







原文:https://arxiv.org/abs/1703.10025
代码:https://github.com/msracver/Flow-Guided-Feature-Aggregation
摘要:
现存的性能最好的图像目标检测算法直接应用到视频上,仍有一些困难。性能退化的原因有运动模糊、相机散焦、不太常见的外观等。现有的工作一般是在检测结果输出后再应用帧间信息,这种做法的一个缺点是不能做到端到端。本文提出了光流导向的特征集成方法,不仅提高了精度而且实现端到端视频目标检测。在特征级进行帧间信息融合,提高了每帧特征图的质量,也就提高了检测精度。本文方法在VID数据集上相比单帧应用检测器达到的效果有显著提升,尤其当目标快速运动的时候。并且在VID 2016的比赛上是最好的适应工程应用的算法。
- 引言:
如上所述,视频目标检测面临目标快速运动、相机散焦、物体外观变化等问题,直接使用图像目标检测器并不能获得很好的结果。比较流行的做法是,首先使用图像目标检测算法,得到每帧的box,然后做后处理将帧间的信息集成起来,后处理的方式有运动估计、光流,手工关联等。不能做到端到端学习,而且并不能提高检测质量。本文希望通过帧间信息集成提高单帧的特征质量。由于同一个实例的不同帧之间的运动,使得特征并不会对齐,直接集成反而会恶化特征图。如Table1(b)所示,这表明对运动建模是必要的。本文提出,光流导向的特征集成方法(Flow-guided feature aggregation FGFA)如Feature 1所示
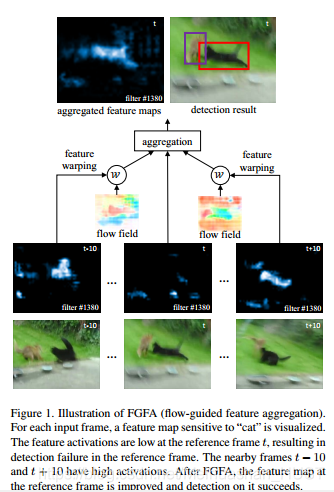
首先,图像目标检测器对每一帧图像进行计算得到特征图,然后光流网络估计前一帧与后一帧相对本帧的运动,根据估计的运动,前后两帧特征图映射到本帧与本帧进行自适应权重融合,权重值根据权重网络得到。最后融合后的特征图送入检测网络,得到本帧的检测结果。上述的特征提取网络、光流网络、融合网络以及检测网络可以进行端到端训练。
相比后处理的网络,本文提高了特征图质量,端到端训练,对于单帧的检测结果有较大提升。在VID数据集上获得了较好的效果,其中对快速运动的目标的检测的提高占据提升的大部分比重。 - 相关工作:
图像目标检测。RCNN->Fast RCNN->Faster RCNN->R-FCN的发展路线,视频目标检测依赖于图像目标检测的发展。
视频目标检测。几乎所有的现存的工作都是对图像目标检测做后处理。T-CNN[sensetime 2016 CVPR]根据计算的光流,预测下一阵的box的位置,应用跟踪算法产生目标管道沿着管道的box重新打分分类。Seq-NMS做法类似。MCMOT[2016 ECCV]将后处理形式化为多类多目标的跟踪问题,使用一系列的手工特征,比如检测置信度,颜色运动特征,变化点检测,前向后向验证等,用于确定box是否属于跟踪的目标,进一步再精调跟踪结果。不幸的是,这些做法都是多阶段的流水线,每一个阶段的结果依赖于上一个阶段,上一阶段的误差带来的误差很难矫正。相比之下,我们的帧间信息的利用,在特征图级,而不是最终的box级,整个系统端到端训练,另外,在我们结果输出后,可以再使用box级的方法。
光流估计运动。FlowNet[2015 ICCV],FlowNet 2.0[2017 CVPR].Deep Feature Flow[2017 CVPR],DFF前面根据视频信息的冗余性,使用光流进行加速,本文着眼于使用光流进行特征的融合。
特征融合。特征融合广泛应用于行为识别和视频描述中,这部分工作一般是两条路线,一条是RNN进行融合[34,24,47,7,46,1,9,35],一条是使用时空卷积[38,21,41,42]。然而在这些工作中,卷积核的大小可能限制快速运动物体的建模,可以考虑大卷积核,但是参数增加会带来过拟合和计算开销的问题。相比之下本文的光流导向集成特征可以适应不同大小的特征。 - 光流导向的特征集成
3.1 baseline与motivation
目标检测器一般有相似的结构,一个特征提取器f=Nfeat(I),一个检测器y=Ndet(f)。同一个实例的不同帧上会有不同的表现,如figure2所示

直接使用目标检测器会得到不稳定的结果。比如figture1中猫的运动模糊,使得特征图的响应并不强,这时候会漏检,但是观察他的前10帧后10帧,特征图响应较强,如果用他们增强本帧的特征图,那么在本帧也能检测出猫。在这个流程中必须的两个模块为,运动估计后的特征映射模块和特征集成模块。
3.2 模型设计
光流导向的映射
给定参考帧i与临近帧j,采用Flownet估计从i到j的运动Mi->j,根据这个估计,临近帧特征映射到参考帧,映射函数为

其中W代表双线性插值,F(Ii,Ij)为光流网络对帧Ii和帧Ij的输出(运动估计)
特征集成
特征映射之后,进行特征集成,不同帧的同一个实例,在光照、视角、姿势等方面是不同的需要用不同的权重将他们累加起来,有点像注意力机制,着重看不同的地方
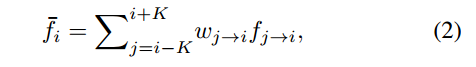
这里K表示集成的帧数范围一般设置模型的10.最终集成后的目标,送入检测网络,得到最终的检测结果
权重自适应
根据j帧映射像素fj->i§的位置与i帧像素fi§的距离,去调整权重,距离越近,权重越大,这里的距离为余弦距离,以p处的高维特征为输入,余弦距离为输出,得到权重
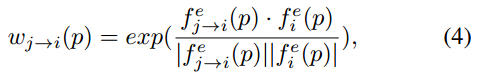
注意这里的f有上标e,表示,p处的特征不是直接进行距离计算的,而是先进入一个小网络E进行调整,再输出计算距离。并且wj->i§是归一化的。
3.3 训练与测试

测试。像Algorithm1所示,输入视频序列I{1,2,3…},对其中的前K+1帧直接提取特征,初始化特征缓冲区。从第1帧开始,对前K和后K帧进行根据光流特征映射,输入权重网络E得到每帧特征调整值,调整之后根据余弦距离计算此帧的权重,这2K+1帧进行融合后,对融合结果进行检测。复杂度如下式
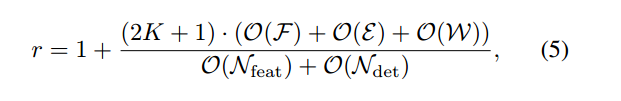
相比直接提取特征检测,多计算了2K+1帧的光流估计,权重网络计算和映射插值。主要多出来的就是光流的计算。
训练。这里添加了双线性插值模块,这个计算是可微的。在训练的过程中K限制了内存的使用。我们采用一个大的K(=10)去预测,用一个小的K(=2)去训练。K=2的帧号,在一个大K的范围内随机选择。等效于选了一个大的K,并且属于dropout,在后面的实验中,显示了这是一个好的策略
3.4 网络结构
光流网络。采用FlowNet做为光流估计网络,FlowNet在fly chairs dataset上做预训练,输入降采样后的图像,输出的步长为4,由于下面特征提取网络步长为16,所以我们将最终光流的输出降采样
特征网络。ResNet-50、ResNet-101、和Aligned-Inception-ResNet在ImageNet上预训练。并做了一些修改,步长从32变为16
权重网络。三层11512,33512和112048的卷积网络
检测网络。R-FCN - 实验
在VID数据集上进行实验,此数据集包含30类,训练集有3862个视频,测试集有555个,每个视频是25fps或者30fps.
为了更好得分析,本文根据帧间的IoU将数据集分成,快速、中等和慢速三类,score>0.9 慢速 score在0.7和0.9之间为中等 score<0.7为快速。数据集的不同速度目标的分布,如Figure 4所示
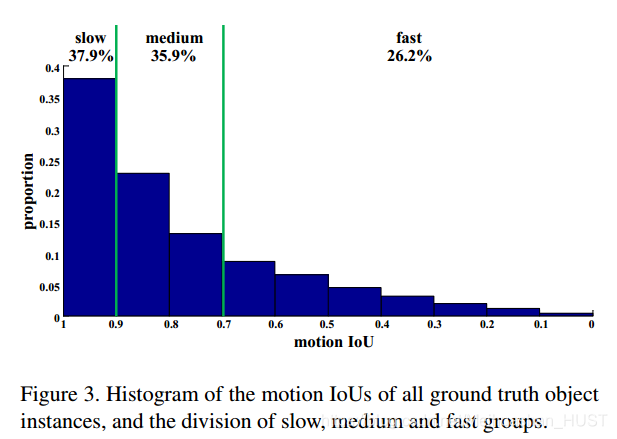

实现细节,特征提取与检测网络,首先在ImageNet DET数据集上预训练,然后FGFA模型在VID数据集上训练,图像短边resize到600。
对比实验

直接使用R-FCN得到73.4的分数,单独评估慢速的为82.4,评估快速的为51.4说明快速的目标检测效果很差,本文也研究了目标大小的影响
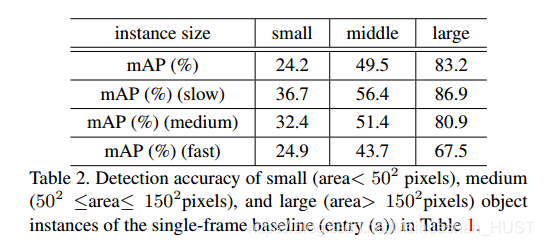
从这里可以看出,小目标的检测性能也很差,快速运动的小目标只有24.9,他整体的73.4的分数太偏向与慢速和大目标的情况,中等及以下大小和速度的目标检测能力远低于他的平均水平。(b)为不考虑运动和权重自适应的情况,不论总体下降,快速目标显著下降。所以,不进行运动对齐,直接集成是有害的,会造成特征图混乱。©为添加权重自适应,添加之后,超过了baseline,快速目标上也有较大提升,说明权重自适应同样重要。(d)是加入光流的结果,快速目标检测能力进一步提升。从Table1就能看出来,对于越快的目标,这种方法越有效,慢的目标,每帧的特征图都不错,所以提升不大,快的目标,恶化严重需要集成,而且需要光流对齐的自适应集成。在视频检测中,小目标快速目标是制约检测能力的关键。同时评估了时间,由于多帧光流的计算,时间从单帧的200ms,增大到700ms。
横向比较。和MGP与Tubelet要好一些,比Seq-NMS[2015 VID 3th]要差一些,同前两者结合使用并没什么提升,和后者使用提升到78.4.和当下最好的工作比较,并不占优势,但是实现了端到端学习,2016年VID冠军为“Efficient object detection from videos”分数为81.2,但是使用了很多技巧,本文和Seq-NMS结合使用就达到了80.1. 同时比较好工程化 - 总结展望
结合清量的光流网络,提升快速目标的检测(现在只有55),自使用的集成策略。














 2426
2426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









