



第三代“分割一切”模型(Segment Anything Model, SAM 3)的研究论文已匿名投稿至ICLR 2026会议并被公开。该论文目前正处于双盲评审阶段。这项工作在SAM系列模型的基础上,实现了从交互式提示到概念理解的关键性跨越。
简单来说,SAM 3能够根据用户通过自然语言短语(如“条纹猫”)或图像范例提供的“概念提示”,在图像和视频中分割出所有匹配该概念的物体实例。这一新范式极大地扩展了分割模型的应用边界。

值得注意的是,SAM 3在性能和效率上也取得了显著提升。在H200 GPU上,处理一张包含100多个物体的图像仅需30毫秒,并对视频数据具备近乎实时的处理能力。
论文标题: SAM 3: Segment Anything with Concepts
论文链接: https://openreview.net/forum?id=r35clVtGzw
从视觉提示到概念分割:任务的演进
SAM系列模型的发展历程清晰地展示了其能力的逐步演进:
- SAM 1:引入了基于点、框、掩码等视觉提示的交互式分割任务,开创了分割模型的新范式。
- SAM 2:在SAM 1的基础上,增加了对视频和记忆的支持,实现了跨帧的物体追踪。
- SAM 3:将交互式分割提升至新高度,支持基于短语、图像范例等概念提示的多实例分割。同时,它突破了前代模型一次只能处理单个实例的限制。
研究团队将SAM 3实现的新任务范式命名为可提示概念分割 (Promptable Concept Segmentation, PCS)。
PCS:可提示概念分割
PCS任务的核心定义是:给定一份图像或视频,模型能够基于文本短语、图像范例或两者的结合,分割出其中所有匹配提示概念的物体实例。 [50-51]
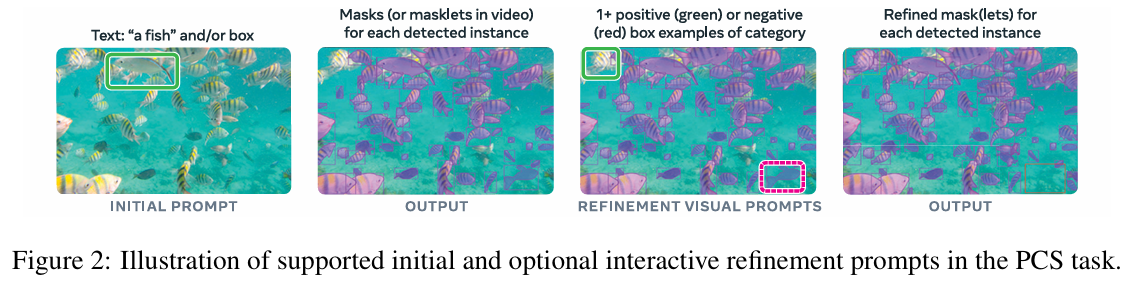
相比传统分割任务,PCS具有以下几个核心特点:
- 开放词汇能力:不局限于预定义的固定类别,支持用户输入任意名词短语作为分割目标。
- 全实例分割:找到并分割出所有符合提示的实例,并在视频中保持不同帧间目标的身份一致性。
- 多模态提示:支持文本、视觉范例以及两者结合的提示输入方式。 [50-51]
- 交互式优化:允许用户通过增加提示来对分割结果进行优化,以解决歧义或修正错误。
SAM 3 的新架构
为实现PCS任务,SAM 3设计了新的模型架构,其主要创新在于检测器与追踪器的设计。
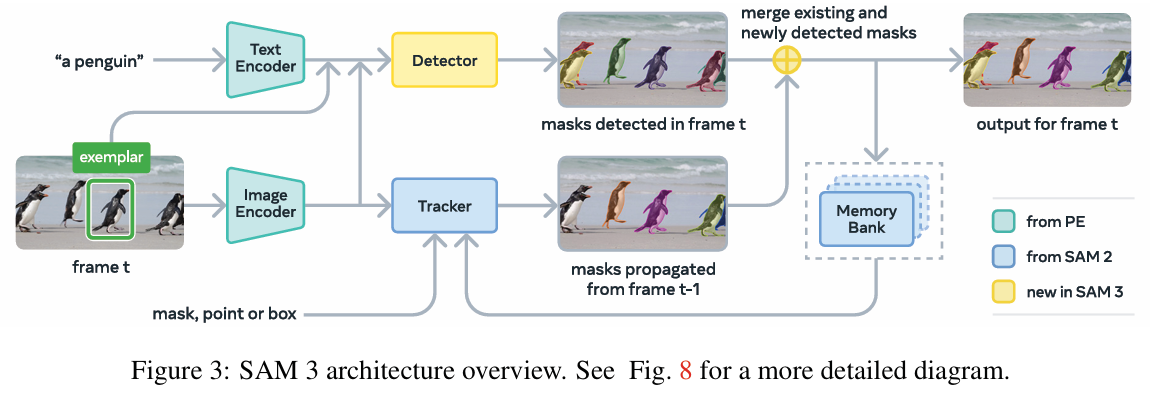
-
检测器架构:SAM 3的检测器基于DETR(Deformable Transformer)架构,能够根据语言和视觉提示生成实例级的检测结果。 [60, 140-141]
-
Presence Head模块:为了解决开放词汇检测中的挑战,SAM 3引入了Presence Head,其核心思想是解耦物体的识别(“是什么”, Recognition)和定位(“在哪里”,Localization)任务。 在传统目标检测框架中,模型需要同时判断目标是否存在及其位置,这在多实例概念分割任务中有时会产生冲突。通过解耦,SAM 3显著提升了检测精度。 [61, 162-167]
其概率分解思路如下:
p(query_i is a match | NP is present) * p(NP is present)
其中,Presence Head 负责预测概念(NP)是否存在的全局概率p(NP is present),而每个查询(query)则专注于定位问题。 [167-169] -
视频追踪架构:SAM 3的视频处理结合了检测器和一个基于记忆的追踪器。在视频的每一帧,检测器发现新目标,而追踪器则延续SAM 2的模式,负责传播和匹配已有目标的掩码。 [187-190] 通过周期性地使用高置信度的检测结果来“重新提示”(re-prompting)追踪器,确保了追踪的长期稳定性,尤其是在物体被遮挡后重新出现时。 [209-211]
大规模数据引擎与SA-Co基准
为了支持PCS任务的训练,研究团队构建了一个高效、可扩展的数据引擎,并提出了全新的评测基准。
-
数据引擎:这是一个结合了“人”与“AI模型”(包括大语言模型)的标注系统。通过AI辅助标注、AI验证,人类标注员可以专注于修正困难和模糊的案例,从而将标注吞吐量提升了一倍以上。 [9, 74-78] 最终,该引擎生成了一个庞大的数据集,包含400万个独特的概念标签和5200万个经过验证的高质量掩码。
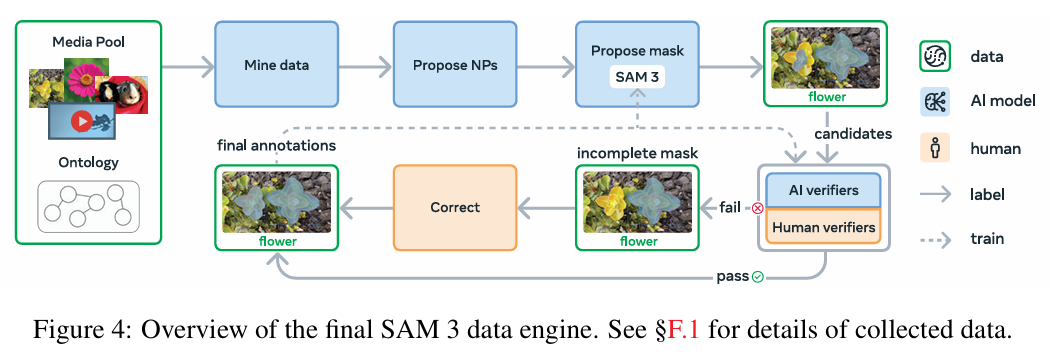
-
SA-Co基准:为了对开放词汇分割性能进行标准化评估,论文提出了SA-Co (Segment Anything with Concepts) 基准。该基准包含21.4万个独特概念、12.4万张图像和1700个视频,其概念覆盖范围是现有基准的50倍以上。
主要实验结果与局限
实验结果表明,SAM 3在多个基准上刷新了当前最佳性能(SOTA)。
- 在LVIS数据集的零样本分割任务中,SAM 3的掩码AP达到47.0,显著高于此前SOTA模型的38.5。
- 在新的SA-Co基准测试中,SAM 3的表现比基线方法至少高出2倍。 [99-100, 360]
- 在视频分割任务上,SAM 3的性能也优于SAM 2。
此外,研究人员还将SAM 3与多模态大语言模型(MLLM)结合,构建了SAM 3 Agent,以解决更复杂的分割指令,例如分割“坐着但没有拿礼物盒的人”。 MLLM负责将复杂指令分解为SAM 3可以执行的简单名词短语,并对结果进行组合。实验证明,这种组合在没有专门训练数据的情况下,其性能甚至优于专为推理分割设计的模型。 [433-435, 478-482]
局限性:
论文同样指出了SAM 3当前存在的一些不足。首先,模型对语言的理解仍局限于简单的名词短语,不具备复杂语言的理解和推理能力。 [55-56] 其次,模型零样本泛化到特定领域(如医疗影像、热成像)的能力有限。 [105, 1459-1460] 最后,在处理包含大量目标的视频时,其实时性能会下降,可能需要多GPU并行处理来维持。


















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









