






能源与环境领域的时空数据预测面临特征解析与参数调优双重挑战。CNN-LSTM成为突破口:CNN提取空间特征,LSTM捕捉时序依赖,实现时空数据的深度建模。但混合模型超参数(如卷积核数、LSTM层数)调优复杂,传统方法效率低且易陷局部最优。
贝叶斯优化通过概率模型与采集函数,对超参数空间进行高效全局搜索,以有限迭代逼近最优解,显著降低调优成本。二者结合后,模型既能通过分层结构解析复杂数据的时空规律,又能借助贝叶斯优化提升参数配置效率,兼顾精度与效能。
这一组合为各种场景提供新方案:架构赋能数据建模,优化破解调优难题,协同增强模型对稳态与波动数据的适应性,适配高维动态系统的预测需求。我整理了十几篇相关前沿论文,希望对大家有所帮助。
全部论文+开源代码需要的同学看文末!
【论文1 】Enhancing photovoltaic power prediction using a CNN-LSTM-attention hybrid model with Bayesian hyperparameter optimization
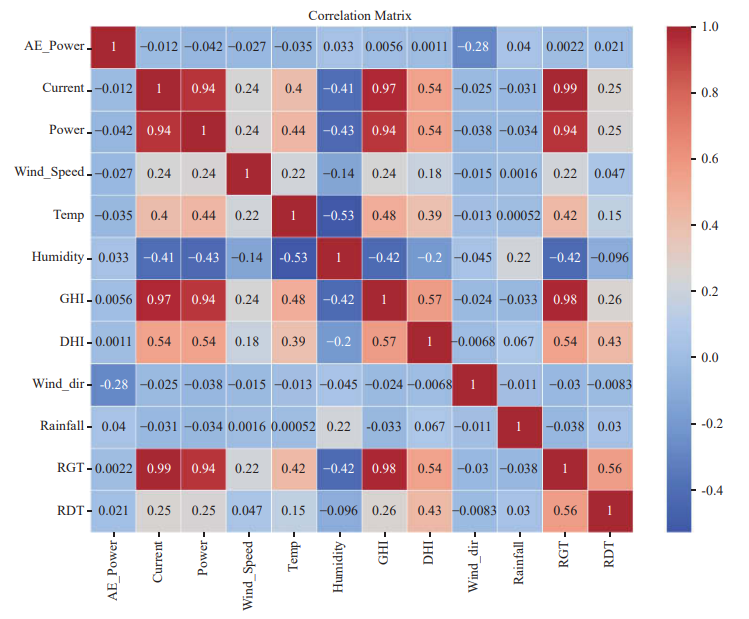
Heatmap of the correlation analysis
方法
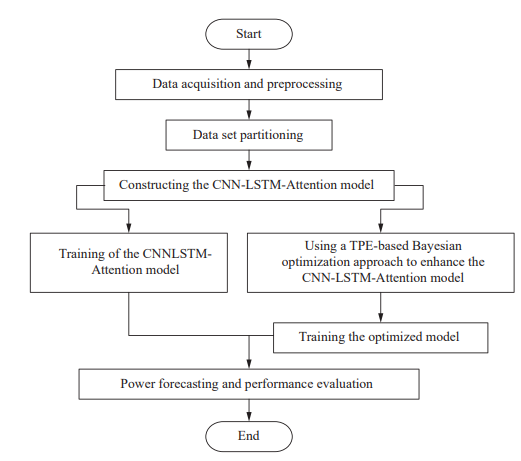
General process of the PV power prediction method
论文提出一种融合卷积神经网络(CNN)、长短期记忆网络(LSTM)和注意力机制的混合模型用于光伏功率预测,其中 CNN 提取空间特征,LSTM 捕捉时间序列依赖,注意力机制动态调整输入数据权重以突出关键信息;同时引入基于树结构 Parzen 估计(TPE)的贝叶斯优化算法,对模型超参数(如卷积核数量、LSTM 隐藏层大小等)进行自适应优化,通过概率代理模型和采集函数迭代搜索最优参数组合,以提升模型预测精度和训练效率。
创新点
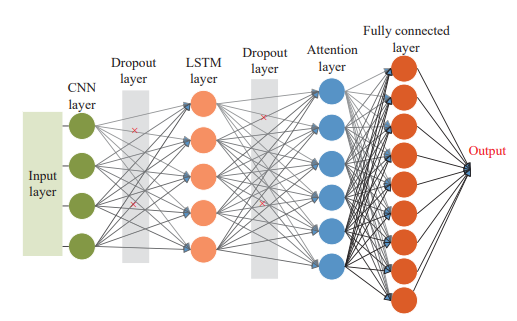
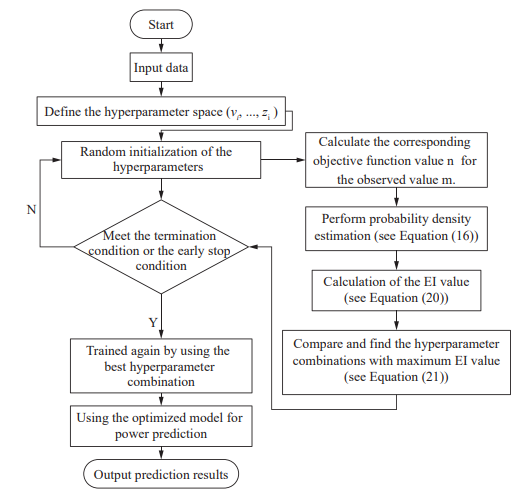
-
混合模型架构创新:构建CNN-LSTM-注意力机制的流水线式序列结构,强化CNN与LSTM的信息交互,实现光伏功率数据时空特征的深度融合提取,相比并行结构更适用于复杂时空建模问题。
-
超参数优化方法创新:采用贝叶斯优化算法替代传统网格搜索等方法,通过概率模型动态调整搜索方向,在有限迭代次数内更高效地逼近全局最优解,显著降低超参数调优的时间成本和计算复杂度。
-
预测性能提升创新:结合贝叶斯优化的混合模型在数据平稳期和波动期均表现出更高预测精度,尤其在波动场景下预测误差(如MAPE)显著降低,验证了模型对光伏功率非线性波动的鲁棒性。
论文链接:https://www.sciencedirect.com/science/article/pii/S2096511724000860
【论文2】A method for measuring carbon emissions from power plants using a CNN-LSTM-Attention model with Bayesian optimization
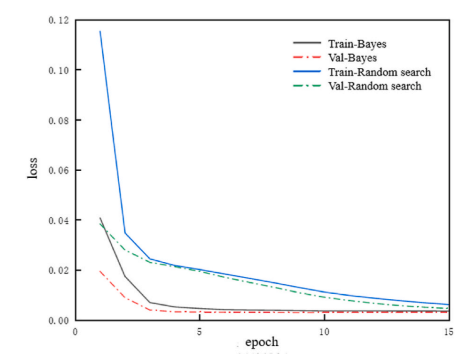
Training set versus validation set loss function curves for Bayesian optimization and random search
方法
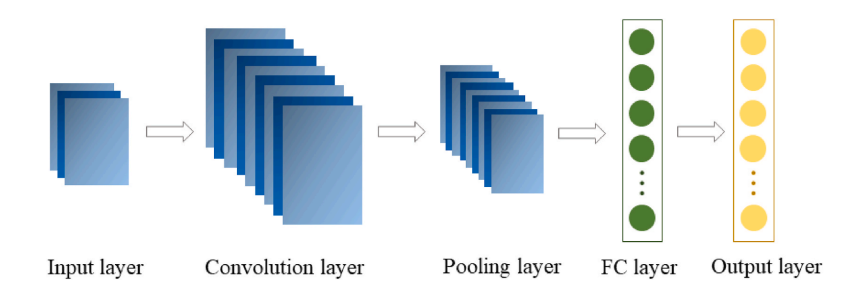
CNN neural network structure diagram.
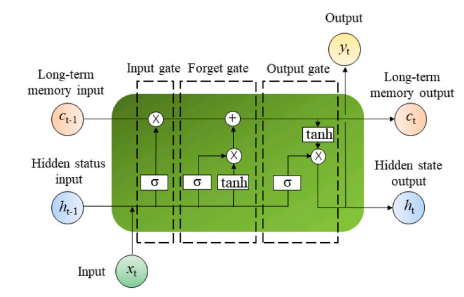
Schematic diagram of LSTM neural network.
论文提出一种融合卷积神经网络(CNN)、长短期记忆网络(LSTM)和注意力机制的混合模型用于火电厂二氧化碳(CO₂)排放测量,其中 CNN 提取多维度运行数据(如发电负荷、煤耗量等)的空间特征,LSTM 捕捉时间序列中的长期依赖关系,注意力机制动态分配时间步权重以聚焦关键特征;同时引入贝叶斯优化算法对模型超参数(如卷积核数量、LSTM 隐藏层单元数等)进行优化,通过概率代理模型和采集函数迭代搜索最优参数组合,提升模型预测精度和收敛速度。
创新点
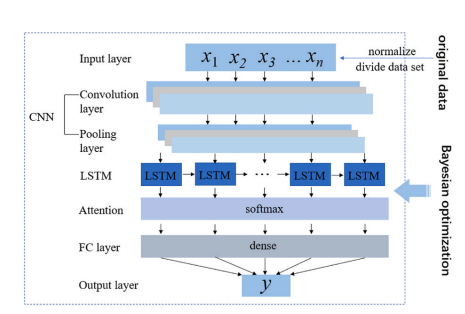
Schematic diagram of CNN-LSTM-Attention model structure.
-
多模态特征融合架构:构建CNN-LSTM-注意力机制的串行模型,利用CNN的局部特征提取能力和LSTM的时序分析能力,结合注意力机制强化关键特征权重,实现对电厂CO₂排放的时空特征联合建模,相比单一CNN或LSTM模型显著提升预测精度(R²达0.9809,RMSE低至18.039)。
-
贝叶斯优化驱动的超参数调优:采用基于梯度信息的贝叶斯优化算法替代传统随机搜索,在30轮迭代内快速定位最优超参数组合(如卷积核44个、LSTM单元64个),使模型训练损失收敛更快且泛化能力增强,相较随机搜索减少约22%-28%的预测误差。
-
动态适应与工程适用性:通过历史数据训练的模型可跨月份预测CO₂排放(如10-12月数据验证中R²均超0.93),结合电厂实时运行参数输入,提供低成本、高精度的在线碳排放测量方案,适配实际工程场景中数据波动和工况变化。
论文链接:https://www.sciencedirect.com/science/article/pii/S2214157X24013650
关注下方《AI前沿速递》🚀🚀🚀
回复“C315”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 1717
1717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









