






【Video+Diffusion】是一个结合视频生成和扩散模型的研究领域,旨在通过先进的深度学习技术生成高质量、高分辨率的视频内容。这个方向利用扩散模型的强控制性和稳定性,通过逐步去除噪声并恢复数据,来生成逼真的视频序列。研究者们通过设计创新的框架和方法实现了从文本描述或图像提示到视频内容的高效转换,这些方法不仅提升了视频生成的效率和质量,同时也降低了计算资源的需求。这些技术的发展对于内容创作、娱乐产业、虚拟现实和增强现实等领域具有重要意义,它们提供了一种新颖的工具,使得用户能够以更直观、更个性化的方式进行视频创作和编辑。
为了帮助大家全面掌握【Video+Diffusion】的方法并寻找创新点,本文总结了最近两年【Video+Diffusion】相关的20篇顶会研究成果,这些论文、来源、论文的代码都整理好了,希望能给各位的学术研究提供新的思路。

三篇论文解析
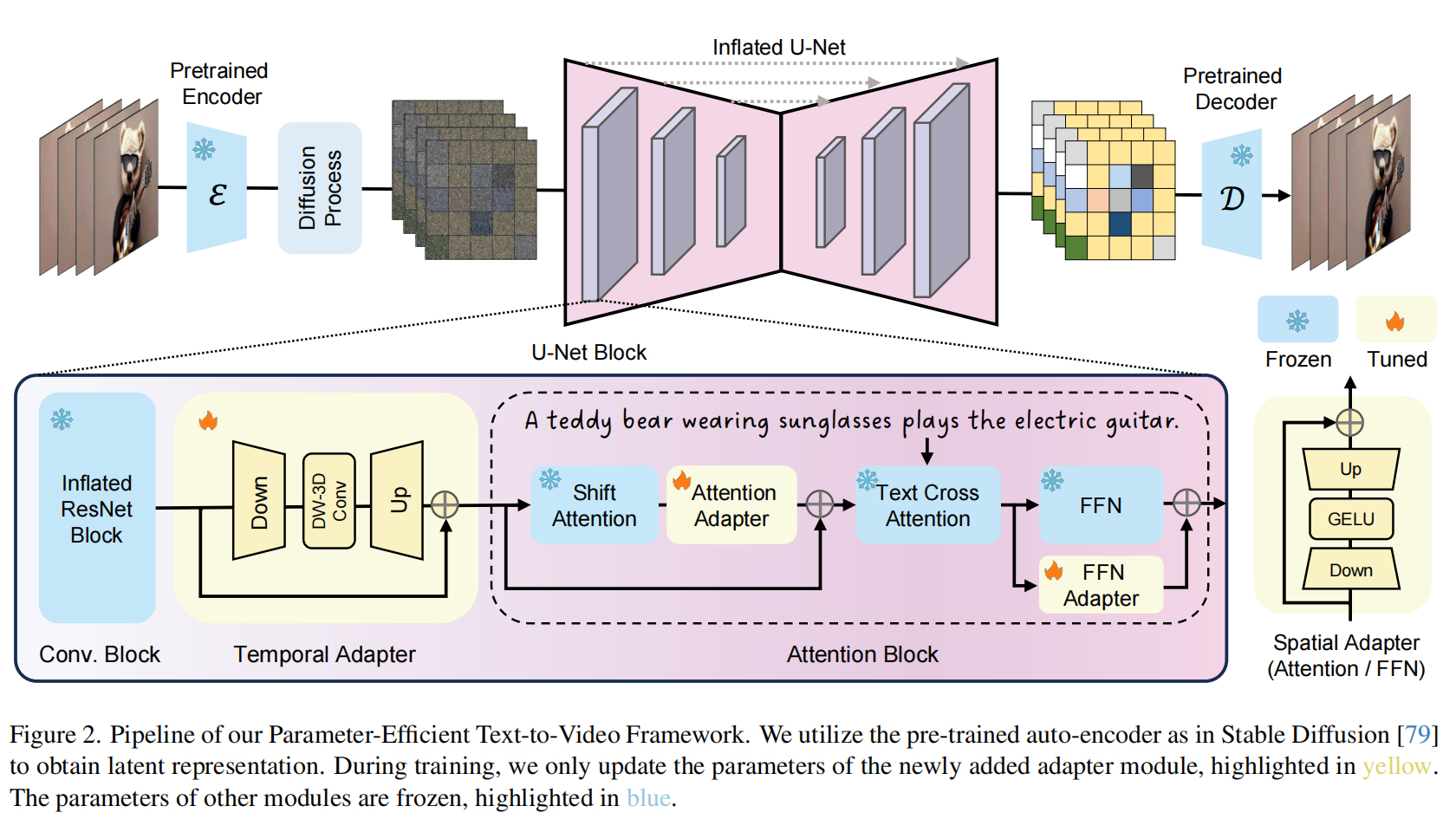
1、SimDA: Simple Diffusion Adapter for Efficient Video Generation
方法
-
SimDA提出了一种简单高效的视频生成模型,该模型基于文本到图像(Text-to-Image, T2I)技术的扩散模型。
-
该方法通过微调一个强大的T2I模型中的一小部分参数(仅24M参数,相对于1.1B的总参数),实现了对视频生成的适配,这是一种参数高效的适配方式。
-
设计了轻量级的空间和时间适配器,用于迁移学习,将T2I模型转换为T2V(Text-to-Video)模型。
-
引入了Latent-Shift Attention (LSA)机制,替换了原始的空间注意力机制,以增强时间一致性,且不增加新的参数。
-
利用与T2V生成模型相似的架构,进一步训练了一个视频超分辨率模型,以生成高清晰度(1024×1024)的视频。
-
在训练过程中,冻结原始的T2I模型,只调整新增加的模块,以减少训练工作量。
-
支持文本引导的视频编辑,仅需极少量的调整即可实现。
创新点
-
参数效率:SimDA通过仅微调T2I模型中的一小部分参数,实现了对视频生成的适配,显著减少了计算和资源消耗。
-
Latent-Shift Attention (LSA):提出了一种新的注意力机制,通过在潜在空间中进行时间维度的平移操作,提高了视频生成的时间连贯性。
-
视频超分辨率:将图像超分辨率框架扩展到视频领域,生成高清晰度视频,同时保持了模型的参数效率。
-
文本引导的视频编辑:SimDA能够进行一次性调整,实现文本引导的视频编辑,减少了训练步骤和时间,提高了效率。
-
训练与推理速度:通过上述方法,SimDA在保持竞争性能的同时,显著提高了训练和推理速度,特别是在与自回归方法CogVideo的比较中,推理速度提升了39倍。
-
模型扩展性:SimDA的方法不仅适用于开放域的文本到视频生成,还能够扩展到基于文本引导的视频超分辨率和视频编辑任务,显示出良好的通用性和扩展性。
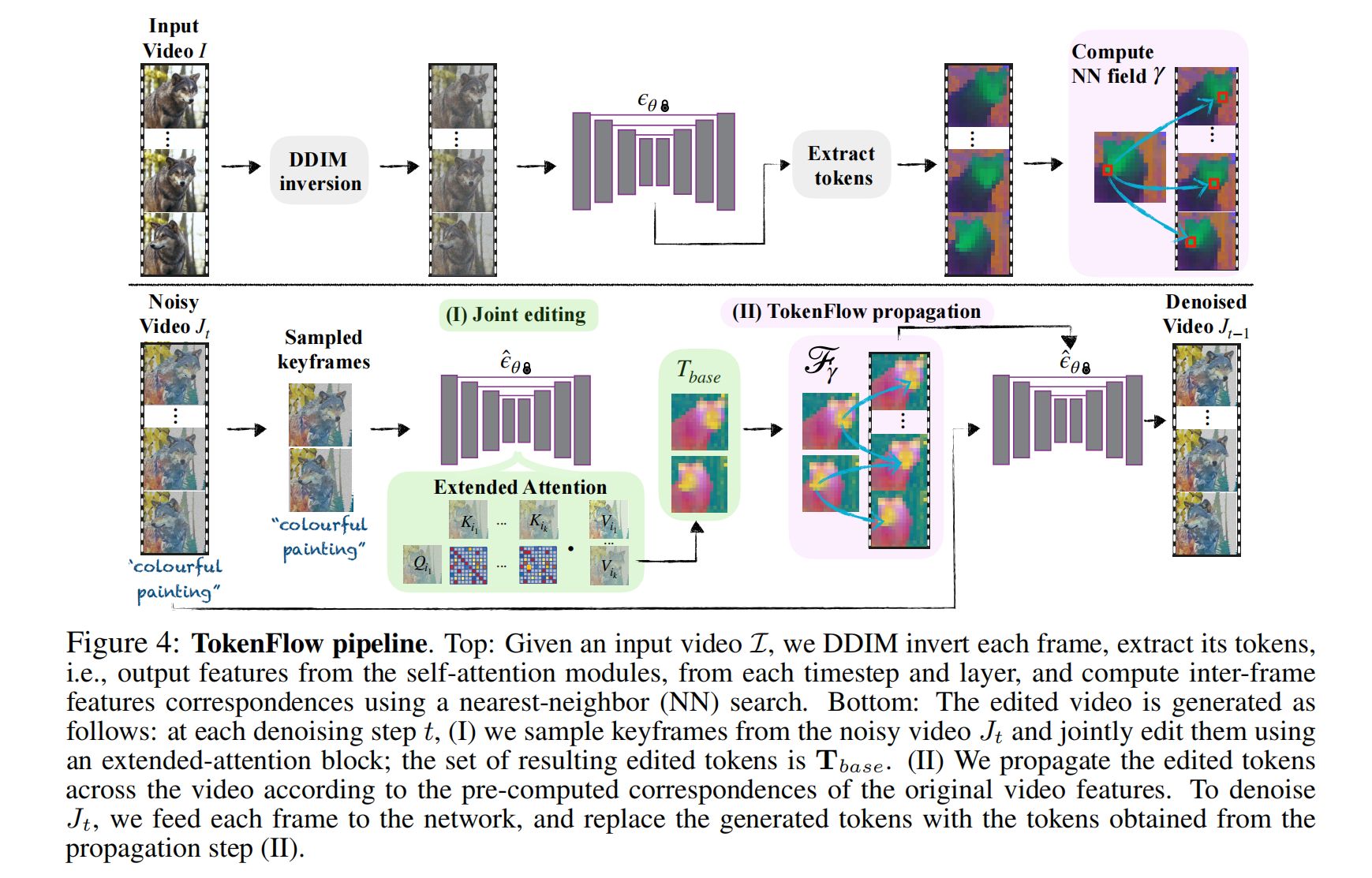
2、TokenFlow: Consistent Diffusion Features for Consistent Video Editing
方法
-
TokenFlow 是一种用于视频编辑的框架,它利用文本到图像扩散模型的能力来进行文本驱动的视频编辑。
-
该方法接受源视频和目标文本提示,生成符合目标文本的高质量视频,同时保留输入视频的空间布局和运动。
-
核心观点是通过对扩散特征空间中的一致性进行强制,可以获得编辑视频中的一致性。
-
明确地根据视频帧间的对应关系传播扩散特征,这些对应关系在模型中容易获得。
-
不需要任何训练或微调,可以与任何现成的文本到图像编辑方法结合使用。
-
通过TokenFlow技术,显著提高了由文本到图像扩散模型生成的视频中的时间一致性。
创新点
-
扩散特征的显式传播:TokenFlow通过在模型中明确传播扩散特征来保持视频帧间的一致性,而不是依赖于隐式的时间信息传播。
-
无需训练或微调:该框架可以与现成的文本到图像编辑方法结合使用,无需额外的训练或微调,提供了一种即插即用的视频编辑解决方案。
-
时间一致性的增强:通过TokenFlow技术,显著提高了视频编辑结果的时间一致性,解决了现有方法在保持视频帧间一致性方面的不足。
-
基于扩散模型的内部表示分析:研究了扩散模型内部表示中视频的属性,特别是时间冗余性,并利用这些属性来增强视频合成。
-
随机关键帧采样:在每个生成步骤中随机采样关键帧,增加了对特定选择的鲁棒性,并且由于每个生成步骤产生更一致的特征,因此下一批采样的关键帧将被更一致地编辑。
-
与图像编辑技术的无缝结合:TokenFlow可以与任何保持图像结构的扩散基础图像编辑技术结合使用,提高了视频编辑的灵活性和应用范围。
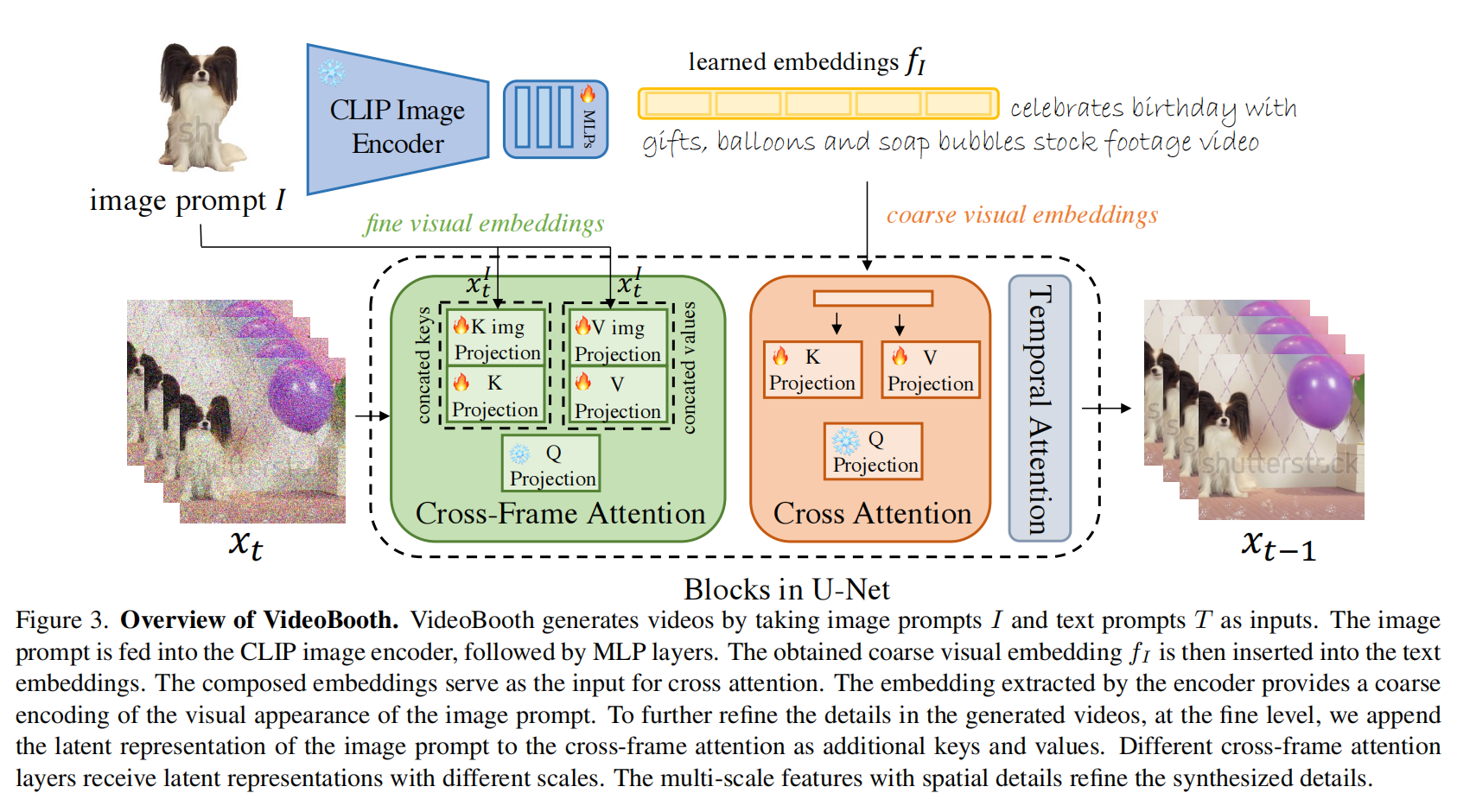
3、VideoBooth: Diffusion-based Video Generation with Image Prompts
方法
-
VideoBooth 是一个视频生成框架,它使用图像提示(image prompts)和文本提示(text prompts)生成视频。
-
该框架包含两个专门的设计:
-
以粗到细(coarse-to-fine)的方式嵌入图像提示。使用图像编码器提取图像提示的高级编码,并通过提出的注意力注入模块提供多尺度和详细的编码,以忠实捕捉所需外观。
-
在细粒度的注意力注入模块中,多尺度的图像提示被输入到不同的跨帧(cross-frame)注意力层,作为额外的键(keys)和值(values)。这些额外的空间信息可以细化第一帧的细节,并传播到其余帧中,以保持时间一致性。
-
使用预训练的CLIP模型提取图像提示的特征,并将这些特征映射到文本嵌入空间,替换原始文本嵌入的一部分。
-
为了在生成的视频中保留图像提示的视觉细节,提出了一种新颖的注意力注入方法,利用多尺度图像提示的空间信息来细化生成的细节。
-
训练策略采用粗到细的方式,首先训练图像编码器和调整交叉注意力模块的参数,然后训练注意力注入模块,以嵌入图像提示到跨帧注意力层。
创新点
-
粗到细的视觉嵌入策略:首次提出通过图像编码器和注意力注入的结合,更准确地捕捉图像提示的特征。
-
多尺度细节细化:通过在不同层级的跨帧注意力模块中注入多尺度图像提示,增强了生成视频的细节表现,并保持了时间上的连贯性。
-
无需微调的通用框架:VideoBooth 在推理时不需要微调(tuning-free),能够通过前馈传递(feed-forward passes)生成与图像提示相符的视频,这增加了模型的通用性和实用性。
-
有效的数据集构建:为了支持使用图像提示的视频生成任务,建立了专门的VideoBooth数据集,并通过数据过滤确保了数据质量。
-
跨帧注意力机制的改进:通过引入图像提示作为额外的键和值,增强了模型在时间维度上保持一致性的能力,同时能够更好地从图像提示中借用视觉线索。
-
用户研究验证:通过用户研究验证了VideoBooth在图像对齐、文本对齐和整体质量方面的优越性能,证明了其在自定义视频生成任务中的有效性。

















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









