stack Overflow
第三种工具就是用纸笔记录下实验数据了,这种的不建议。
优化思想
性能测量是必须的
当我们对同一段代码进行多次修改的时候,以大部分人的脑力无法同时记住记录代码更迭以及每次更改之后的性能的,而当我们想要知道哪次的更改效果更好的时候,我们回头一想,哇这么多次的更改,到底是上上次还是哪一次呢?这个时候回头再做一遍测试,那真的是又多用了一遍的时间。所以我们在优化代码的时候,测量性能、记录更改,是一定要做到的。
90/10规则
在做性能优化的时候我们要谨记这一条规则--90/10规则,这个规则的意义就是,程序会花费90%的时间在其中10%的代码上面。程序中一部分的代码块是会被频繁的执行,这段代码称为热点(hot spot),而就像我们之前讲到的,对这种代码进行优化的意义要远大于其他部分代码的优化。识别这些代码,就需要我们之前提到的一些工具了,当然后面的文章也会详细讲到如何查找到这部分的代码。
阿姆达尔定律
阿姆达尔定律是由计算机工程先锋基恩•阿姆达尔(Gene Amdahl)提出并用他的名字命名的,它定义了优化一部分代码对整体性能有多大改善。阿姆达尔定律有多种表达方式,不过就优化而言,可以表示为下面的等式:
其中ST是因优化而导致程序整体性能提升的比率,P是被优化部分的运行时间占原来程序整体运行时间的比例,SP是被优化部分P的性能改善的比率。
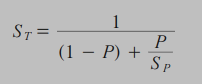
简单的计算一下,假设一个程序原本运行时间100s,其中的80s调用了函数f。如果我们把f进行优化,让其速度提生了30%,那么对于整体的程序而言,它的运行时间有多大的改善呢?
首先我们把P = 0.8 替换进去,然后Sp应该是f函数的改善的比率,也就是1+30% = 1.3 ,然后带入公式St = 1 / ( 1 - 0.8 + 0.8 / 1.3 ) = 1.22 .
通过这个公式,我们可以知道,P所占的比率越高,对它进行优化所产生的总体效果越好,如果P只占了0.1 , 那么我们即使把它的速度提高100倍,那对于整体的程序而言,也只是优化了1.11倍的提升。
测量代码的运行时间
如果我们的程序是计算密集型程序,也就是说大部分的时间都在执行某些计算任务上面,这样我们通过分析器可以很简单的分析出某一个函数是频繁调用且执行时间很长的,但是如果我们的程序是一个用户的客户端程序,可能它没有很多的计算任务,但是它总是有一些卡顿的情况,这时候就不是通过寻找热点函数能够解决的问题了。程序有时候会花费很多的时间进行等待IO操作或者是一些外部事件,这从侧面来说增加了程序的运行时间,从而降低了性能。对于这种程序,我们需要首先测量出程序中每个部分的时间,然后将其中运行时间长的试着进行优化。
关于测量时间
在时间的测量中,可能我们想到的就是Clock()获取两次时间进行相减运算,得出来的就是中间的差值。但是这其中是不是有偏差?偏差可能来自哪里?这次的数值到底是不是这正确的?这些都需要我们对系统时间有一些深入的了解。
首先我们要明白几个概念:
可变性
可能破坏完美测量的误差源。可变性有两种类型:随机的和系统的。随机的可变性对每次测量的影响都不同,就像一阵风导致弓箭偏离飞行线路一样。系统的可变性对每次测量的影响是相似的,就像一位弓箭手的姿势会影响他每一次射箭都偏向靶子的左边一样。
精确性
如果测量不受随机可变性的影响,它就是精确的。也就是说,如果反复地测量同一现象,而且这些测量值之间非常接近,那么测量就是精确的。

正确性
如果测量不受系统可变性的影响,它就是正确的。也就是说,如果反复地测量同一现象,而且所有测量结果的平均值接近实际值,那可以认为测量是正确的。

测量分辨率
测量的分辨率是指测量所呈现出的单位的大小。

用计算机测量时间
在没有看这本书以前,我的想法是很天真的,那就是计算机内置的时钟具有很好的精密性,以至于只要在开始的时候调整好时间,那么它在以后基本都不用再管了,因为它的精确性很好。但是实际上,PC时钟电路的核心部分的晶体振荡器的基本精度是100PPM,即0.01%,或者每天约8秒的误差。这个跟我手上的机械表好一些,机械表每天三分钟之内的误差,害得我还得每天起床对一下时间。PC的时钟精度要高一些,对于我们的性能测试来说,其实也是够用了,
自Windows 8开始,Windows提供了一种基于TSC的、可靠的、高分辨率的硬件时标计数。只要该系统运行于Windows 8或者之后的版本上,void GetSystemTimePreciseAsfileTime(fiLETIME*)就可以生成一个固定频率和亚微秒准确度的高分辨率时标。
分辨率不是准确性
我们需要注意一点的就是,某个函数的分辨率可能是很小,比如GetTickCount()它的分辨率是1ms,如果我们写这么一个函数:
auto start_time = GetTickCount();
for( int i = 0 ; i < 10 0000 ; i ++){
Do_Some_Calculate();
}
auto end_time = GetTickCount();
cout << "10 0000 calls to Do_Some_Calculate() took " << end_time - start_time << "ms" << endl;我们得到的结果可能是5ms , 10ms 之类的,但是这个结果我们可以使用吗?虽然GetTickCount()函数的分辨率是1ms,但是打开官方的文档可以看到,调用GetTickCount()的准确性可能是10毫秒或15.67毫秒,也就是说不管两次调用GetTickCount()中间有没有其他耗时的操作,这两次GetTickCount()返回值的差可能是15.67以内的任何一个数值,所以这个函数的精确度是15毫秒,而不是1ms。而且它返回的这个数值也是在某个数量级之内可以用,如果计算代码耗时50 000 ms,那么相对于50 000ms来说,15ms的差距有或者没有都相差不大,所以在这种数量级下我们是可以认为这个时间计算是准确的,但是如果是在20ms这个量级里面呢?那当然是不建议使用的。
测量时间获取函数的精确度
刚才我们提到了,如果一个函数的精确度不是很高的话,那么这个函数在什么情况下进行使用就需要仔细斟酌了。可能我在这个项目中可以使用这个函数来测量时间,但是在另一个项目中它就不适合了,那我们使用的时间获取的函数,它的精度到底是怎么样呢?我们如何能获取到呢?答案就是我们可以从官网、从库的文档中、或者是自己手动写一个函数进行测量。
unsigned nz_count = 0 ,nz_sum = 0;
ULONG last, next;
for (last = GetTickCount(); nz_count < 100; last = next) {
next = GetTickCount();
if (next != last) {
nz_count += 1;
nz_sum += (next - last);
}
}
std::cout << "GetTickCount() mean resolution "<< (double)nz_sum / nz_count << " ticks" << std::endl;创建StopWatch类
我们希望在代码中有这么一个类能帮助我们进行测试,我们可以让他自动的开启销毁,然后能告诉我们这中间执行了多久,
{
StopWatch Sw(true);
Do_Some_Calculate();
}
或者我们可以手动开启让它开始,然后多次调用获取时间节点。
{
StopWatch Sw("MultyTimes catch");
Sw.start();
Do_Some_Calculate1();
Sw.ShowMsFromStart();
Do_Some_Calculate2();
Sw.ShowMsFromLastTime();
}更多相关代码查看Github
评估代码开销来找出热点代码
通过分析器或者StopWatch,我们能够知道哪一部分的代码运行了很长的时间,这两种方式是找出热点代码段的好方法。他们虽然能够指出热点代码,但他们不太可能直接告诉你,哪一句代码需要修改。而我们通过各种各样的方式获取到热点代码段之后,就距离我们的目标很近了,剩下的就是我们需要从这一部分的代码中评估每一句的开销,从里面找出开销大的语句或者语法结构。注意,不仅仅是语句可能会造成很大的开销,有时候语法结构也是造成很大开销的关键!
评估独立的C++语句的开销
之前我们分析过,当调用系统相关的API的时候或者访问内存的时候,产生的开销是要远远大于执行指令的开销,两者差了好几个量级,
有一条有效的规则能够帮助我们评估一条C++语句的开销有多大,那就是计算该语句对内存的读写次数。例如,有一条语句a = b + c;,其中a、b和c都是整数,b和c的值必须从内存中读取,而且它们的和必须写入至内存中的位置a。因此,这条语句的开销是三次内存访问。这个次数不依赖于微处理器的指令集。这是语句不可避免的、必然会发生的开销。
再比如,r = *p + a[i];这条语句访问内存的次数如下:一次访问用于读取i,一次读取a[i],一次读取p,一次读取*p所指向的数据,一次将结果写入至r。也就是说,总共进行了5次访问。
这是一条很重要的启发式规则。在实际的硬件中,获取执行语句的指令会发生额外的内存访问。不过,由于这些访问是顺序的,所以它们可能非常高效。而且这些额外的开销与访问数据的开销是成比例的。编译器可能会在优化时通过复用之前的计算或是发挥代码静态分析的优势来省略一些内存访问。单位时间内的开销也取决于C++语句要访问的内容是否在高速缓存中。
评估循环的开销
由于每条C++语句都只会进行几次内存访问,通常情况下热点代码都不会是一条单独的语句,除非受其他因素的作用,让其频繁地执行。这些因素之一就是该语句出现在了循环中。这样,合计开销就是该语句的开销乘以该语句被执行的次数了。
识别出隐式循环
响应事件的程序(例如Windows UI程序)在最外层都会有一个隐式循环。这个循环甚至在程序中是看不到的,因为它被隐藏在了框架中。
识别假循环
不是所有的while或者do语句都是循环语句。
do {
if (!operation1())
break;
if (!operation2(x,y,z))
break;
} while(0);如上的代码只是一个简单地if/else 分发的代码。















 831
831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









