






STAR: A Structure-aware Lightweight Transformer for
Real-time Image Enhancement
用于实时图像增强的结构感知轻量级Transformer
发表于2021ICCV
make trade-offs between model flexibility and computation efficiency:在模型灵活性和计算效率之间进行权衡
摘要
不同于之前使用非常深的CNN和大的Tranformer结构,提出一种结构感知的轻量型Transformer,用于实时图像增强,捕获patch块之间的长距离依赖关系。STAR是一种通用架构,使用不同的图像增强任务。
介绍
问题:1 在非常有限的计算预算内高效地处理高分辨率图像,在模型灵活性和计算效率之间进行权衡。
2 需要结合输入图像的结构和全局信息,以获得高质量的稳定结果,特别是对于彩色图像等任务.
先前解决这两个问题的工作:
1.基于堆叠较深的CNN,具有较大的计算成本和内存占用
2.估计一组全局调整函数,缺乏处理真实场景复杂性的灵活性。
3.使用分割网络将图像划分为语义上有意义的区域,并分别处理,需要使用按像素标注的数据集
提出改进:
STAR基于transformer模块,主要包含MSA和FFN,避免了卷积模块的堆叠,能更有效的提取结构信息。在STAR中图像块被embedding成一个个token,与直接计算像素之间的依赖不同,STAR直接学习token之间的依赖关系。也可以隐式地学习语义结构,从而比CNN提供更多的有意义的语义结果。
作者提出了一个特殊设计的双路long short Range Transformer确保STAR能够集中在捕获图像全局上下文信息(global contexts)并且减少计算量
方法
剩余的看其他人的csdn了 代码打算跑一下
不行他写的太简略了我还是继续写吧
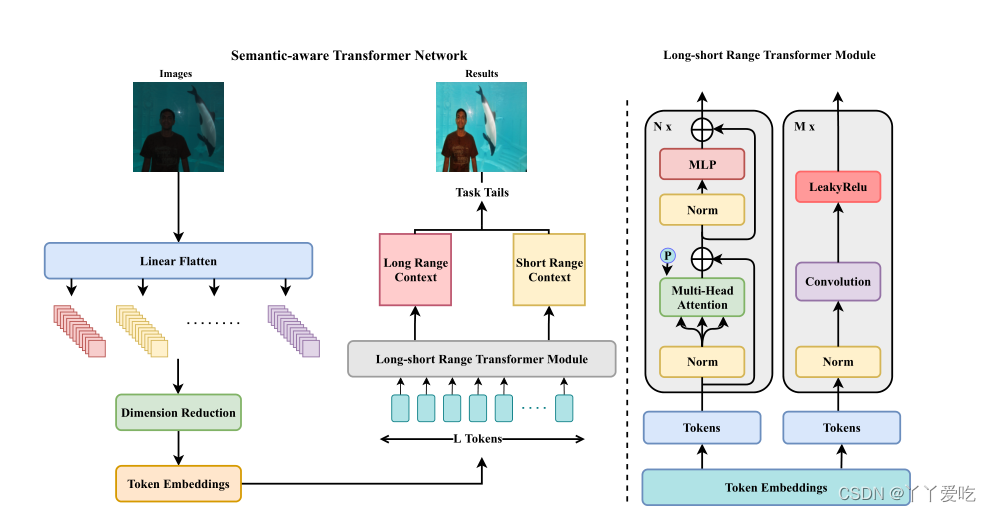
STAR整体结构如图所示,首先将图
I
∈
R
H
×
W
×
C
I
\mathbf{I} \in \mathbb{R}^{H \times W \times C_{I}}
I∈RH×W×CIembedding为token序列
I
T
∈
R
L
×
C
T
\mathbf{I}_{T} \in \mathbb{R}^{L \times C_{T}}
IT∈RL×CT输入到long-short rangeTransformer模块,经过long-short rangeTransformer模块输出两个structal map
S
1
S
2
S1 S2
S1S2,然后,预测的两个结构map可以用于进一步估计图像增强任务的曲线或变换。
3.1 Tokenization
最常见的将图像转换成token序列的方式一个就是如IPT里将图像展平成图像块(i.e.,这样会导致大量的内存消耗,并且输入的token向量维度太大,需要大量的参数来训练(IPT,33M)。另一种方式是从CNN的feature map中获取输入token,这种情况下在经过CNN对空间分辨率下采样后patch size可以为1×1。
为减少计算量,达到实时图像增强效果,如上图,作者先将全尺寸图片展平为图像块序列,然后再对图像块做维度缩减,之后再通过可学习的线性embedding层对每个图像块提取token。
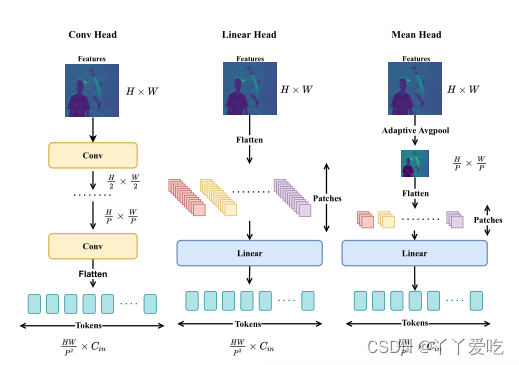
本文比较了三种tokenization的方法,如图所示,第一种Linear Head,vit和ipt中使用的,将图片分成patch后再通过线性embedding,计算量太大。第二种Conv Head,通过卷积层和下采样将空间分辨率降低。token序列就是将低分辨率的feature map展开。第三种Mean Head通过Adaptive Average Pooling来降低空间分辨率,极大地减少了产生token的复杂度和计算量。
3.2. Long-short Range Transformer Module
Long-short Range Transformer模块有两条支路,一条卷积一条Transformer,卷积处理各图像块short range之间的依赖关系,Transformer处理各图像块long range之间的关系。作者将token embedding分成两部分分别输入卷积和transformer支路(但是公布的代码好像两边都是全输进去的),具体结构减图一以及文章和公布的代码。
4 使用STAR的增强
4.1照明增强
在2020年zero-dce这篇文章(cvpr),为了评估我们的方法,我们用提出的STAR替换了CNN主干,
其他的参考文章。
5 实验
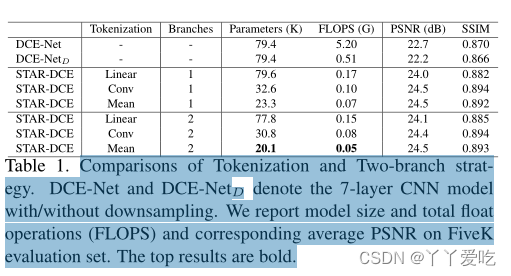
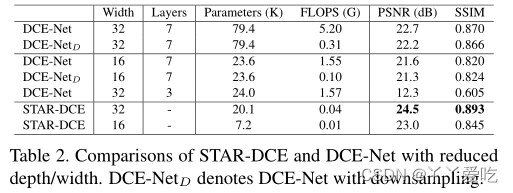















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









