







2020.08.25更新: 修改了ROC曲线中TPR公式的错误。
2020.07.25更新: 修改了混淆矩阵,每一行为实际值,每一列与预测值。
机器学习分类问题指标理解
0. 一个例子
在分类(classification)问题的模型评估中,常用的评测指标有以下7个:
- 准确率(accuracy)
- 精确率(precision)
- 召回率(recall)
- F1-Score
- ROC曲线
- P-R曲线
- AUC面积
下面,通过著名的鸢尾花分类的例子来具体说明。
鸢尾花的特征有4个:
- Sepal Length(花萼长度)
- Sepal Width(花萼宽度)
- Petal Length(花瓣长度)
- Petal Width(花瓣宽度)
鸢尾花的种类有3种:
- Iris Setosa(山鸢尾)
- Iris Versicolour(杂色鸢尾)
- Iris Virginica(维吉尼亚鸢尾)
数据集中共150条数据,每类鸢尾花有50条数据。
选择KNN算法进行分类(欧式距离,K=8),得到模型的分类结果如下表所示(混淆矩阵[confusion matrix]):
| 预测为Iris-versicolor | 预测为Iris-virginica | 预测为Iris-setosa | |
|---|---|---|---|
| 实际为Iris-versicolor | 49 | 1 | 0 |
| 实际为Iris-virginica | 4 | 46 | 0 |
| 实际为Iris-setosa | 1 | 0 | 49 |
几个定义:
- TP(True Positive,真正):将正类预测为正类
- TN(True Negative,真负):将负类预测为负类
- FP(False Positive,假正):将负类预测为正类
- FN(False Negative,假负):将正类预测为负类
可以看出,前两个是我们期望出现的情况,后两个是期望不出现的情况。
1.准确率(Accuracy)
定义:正确分类的样本数与总样本数之比
a c c u r a c y = T P + T N T P + T N + F P + F N accuracy=\frac {TP+TN}{TP+TN+FP+FN} accuracy=TP+TN+FP+FNTP+TN
在上面的例子中,
a c c u r a c y = 49 + 46 + 49 49 + 4 + 1 + 1 + 46 + 0 + 0 + 0 + 49 × 100 % = 96.00 % accuracy=\frac {49+46+49}{49+4+1+1+46+0+0+0+49}×100\%=96.00\% accuracy=49+4+1+1+46+0+0+0+4949+46+49×100%=96.00%
准确率的概念很好理解,就是分类正确的比例,是一个非常常用的评估指标。但是,准确率高并不代表分类算法就好,当各个类别的样本分布很不均匀时,即使准确率达到99%也没用。
还是用上面的例子,如果Iris Setosa的样本数为98,Iris Versicolour和Iris Virginica的样本数都为1,那么,分类器只需要把结果全部置为Iris Setosa,就可以获得98%的正确率。所以,只靠准确率来评价一个模型的优劣是不全面的。
2.精确率(Precision)
定义:预测为正类的结果中,正确个数的比例
p r e c i s i o n = T P T P + F P precision=\frac {TP}{TP+FP} precision=TP+FPTP
在上面的例子中,每一列的数据可以计算一个精确率:
p
r
e
c
i
s
i
o
n
(
I
r
i
s
−
v
e
r
s
i
c
o
l
o
r
)
=
49
49
+
4
+
1
×
100
%
=
90.74
%
precision(Iris-versicolor)=\frac {49}{49+4+1}×100\%=90.74\%
precision(Iris−versicolor)=49+4+149×100%=90.74%
p
r
e
c
i
s
i
o
n
(
I
r
i
s
−
v
i
r
g
i
n
i
c
a
)
=
46
1
+
46
×
100
%
=
97.87
%
precision(Iris-virginica)=\frac {46}{1+46}×100\%=97.87\%
precision(Iris−virginica)=1+4646×100%=97.87%
p
r
e
c
i
s
i
o
n
(
I
r
i
s
−
s
e
t
o
s
a
)
=
49
49
×
100
%
=
100.00
%
precision(Iris-setosa)=\frac {49}{49}×100\%=100.00\%
precision(Iris−setosa)=4949×100%=100.00%
精确率又称查准率,其意义是判断模型的结果是否“找得对”。
3.召回率(Recall)
定义:实际为正类的样本中,正确判断为正类的比例
r e c a l l = T P T P + F N recall=\frac {TP}{TP+FN} recall=TP+FNTP
在上面的例子中,每一行的数据可以计算一个召回率:
r
e
c
a
l
l
(
I
r
i
s
−
v
e
r
s
i
c
o
l
o
r
)
=
49
49
+
1
×
100
%
=
98.00
%
recall(Iris-versicolor)=\frac {49}{49+1}×100\%=98.00\%
recall(Iris−versicolor)=49+149×100%=98.00%
r
e
c
a
l
l
(
I
r
i
s
−
v
i
r
g
i
n
i
c
a
)
=
46
46
+
4
×
100
%
=
92.00
%
recall(Iris-virginica)=\frac {46}{46+4}×100\%=92.00\%
recall(Iris−virginica)=46+446×100%=92.00%
r
e
c
a
l
l
(
I
r
i
s
−
s
e
t
o
s
a
)
=
49
1
+
49
×
100
%
=
98.00
%
recall(Iris-setosa)=\frac {49}{1+49}×100\%=98.00\%
recall(Iris−setosa)=1+4949×100%=98.00%
召回率又称查全率,其意义是判断模型的结果是否“找得全”。
4.F1-score
精确率和召回率是一对矛盾的指标,因此需要放到一起综合考虑。F1-score是精确率和召回率的调和平均值。
2 F 1 = 1 P + 1 R \frac {2}{F_1}=\frac {1}{P}+\frac {1}{R} F12=P1+R1
其中,P就是presicion,R就是recall,公式前面已给出。
故:
F 1 = 2 P R P + R = 2 T P 2 T P + F P + F N F_1=\frac {2PR}{P+R}=\frac {2TP}{2TP+FP+FN} F1=P+R2PR=2TP+FP+FN2TP
上式是当精确率和召回率的权值都为1的情况,也可以加上一个不为1的权值 β \beta β:
F
β
=
1
1
+
β
2
(
1
P
+
β
2
R
)
=
(
1
+
β
2
)
P
R
β
2
P
+
R
F_\beta=\frac {1}{1+\beta^2}(\frac {1}{P}+\frac {\beta^2}{R})=\frac {(1+\beta^2)PR}{\beta^2P+R}
Fβ=1+β21(P1+Rβ2)=β2P+R(1+β2)PR
当
β
>
1
\beta>1
β>1时,召回率有更大影响;
当
β
<
1
\beta<1
β<1时,精确率有更大影响。
5.ROC曲线(Receiver Operating Characteristic Curve)
再来2个公式:
- 假正率(False Positive Rate, FPR)
- 真正率(True Positive Rate, TPR)
F P R = F P F P + T N FPR=\frac {FP}{FP+TN} FPR=FP+TNFP
T
P
R
=
T
P
T
P
+
F
N
TPR=\frac {TP}{TP+FN}
TPR=TP+FNTP
显然,FPR越低越好,TPR越高越好。
在ROC曲线中,横坐标是FPR,纵坐标是TPR,下图就是例子中versicolor类的ROC曲线:
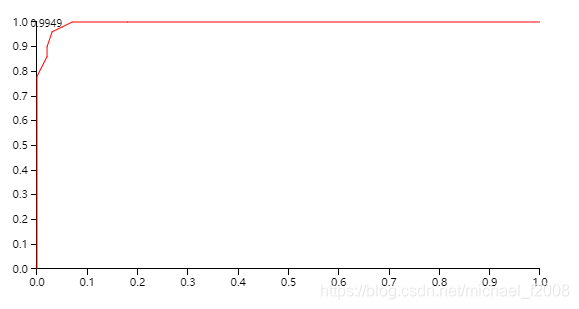
6.P-R曲线(Precision-Recall Curve)
在P-R曲线中,横坐标是recall,纵坐标是precision,下图就是例子中versicolor类的P-R曲线:
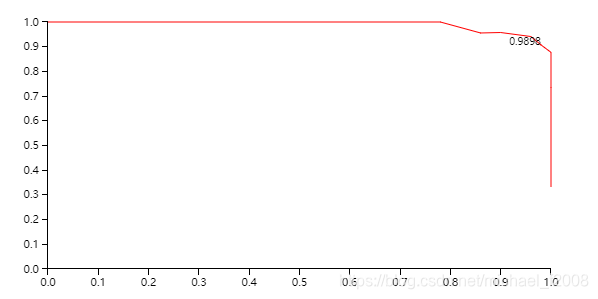
7.AUC面积(Area Under ROC Curve)
AUC面积表示ROC曲线下方的面积大小,通过积分就可以计算。AUC越大越好。
由于ROC曲线一般在
y
=
x
y=x
y=x直线的上方,故AUC一般为0.5~1.0。
以上是7个评估指标的简单理解,后面会对最后3个指标再做详细介绍。
To Be Continued…
欢迎关注我的微信公众号:


















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









