









1、线性正则化
降低线性回归的损失函数,大的系数会造成过拟合,为每个特征变量选一个系数,当某一变量的系数过大时,会使预测偏向该特征,因此损失函数会惩罚(penality)大的系数(绝对值大),这就叫正则化。
代价函数 = 均方误差 + 惩罚函数
均方误差:使训练误差变小
惩罚函数:使参数绝对值变小 (是惩罚参数)
惩罚函数常见的是L1和L2范数函数:
代价函数:![]() (L2正规,岭回归)
(L2正规,岭回归)
![]() (L1正规,套索回归)
(L1正规,套索回归)
2 岭回归(Ridge regression)
- Loss function = OLS loss function +
- OLS :Ordinary Least Squares,普通最小二乘法 OLS loss function =
OLS复杂度:
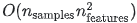
- Alpha: 需要调节的参数(超参调节),控制模型复杂度, 类似于KNN里选择K
- Alpha =0时,得到OLS,会导致过拟合(overfitting) ; Alpha非常大时,w趋近于0,会导致欠拟合(underfitting);Alpha愈大,对系数大小的惩罚越强
是单位矩阵(identity matrix )
from sklearn import linear_model
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.model_selection import cross_val_score
sns.set()
# 绘制标准误差和Alpha图
def display_plot(cv_scores, cv_scores_std):
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(alpha_space, cv_scores)
std_error = cv_scores_std / np.sqrt(10)
ax.fill_between(alpha_space, cv_scores + std_error, cv_scores - std_error, alpha=0.2)
ax.set_ylabel('CV Score +/- Std Error')
ax.set_xlabel('Alpha')
ax.axhline(np.max(cv_scores), linestyle='--', color='.5')
ax.set_xlim([alpha_space[0], alpha_space[-1]])
ax.set_xscale('log')
plt.show()
# prepare data
X = np.array([[34811059, 2, 0, 3, 24, 12314, 129, 29],
[19842251, 6, 2, 1, 22, 7103, 130, 192],
[40381860, 2, 0, 4, 27, 14646, 118, 15],
[2975029, 1, 0, 1, 25, 7383, 132, 20],
[21370348, 1, 0, 18, 27, 41312, 117, 5]])
y = np.array([75.3, 58.3, 75.5, 72.5, 81.5])
# setup the array of alphas and lists to store scores
alpha_space = np.logspace(-4, 0, 50)
ridge_scores = []
ridge_scores_std = []
# 创建岭回归器(regressor)
ridge = linear_model.Ridge(normalize=True)
for alpha in alpha_space:
# specify the alpha value to use
ridge.alpha = alpha
# 3-fold CV
ridge_cv_scores = cross_val_score(ridge, X, y, cv=3)
ridge_scores.append(np.mean(ridge_cv_scores))
ridge_scores_std.append(np.std(ridge_cv_scores))
display_plot(ridge_scores, ridge_scores_std)
## 广义交叉验证 generalized cross-validation,默认采用 leave one out cv
ridgecv = linear_model.RidgeCV(alphas=np.logspace(-4, 0, 50))
ridgecv.fit(X, y)
# RidgeCV(alphas=array([1.00000e-04, 1.20679e-04, 1.45635e-04, 1.75751e-04, 2.12095e-04,
# ..., 3.23746e-01, 3.90694e-01,
# 4.71487e-01, 5.68987e-01, 6.86649e-01, 8.28643e-01, 1.00000e+00]),
# cv=None, fit_intercept=True, gcv_mode=None, normalize=False,
# scoring=None, store_cv_values=False)
ridgecv.alpha_
ridgecv.score(X, y) # R2
# 网格搜索
from sklearn.model_selection import GridSearchCV
parameters={'alpha':alpha_space}
gridcv = GridSearchCV(ridge, parameters, cv=3)
gridcv.fit(X,y)
# GridSearchCV(cv=3, error_score='raise-deprecating',
# estimator=Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None,
# normalize=True, random_state=None, solver='auto', tol=0.001),
# fit_params=None, iid='warn', n_jobs=None,
# param_grid={'alpha': array([1.00000e-04, 1.20679e-04, 1.45635e-04, 1.75751e-04, 2.12095e-04,
# 3.55... 3.23746e-01, 3.90694e-01,
# 4.71487e-01, 5.68987e-01, 6.86649e-01, 8.28643e-01, 1.00000e+00])},
# pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
# scoring=None, verbose=0)
gridcv.best_score_
gridcv.best_params_ # {'alpha': 1.0}

岭回归 套索回归
3 套索回归(Lasso regression)
- Loss function = OLS loss function +
- 可以用来选取重要的特征,将不重要的特征变量的系数缩小(shrinks)为0
from sklearn.linear_model import Lasso
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
sns.set()
# prepare data
d = {'population': [34811059, 19842251, 40381860, 2975029, 21370348],
'fertility': [2.73, 6.43, 2.24, 1.4, 1.96],
'HIV': [0.1, 2, 0.5, 0.1, 0.1],
'CO2': [3.328945, 1.474353, 4.785170, 1.804106, 18.016313],
'BMI_male': [24.59620, 24.59620, 27.50170, 25.35542, 27.56373],
'GDP': [12314, 7103, 14646, 7383, 41312],
'BMI_female': [129.9049, 130.1247, 118.8915, 132.8108, 117.3755],
'life': [75.3, 58.3, 75.5, 72.5, 81.5],
'child_mortality': [29.5, 192.0, 15.4, 20.0, 20.0]}
df = pd.DataFrame(d)
X = df.drop(columns='life', axis=1).values
y = df.life.values
# Instantiate a lasso regressor: lasso
lasso = Lasso(alpha=0.4, normalize=True)
# Fit the regressor to the data
lasso.fit(X, y)
# Compute and print the coefficients
lasso_coef = lasso.coef_
print(lasso_coef)
df_columns = df.drop(columns='life', axis=1).columns
# Plot the coefficients
plt.plot(range(len(df_columns)), lasso_coef)
plt.xticks(range(len(df_columns)), df_columns.values, rotation=60)
plt.margins(0.02)
plt.show()也可将上述数据换掉:
from sklearn import datasets
diabetes = datasets.load_diabetes()
X = diabetes.data
y = diabetes.target
# 下面这两行替换Lasso案例绘图中的相应变量即可
df_columns = diabetes.feature_names
plt.xticks(range(len(df_columns)), df_columns, rotation=60)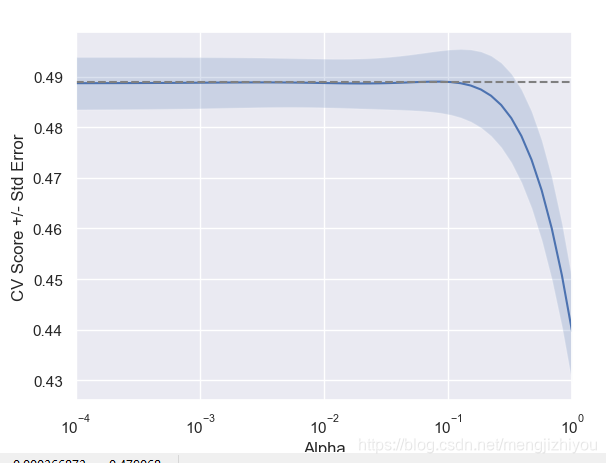

岭回归 套索回归
4 弹性网络回归(Elastic Net)
- 将岭回归(特征选取)和套索回归(稳定性)结合,这种组合可以让极少数的参数的权重不为0,类似Lasso
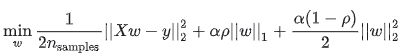
- 用 l1_ratio(
)参数来组合L1,L2,优点可以在岭回归和套索回归间继承岭回归的稳定性
from sklearn.linear_model import ElasticNet
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn import datasets
diabetes = datasets.load_diabetes()
X = diabetes.data
y = diabetes.target
# X, y = datasets.make_regression(n_features=2,random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
enet = ElasticNet(alpha=0.014, l1_ratio=0.5)
enet.fit(X_train, y_train)
y_pre_enet = enet.predict(X_test)
r2_enet = r2_score(y_test, y_pre_enet)5 岭回归与套索回归的比较
- 通常两者都不是很好
- 套索可以让一些参数为0,进行变量筛选,岭回归不可以
- 两种方法都允许使用相关的预测因子(correlated predictors),但它们解决多重共线性问题(multicollinearity issue)的方式不同:在岭回归中,相关预测因子的系数相似;在套索中,其中一个相关预测因子的系数较大,而其余的则(几乎)为零
- 如果有少量的重要参数,而其他参数接近于0,Lasso的表现就会很好(当只有少数几个预测因素响应时)
- 如果有许多相同值的大参数(当大多数预测因子都会响应时),Ridge工作得很好














 3701
3701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









